深度学习与图像分类
B站链接
文章目录
-
- 1.1神经网络基础-网络结构
-
- 1全连接层:
- 2卷积层:
- 3激活函数
- 4池化层:
- 1.2神经网络基础-反向传播过程(交叉熵损失和优化器)
-
- 1误差计算:
- 2误差的反向传播:求误差对权值的偏导(求损失梯度)
- 3权重的更新:
- 4优化器:(对权重更新的方式进行优化)
- 1.3深度学习
-
- 1梯度消失和激活函数ReLU
- 2[什么是标准化(Normalization)](https://zhuanlan.zhihu.com/p/35597976)
- 3退化问题
- 4模型评估与选择
-
- K折交叉验证pytorch代码实现
- 训练集和测试集的划分
- 5BatchSize对于训练的影响
- 6迁移学习
- 2、LeNet
- 3、AlexNet
- 4、VGG
- 5、GoogLeNet
- 6、ResNet
- 7、MobileNet
1.1神经网络基础-网络结构
1全连接层:
BP神经网络-信号向前传播,误差的反向传播 one-hot编码
2卷积层:
卷积特性局部感知机制、权值共享,目的是进行图像特征的提取,通过训练卷积核和偏差
特征:#每一个卷积核的channel与输入特征层的channel相同(例如:5*5的RGB图像有3个输入层,每个卷积核也应该有三个channel与之分别对应),该卷积核的各个channel分别和对应channel的输入层卷积,然后再求和得到一个特征矩阵作为深度学习图像的输出,作为下一层输入特征的一个channel向前传播。
#输出特征矩阵channel数与卷积核个数相同。
3激活函数
目的:计算过程本身是线性的,引入非线性因素,使其具备解决非线性问题的能力。
sigmoid-层数较深时,容易出现梯度消失;relu-当反向传播过程中有一个非常大的梯度经过时,更新后可能导致权重分布中心小于零,导致该处导数始终为0,反向传播无法更新权重,神经元失活状态。
卷积后矩阵尺寸计算公式 :w=(W-F+2P)/S+1
4池化层:
MaxPooling下采样-目的是对特征图进行稀疏处理、减少数据的运算量。
AveragePooling下采样层
特点:#无训练参数#只改变特征矩阵的W和H,不改变深度(channel数)#一般poolsize和步距stride相同
5SoftMax层
经过处理后所有节点的概率和为1 公式:Oi = exp(y1)/∑exp(yi)
1.2神经网络基础-反向传播过程(交叉熵损失和优化器)
目的是为了利用损失梯度,更新每一层的权值和偏差
1误差计算:
#交叉熵损失CrossEntropy Loss:是对样本的似然函数求极大值的过程中,推导到对一个函数求极小值,令这个函数为交叉熵函数。(最大似然估计的目的就是:利用已知的样本结果,反推最有可能导致这样结果的参数值。)
logistic regression-二分类,反映了两个分布(groudtruth和output的分布)的偏离程度,优化目的是逼近两个分布。
针对多分类问题(输出只属于一个类别),CrossEntropy_Loss=函数1。
针对二分类问题(输出可能归于多个类别),CrossEntropy_Loss=函数2。

2误差的反向传播:求误差对权值的偏导(求损失梯度)
计算一批(batch_size)图片的平均损失梯度?


3权重的更新:

若使用整个样本集进行求解,损失梯度指向全局最优方向。但是实际应用中往往不可能一次性将所有数据载入内存,所以只能分批训练。若使用分批次样本求解,损失梯度指向当前批次最优方向,且速度较慢。
4优化器:(对权重更新的方式进行优化)
TIPS for GD:
1、Adagrad:训练初始阶段学习率较大,随后越来越小。
2、mini-batch SGD:GD求出的loss是所有样本的误差平方和,而SGD求出的loss是mini-batch个样本的误差平方和。可加快训练速度
3、feature scaling-normalization,让不同的特征进行z-score标准化
目的-使网络更快收敛
SGD:速度较慢

