机器学习预测实战 -- 信用卡交易欺诈数据监测(含方案和代码思路)
目录
项目背景
目标
方案一:下采样的方法训练模型
获取数据
数据预处理
检查是否有缺失值:
查看数据类型:
查看数据分布
方案二:smote(过采样)处理数据不平衡数据
获取数据
数据预处理
检查是否有缺失值:
查看数据类型:
不平衡数据处理
方法一:直接使用smote
方法二:利用SMOTE+undersampling解决数据不平衡
分割数据集:
方法1的数据集
方法2的数据集
模型训练
准备好算法API
交叉验证的函数
模型调优
网格搜索模型调优
计算各个指标:
集成算法
保存模型:
项目背景
一批交易数据,数据总量28万,其中正常交易数据量占比99.83%,欺诈交易数据量仅占比0.17%。
目标
训练出一个模型,能判断出交易数据是正常数据还是欺诈数据
方案一:下采样的方法训练模型
获取数据
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')
# 加载数据文件
df = pd.read_csv("creditcard.csv")
# 查看数据内容
df.head()
上图可以看到,数据除了Amount外,都经过了标准化处理
数据预处理
检查是否有缺失值:
# 检查是否有空置
df.isnull().sum()
没有缺失值的情况
查看数据类型:
# 查看数据类型
df.dtypes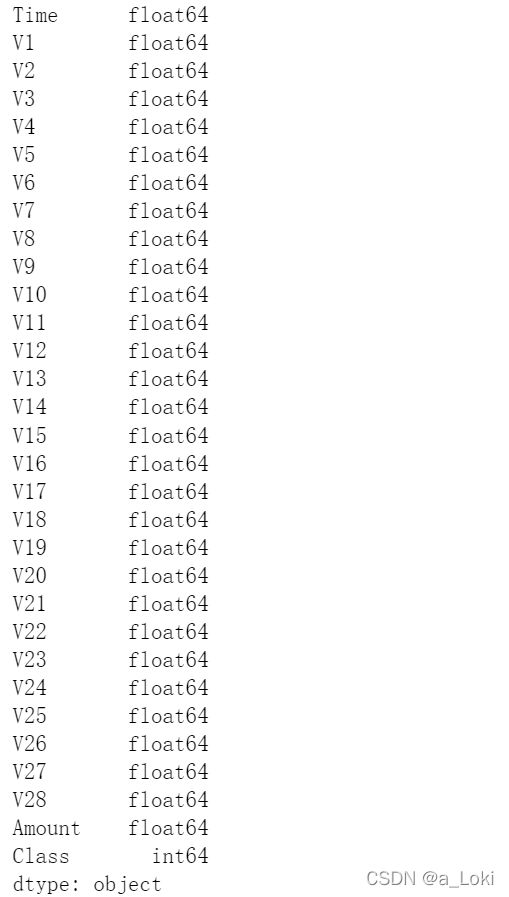
查看数据分布
# 查看Class分布
labels = ['Not Fraud', 'Fraud'] # 标签
size = df['Class'].value_counts() # 统计class的类别数量
colors = ['lightgreen', 'orange'] # 颜色
explode = [0, 0.1] # 饼图突出
plt.figure(figsize=(9,9)) # 画布大小
plt.pie(size, colors=colors, explode=explode, labels=labels, shadow=True, autopct='%.2f%%') # 饼图参数设置
plt.axis('off') # 关闭坐标轴
plt.title("Data Distribution") # 标题
plt.legend() # 显示标签
plt.show() # 显示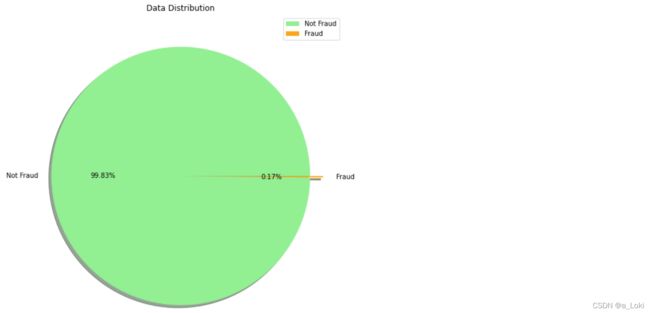
这里可以看到欺诈数据占比非常小,如果使用下采样的方法训练模型,有非常大的概率出现过拟合的现象,导致模型泛化能力差,这时候第一个方案可以停下。
方案二:smote(过采样)处理数据不平衡数据
如果不处理不平衡数据,用这些数据来训练,模型往往只会学到分辨样本多的类别,而少数类别因为学习的数据量过少,无法准确预测。
获取数据
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')
# 加载数据文件
df = pd.read_csv("creditcard.csv")
# 查看数据内容
df.head()
上图可以看到,数据除了Amount外,都经过了标准化处理
数据预处理
对Amount进行标准化处理
from sklearn.preprocessing import StandardScaler
df['scaled_amount'] = StandardScaler().fit_transform(df['Amount'].values.reshape(-1,1)) # 金额归一化
df['scaled_time'] = StandardScaler().fit_transform(df['Time'].values.reshape(-1,1)) # 时间归一化
df.drop(['Amount', 'Time'], axis=1, inplace=True) # 删除原始的数据列检查是否有缺失值:
# 检查是否有空置
df.isnull().sum()
没有缺失值的情况
查看数据类型:
# 查看数据类型
df.dtypes
不平衡数据处理
这里我们提出一个想法,不管是对数据进行过采样还是欠采样,都是去平衡两类数据,那么我们可以尝试在用单纯的smote的同时,再创建一组数据集,对少数样本过采样,多数样本下采样,分别训练,查看效果。
方法一:直接使用smote
from imblearn.over_sampling import SMOTE
X_new_1, y_new_1 = SMOTE().fit_resample(X, y)
# 新的类分布
y_new_1.value_counts()

方法二:利用SMOTE+undersampling解决数据不平衡
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
from imblearn.pipeline import Pipeline # 管道,把要用的工具封装在一起