为了解决陷入局部最优及易受样本干扰的问题,引入了Momentum,该方法考虑了把上一次的梯度也考虑进来
Mini-Batch SGD相对于One Example SGD的两个优势:梯度更新方向更准确;并行计算速度快;
SGD+Momentum:
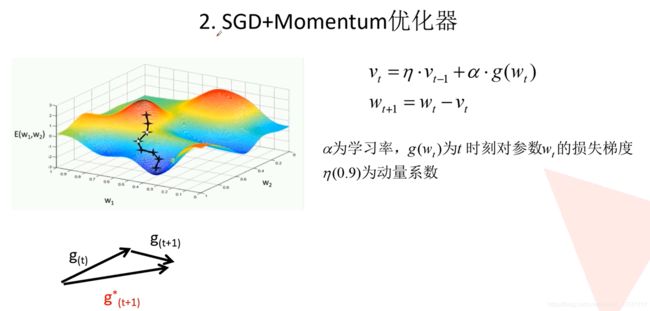
自适应学习率的优化器:
**Adagrad:*学习率越来越小,分母是“每次梯度的和开根号”

缺点是学习率下降的太快,可能还没收敛就停止训练了。
RMSProp:是建立在Adagrad的基础上的,增加了两个系数,可以控制学习率的衰减速度

Adam优化器:二级动量
 常用SGD*SGD+Momentum\Adam
常用SGD*SGD+Momentum\Adam
关于深度学习训练过程的优化:优化入门(SGD、动量(Momentum)、AdaGrad、RMSProp、Adam详解) (未读)
如果网络结构过于复杂,容易过拟合,所以需要添加下采样层(max_pooling\ave_pooling)
1.3深度学习
1梯度消失和激活函数ReLU
梯度消失、爆炸原因及其解决方法
2什么是标准化(Normalization)


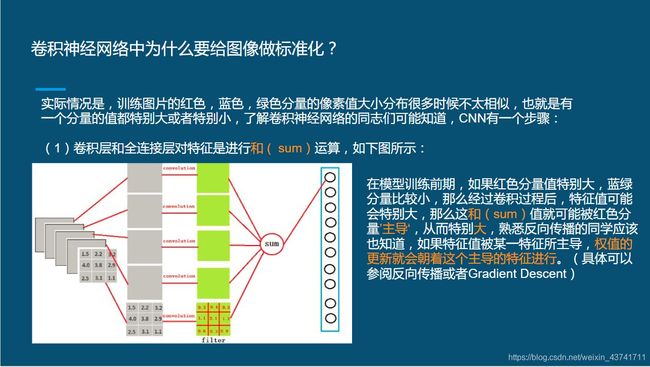

Batch Normalization(批量归一化)
正则化(weight Decay)、参数范数惩罚L0、L1、L2、Dropout、早停
3退化问题
4模型评估与选择
李宏毅DNN-tips:
如果网络在训练集上的误差较大,属于欠拟合,解决思路如下:
1、更换激励函数ReLU
2、调整网络结构
3、更换loss_function类型
4、调整学习率(每种优化方法都可以调学习率)
5、改变优化方法(选择SGD+Momentum 或者 自适应学习率方法:Adam Adagrad RMSProp等)
6、调整训练参数(batch_size epochs等)
如果网络在训练集上的误差较小,但是在测试集上的误差较大(泛化性能差),属于过拟合,解决思路如下:
1、降低参数空间维度,使模型稀疏。(Dropout)
2、降低每个参数的有效规模,使参数值减小。(正则化)
3、早停法
K折交叉验证pytorch代码实现
训练集train由D变成了K*D,有效的避免过拟合以及欠拟合状态的发生。
1、Dive-into-DL-Pytorch p111
K折交叉验证法原理及python实现
pytorch - K折交叉验证过程说明及实现
Pytorch实现k折交叉验证
训练集和测试集的划分
训练集和测试集 (Training and Test Sets):拆分数据
数据集的划分–训练集、验证集和测试集
python划分训练集、验证集和测试集
python划分训练集和测试集
老师的ppt:
西瓜书:
经验误差与过拟合:
评估方法:
留出法 交叉验证法-N-fold validation(10次10折交叉验证最常用-10次随机划分,每次分十份,对这10次10折验证(10折验证的结果是对每折的验证求均值)求均值)自助法
性能量度:
查准率(precision真正例占所有预测出的正例的比例)、查全率(recall真正例占groundtruth中所有正例的比例),混淆矩阵(TP-true positive)、P-R曲线、平衡点、F1度量。
确定超参数-决定网络模型的参数(model selection)
代价敏感错误率
5BatchSize对于训练的影响
实验讨论BatchSize对于精度的影响、对于训练时间的影响、对于BN的影响、与学习率的关系(随着BatchSize的增大,观察上述各项指标)
深度学习中的batch的大小对学习效果有何影响?
如何调参?(卷积层结构设计 全连接层结构设计 下采样方式(Dropout BN avgpool maxpool)权值初始化方式 BatchSize epochs lr loss_function optimizer)
可以读一读花书和这方面的论文
6迁移学习
迁移学习综述
Everything about Transfer Learning and Domain Adaptation–迁移学习-应有尽有
迁移学习的十个问题
2、LeNet
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
两层卷积,两层下采样,三层全连接层
Q1:如何通过调整网络(增加深度、宽度或者轻量化)提高模型精度?
Q2:如何设置训练参数(batch_size(训练集、验证集)、epochs、optimizer(类型、lr))及验证方式,来提高准确率及模型效率?
LeNet-5
3、AlexNet
1、为什么想到用deep cnn
2、为什么想到relu激活函数
LRN层:对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。LRN(Local Response Normalization) 局部响应归一化

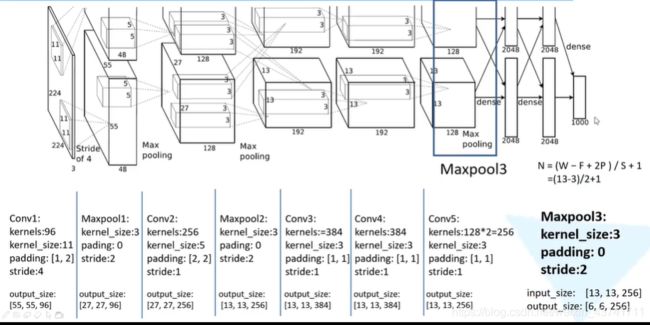


4、VGG
Q&A:
Q1:为什么可以用多个小尺度的卷积核代替大尺度卷积核?
Creative Reading:
Q1:为什么想到用多个小尺度卷积核代替大尺度卷积核?
网络结构及其亮点:

感受野概念:
经过3层[3,3]的卷积核的输出map中的一个特征点,对应的输入的感受野为7X7
经过1层[7,7]的卷积核的输出map中的一个特征点,对应的输入的感受野也为7X7
由于感受野相同,因此可以通过堆叠多个小的卷积核代替大的卷积核可以减少参数量。(3个3X3的卷积核代替1个7X7的卷积核,2个3X3的卷积核代替1个5X5的卷积核)例如:kernel_num=10,3层[3,3]的卷积核的参数:3X3X3X10=270,1层[7,7]的卷积核的参数:7X7X1X10=490




VGG16最常用:
利用卷积层提取特征
利用全连接层、softmax层进行分类

5、GoogLeNet
Q&A:
Q1:inception结构(加宽、两层卷积)对训练结果有什么帮助?
Q2:为什么设置辅助分类器?辅助分类器的位置为什么是4a\4d层?
Q3:为什么分类前用平均池化?
Q4:第一层为什么使用7x7的卷积核,急剧地降低特征维度?
Creative Reading:
Q1:为什么想到设计Inception结构,以及辅助分类器?
21层