# over
over = SMOTE(sampling_strategy=0.1)
# under
under = RandomUnderSampler(sampling_strategy=0.5)
# pipeline
steps = [('o', over),('u', under)]
pipeline = Pipeline(steps=steps)
X_new_2, y_new_2 = pipeline.fit_resample(X, y)
# 新的类分布
y_new_2.value_counts()
分割数据集:
方法1的数据集
from sklearn.model_selection import train_test_split
X_new_1_train, X_new_1_test, y_new_1_train, y_new_1_test = train_test_split(X_new_1, y_new_1)
# 数据集
X_new_1_train = X_new_1_train.values
X_new_1_test = X_new_1_test.values
# 标签
y_new_1_train = y_new_1_train.values
y_new_1_test = y_new_1_test.values方法2的数据集
X_new_2_train, X_new_2_test, y_new_2_train, y_new_2_test = train_test_split(X_new_2, y_new_2)
# 数据集
X_new_2_train = X_new_2_train.values
X_new_2_test = X_new_2_test.values
# 标签
y_new_2_train = y_new_2_train.values
y_new_2_test = y_new_2_test.values模型训练
因为我们处理的是一个二分类问题,这里选择的二分类中表现较好的逻辑回归,还有强大的SVM,以及各种集成算法来训练模型。利用交叉验证和网格搜索,从中选择出最优的模型和最优的参数,
准备好算法API
# 简单分类器实现
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.linear_model import SGDClassifier # 随机梯度
from sklearn.svm import SVC # 支撑向量机
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.model_selection import cross_val_score # 交叉验证计算accuracy
from sklearn.model_selection import GridSearchCV # 网格搜索,获取最优参数
from sklearn.model_selection import StratifiedKFold # 交叉验证
from collections import Counter
# 评估指标
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, roc_auc_score, accuracy_score, classification_report
from sklearn.ensemble import BaggingClassifier, GradientBoostingClassifier # 集成学习
from xgboost import XGBClassifier # 极限梯度提升树
classifiers = {
'LogisticRegression':LogisticRegression(), # 逻辑回归
# "SVC":SVC(), # 支撑向量机
'RFC':RandomForestClassifier(), # 随机森林
'Bagging':BaggingClassifier(), # 集成学习bagging
'SGD':SGDClassifier(), # 随机梯度
'GBC':GradientBoostingClassifier(), # 集成学习Gradient
'xgb':XGBClassifier() # 极限梯度提升树
}交叉验证的函数
def accuracy_score(X_train, y_train):
for key, classifier in classifiers.items(): # 遍历每一个分类器,分别训练、计算得分
classifier.fit(X_train, y_train)
training_score = cross_val_score(classifier, X_train, y_train, cv=5) # 5折交叉验证
print("Classifier Name : ", classifier.__class__.__name__," Training Score :", round(training_score.mean(), 2)*100,'%')结果1
# 1.1 SMOTE
accuracy_score(X_new_1_train, y_new_1_train)
这里SVM算法也会消耗大量的时间,这里我把它pass掉了
结果2
# 1.2 SMOTE + under sampling
accuracy_score(X_new_2_train, y_new_2_train)
这里两种方法的结果都还不错,继续往下调优,然后我们可以看到的是,一些集成算法出现过拟合的现象,所以我们调优方向可以往降低模型复杂度这边走
模型调优
网格搜索模型调优
# 网格搜索:获取最优超参数
# 1 LR
def LR_gs(X_train, y_train):
# LR
LR_param = {
'penalty':['l1', 'l2'],
'C':[0.001, 0.01, 0.1, 1, 10]
}
LR_gs = GridSearchCV(LogisticRegression(),param_grid=LR_param, n_jobs=-1, scoring='accuracy')
LR_gs.fit(X_train, y_train)
LR_estimators = LR_gs.best_estimator_ # 最优参数
return LR_estimators
# 2 RFC
def RFC_gs(X_train, y_train):
RFC_param = {
'n_estimators':[100, 150, 200], # 多少棵树
'criterion':['gini', 'entropy'], # 衡量标准
'max_depth':list(range(2,5,1)), # 树的深度
}
RFC_gs = GridSearchCV(RandomForestClassifier(), param_grid=RFC_param, n_jobs=-1, scoring='accuracy')
RFC_gs.fit(X_train, y_train)
RFC_estimators = RFC_gs.best_estimator_
return RFC_estimators
# 3 Bag
def BAG_gs(X_train, y_train):
BAG_param = {
'n_estimators':[10, 15, 20]
}
BAG_gs = GridSearchCV(BaggingClassifier(), param_grid=BAG_param, n_jobs=-1, scoring='accuracy')
BAG_gs.fit(X_train, y_train)
BAG_estimators = BAG_gs.best_estimator_
return BAG_estimators
# 4 SGD
def SGD_gs(X_train, y_train):
SGD_param = {
'penalty':['l2','l1'],
'max_iter':[1000, 1500, 2000]
}
SGD_gs = GridSearchCV(SGDClassifier(), param_grid=SGD_param, n_jobs=-1, scoring='accuracy')
SGD_gs.fit(X_train, y_train)
SGD_estimators = SGD_gs.best_estimator_
return SGD_estimators
# 5 xgb
def XGB_gs(X_train, y_train):
XGB_param = {
'n_estimators':[60,80,100,200],
'max_depth':[3,4,5,6],
'learning_rate':[0.1,0.2,0.3,0.4]
}
XGB_gs = GridSearchCV(XGBClassifier(), param_grid=XGB_param, n_jobs=-1, scoring='accuracy')
XGB_gs.fit(X_train, y_train)
XGB_estimators = XGB_gs.best_estimator_
return XGB_estimators
调用上面的函数:
# 采用新的数据集:X_new_1_train, y_new_1_train
# 模型交叉验证、训练,获取最优超参数
LR_best_estimator = LR_gs(X_new_1_train, y_new_1_train)
# KNN_best_estimator = KNN_gs(X_new_1_train, y_new_1_train)
# SVC_best_estimator = SVC_gs(X_new_1_train, y_new_1_train)
# DT_best_estimator = DT_gs(X_new_1_train, y_new_1_train)
RFC_best_estimator = RFC_gs(X_new_1_train, y_new_1_train)
BAG_best_estimator = BAG_gs(X_new_1_train, y_new_1_train)
SGD_best_estimator = SGD_gs(X_new_1_train, y_new_1_train)
XGB_best_estimator = XGB_gs(X_new_1_train, y_new_1_train)注:这一步在我电脑计算了三个多小时
# 采用新的数据集:X_new_2_train, y_new_2_train
# 模型交叉验证、训练,获取最优超参数
LR_best_estimator = LR_gs(X_new_2_train, y_new_2_train)
# KNN_best_estimator = KNN_gs(X_new_2_train, y_new_2_train)
# SVC_best_estimator = SVC_gs(X_new_2_train, y_new_2_train)
# DT_best_estimator = DT_gs(X_new_2_train, y_new_2_train)
RFC_best_estimator = RFC_gs(X_new_2_train, y_new_2_train)
BAG_best_estimator = BAG_gs(X_new_2_train, y_new_2_train)
SGD_best_estimator = SGD_gs(X_new_2_train, y_new_2_train)
XGB_best_estimator = XGB_gs(X_new_2_train, y_new_2_train)等以上步骤都计算完成,我们就得到了网格搜索找出的最优超参数,利用得到的最优超参数,去计算准确率,精准率,召回率,f1_score,auc面积。
计算各个指标:
(这个模型我们主要是为了检测异常数据,也就是找到少数类,所以我们更看重数据查的全不全,也就是召回率和AUC指标)
# 预测新的数据集:X_new_test, y_new_test
from sklearn.metrics import precision_recall_fscore_support
from sklearn.metrics import accuracy_score
result_df = pd.DataFrame(columns=['Accuracy', 'F1-score', 'Recall', 'Precision', 'AUC_ROC'],
index=['LR','RFC','Bagging','SGD','XGB'])
def caculate(models, X_test, y_test):
# 计算各种参数的值
accuracy_results = []
F1_score_results = []
Recall_results = []
Precision_results = []
AUC_ROC_results = []
for model in models:
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred) # 计算准确度
precision, recall, f1_score, _ = precision_recall_fscore_support(y_test, y_pred) # 计算:精确度,召回率,f1_score
AUC_ROC = roc_auc_score(y_test, y_pred) # 计算ROC, AUC
# 保存计算值
accuracy_results.append(accuracy)
F1_score_results.append(f1_score)
Recall_results.append(recall)
AUC_ROC_results.append(AUC_ROC)
Precision_results.append(precision)
return accuracy_results, F1_score_results, Recall_results, AUC_ROC_results, Precision_results带入数据1
# 将所有最优超参数的模型放在一起
best_models = [LR_best_estimator, RFC_best_estimator,
BAG_best_estimator, SGD_best_estimator, XGB_best_estimator]
# 调用函数计算各项指标值
accuracy_results, F1_score_results, Recall_results, AUC_ROC_results, Precision_results = caculate(best_models, X_new_1_test, y_new_1_test)
# 将各项值放入到DataFrame中
result_df['Accuracy'] = accuracy_results
result_df['F1-score'] = F1_score_results
result_df['Recall'] = Recall_results
result_df['Precision'] = Precision_results
result_df['AUC_ROC'] = AUC_ROC_results
result_df # 显示计算结果
可视化:
# 可视化 AUC的评分
g = sns.barplot('AUC_ROC', result_df.index, data=result_df, palette='hsv', orient='h') 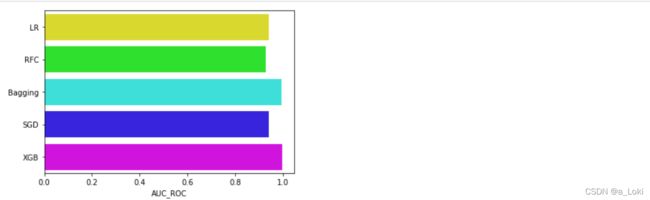
带入第二组数据:
result_df_2 = pd.DataFrame(columns=['Accuracy', 'F1-score', 'Recall', 'Precision', 'AUC_ROC'],
index=['LR','RFC','Bagging','SGD','XGB'])
# 将所有最优超参数的模型放在一起
best_models = [LR_best_estimator, RFC_best_estimator,
BAG_best_estimator, SGD_best_estimator, XGB_best_estimator]
# 调用函数计算各项指标值
accuracy_results, F1_score_results, Recall_results, AUC_ROC_results, Precision_results = caculate(best_models, X_new_2_test, y_new_2_test)
# 将各项值放入到DataFrame中
result_df_2['Accuracy'] = accuracy_results
result_df_2['F1-score'] = F1_score_results
result_df_2['Recall'] = Recall_results
result_df_2['Precision'] = Precision_results
result_df_2['AUC_ROC'] = AUC_ROC_results
result_df_2

可视化:
# 可视化 AUC的评分
g = sns.barplot('AUC_ROC', result_df_2.index, data=result_df_2, palette='hsv', orient='h')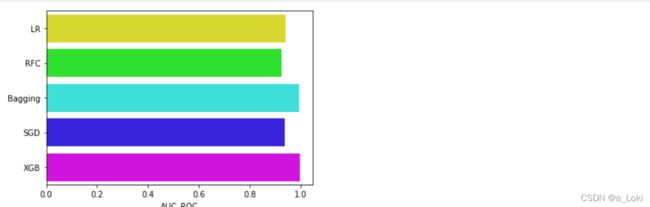
看到auc面积这里,第二组数据的结果会略微高于第一组数据,这时候我们后续可以只使用第二组数据。
到这里我们可以看到,Bagging和XGBoost都有较好的表现效果,我们选出这两个算法,对它们进行一个集成,集成为一个算法,看看能不能得到更优的效果。
集成算法
# 集成学习
# 根据以上AUC的结果,选择: LR 和 SVC 和 XGB 当做基模型
# KNN_test = pd.Series(KNN_best_estimator.predict(X_new_1_test), name = 'KNN')
Bagging_test = pd.Series(BAG_best_estimator.predict(X_new_1_test),name = 'Bagging')
XGB_test = pd.Series(XGB_best_estimator.predict(X_new_1_test), name='XGB')
# 把以上3个模型的预测结果集成起来
ensemble_results = pd.concat([Bagging_test, XGB_test], axis=1)
ensemble_results

集成,训练:
# 将上述3个模型集成起来,当做一个模型
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[('BAG', BAG_best_estimator),
('XGB', XGB_best_estimator)], n_jobs=-1)
# 训练
voting_clf.fit(X_new_1_train, y_new_1_train)
# 预测
y_final_pred = voting_clf.predict(X_new_1_test)
# 评估结果 : 最终集成学习预测的结果明显高于之前各个模型单独预测的结果
print(classification_report(y_new_1_test, y_final_pred)) 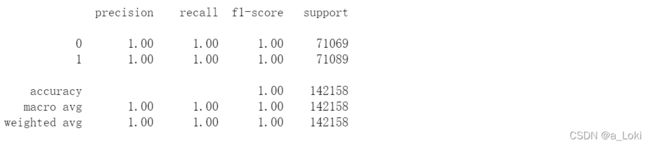
可以看到我们最终集成的模型预测的结果明显高于单独预测的结果,然后我们把这个超级模型保存起来:
保存模型:
import pickle
pickle.dump(voting_clf,open('./bag_xgb.dat','wb'))
后续也可以绘制一下ROC曲线,这里我觉得没必要了。over!