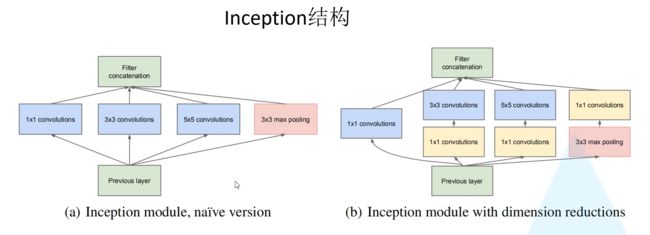
Inception结构要保证各个分支输出的高、宽相同(通过控制Padding的大小),然后才能进行深度拼接
解释了如何利用1*1的卷积核进行降维
辅助分类器的输入、结构和输出
网络结构:



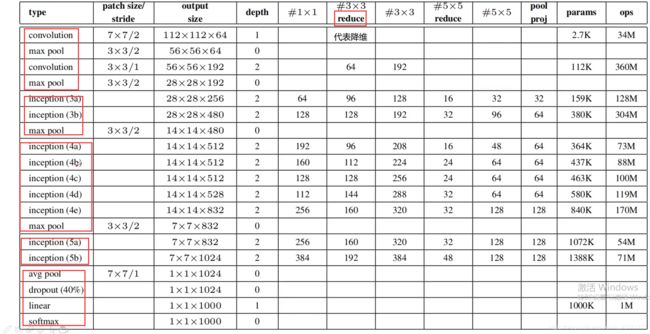
GoogleNet模型参数比VGG更少、精度更高,但是为什么更多的使用VGG16而不是GoogleNet?
可能原因为GoogleNet有两个辅助分类器,训练和修改比较复杂,而VGG搭建更方便。
6、ResNet
Q1: 网络层数加深,如何解决前层网络的梯度消失和梯度爆炸问题?
Q2:为什么设计残差结构,shortcut结构堆叠的好处?
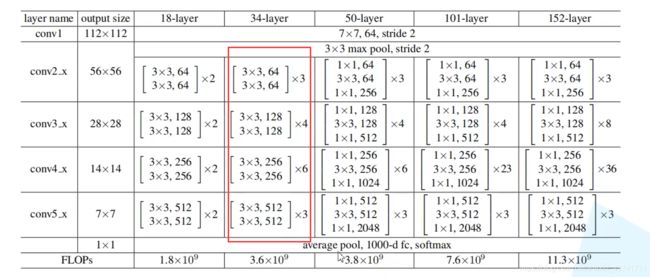
Q3:如何把这些残差结构组合起来构建深层网络?
Q4:为什么设计两种OptionA/OptionB两种残差结构,之间的区别?
BasicBlock:
BottleNeck:



BN:
均值和方差的计算
卷积层不用设置bias,即bias=False

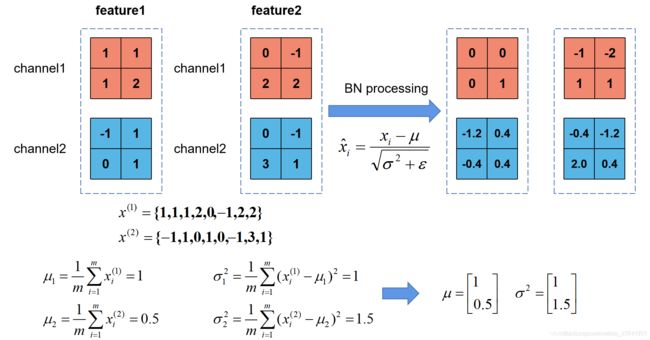


Batch Normalization详解
李宏毅batch normalization
Internal Covariate Shift与Normalization
BN与“Internal Covariate Shift”问题
ML_IID假设
在训练过程中,随着网络加深,分布逐渐发生变动,导致整体分布逐渐往激活函数的饱和区间移动,从而反向传播时底层出现梯度消失,也就是收敛越来越慢的原因。
标准化其实就是把大部分激活的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
如果使用标准化,那就相当于把非线性激活函数替换成线性函数了。那么使用非线性激活的意义在哪里呢,多层线性网络跟一层线性网络是等价的,也就是网络的表达能力下降了。
为了保证非线性表达能力,后面又对此打了个补丁,对变换后的满足均值为0方差为1的x进行了scale加上shift操作,形成类似y=scale∗x+shift 这种形式,参数通过训练进行学习,把标准正态分布左移或者右移一点,并且长胖一点或者变瘦一点,将分布从线性区往非线性区稍微移动,希望找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力,又能够享受线性区较大的下降梯度。
迁移学习:
![]()

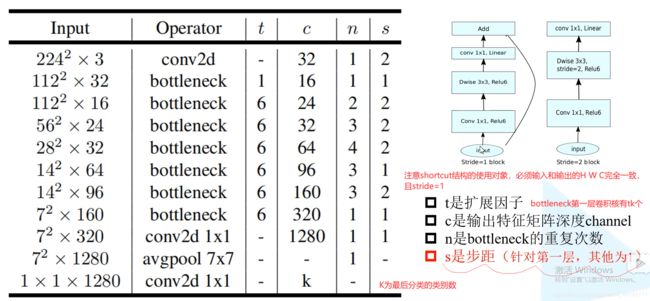
7、MobileNet
深度可分卷积(depthwise separable conv):包括DW Conv和PW Conv
DW-depthwise conv深度卷积:每个卷积核的channel(深度)=1,输入特征矩阵channel=卷积核个数=输出特征矩阵channel
Pointwise Conv逐点卷积,普通卷积,只是kernel_size=1
相当于把普通卷积拆成两步,先进行DW再进行PW
超参数是人为设定的,α-控制卷积核个数,β-控制输入图像分辨率大小
性能对比:
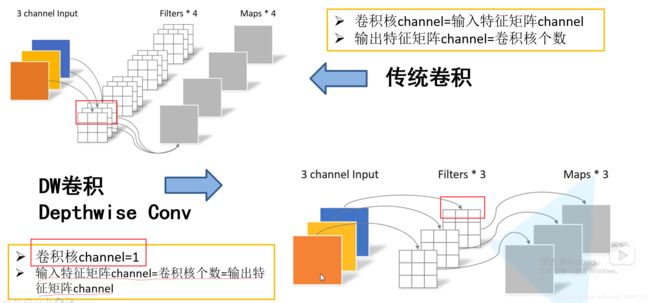
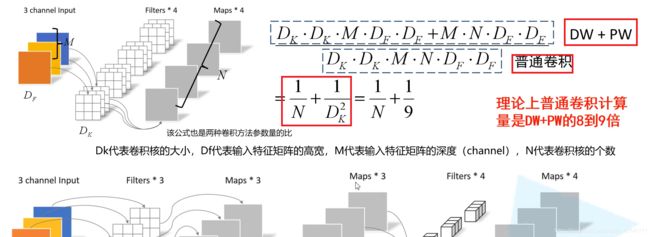
MobileNetV1:
网络结构:

MobileNetV2:
inverted residuals
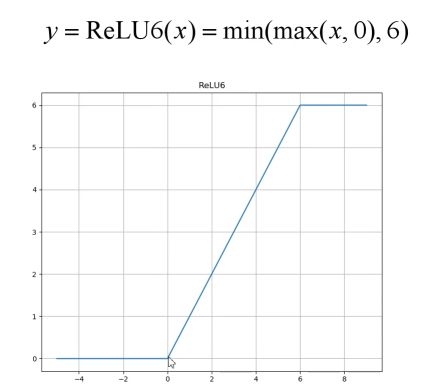
relu6
bottleneck block
MobileNetV2网络结构: