【机器学习(四)】决策树、ID3算法、C4.5算法、CART算法:原理,案例和代码
目录
1.引言
2.决策树
2.1 决策树与if-then规则
2.2 决策树与条件概率分布
2.3 决策树学习
3.特征选择
4.决策树生成
4.1 ID3生成算法
4.2 C4.5生成算法
5.决策树剪枝
5.1剪枝算法
6.CART算法
6.1 CART回归树生成树
6.2 最小二乘法回归树
6.3 CART分类树生成
6.3.1 基尼指数
6.3.2 CART分类树生成
6.3.3 CART剪枝
6.3.4 CART剪枝流程
7.代码实现
上一篇:【机器学习(三)】机器学习中:信息熵,信息增益,信息增益比,原理,案例,代码实现。
1.引言
决策树(decision tree)是一种分类与回归的方法,顾名思义,决策树呈树形结构,可以认为是if-then规则的集合,也可以认为是特征空间与类空间上的条件概率分布。
主要的优点:分类速度快、可读性强。
决策树学习通常有三个步骤:特征选择、决策树生成和决策树修剪。
常用的决策树算法有:ID3算法、C4.5算法和CART算法,其中CART更是被广泛应用。
2.决策树
定义:分类决策树模型是一种描述对实例进行分类的属性结构。决策树由结点和向边组成。结点有两种类型:内部结点和叶结点。内部结点表示一个特征或者属性,叶结点表示一个类。
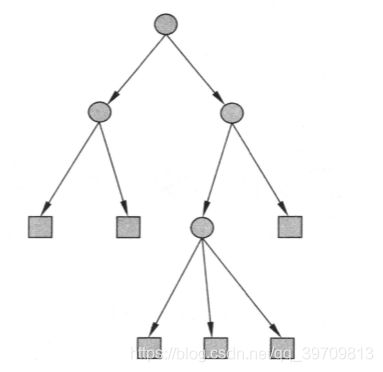
例如上图,圆形是内部结点,表示特征和属性,矩形表示叶子结点,表示一个类。训练的时候,按照训练数据集的属性和类,逐渐构建一个树,分类的时候,从根结点按照递归的方法对内部结点的属性进行测试和匹配,直到到达叶结点。
2.1 决策树与if-then规则
可以认为决策树是if-then规则的集合,其中内部结点之间连城的通路,构建成一条规则。路径上的点是规则的条件,叶子结点则是规则的结论。每一个实例都被一条路径或者一条规则覆盖,而且只被一条路径或规则覆盖。
2.2 决策树与条件概率分布
决策树还可以认为是特征条件下类的条件概率分布。将特征空间划分为互不相交的单元或区域,并在每个单元定义一个类的概率分布。而决策树的一条路径就是一个单元,因此可以认为决策树是给定条件下类的概率分布的集合。
2.3 决策树学习
给定训练集![]() ,其中
,其中![]() ,n是特征个数;
,n是特征个数;![]() 是类的标记。
是类的标记。
决策树的目的就是根据训练数据集构建一个决策树模型,使它能够对实例进行正确分类。
所以决策树的本质就是从训练数据中归纳出一组分类规则,这样决策树可能有很多个,也可能一个没有。但是我们需要的是一个与训练数据矛盾较小的决策树,又要具有很好的泛化能力,不仅对训练数据有很好的拟合,对未知数据又有很好的预测。
决策树学习使用损失函数作为自己的目标函数,学习的策略就是最小化损失函数。决策树学习的算法通常是一个递归选择最优特征的方法,根据特征对训练数据进行分割,使各个子数据有一个最好的分类过程。这一个过程也是对特征空间的划分,也对应着决策树的构建。从根结点开始,选择特征作为自己的内部结点,递归构建,直到每个子集都被分到叶子结点上(即都有明确的分类),这就完成类决策树的构建。
3.特征选择
在构建决策树的时候,可以构建许多决策树,哪种决策树才是最有效的决策树?在开始构建的时候就考虑这个问题。要想构建一个高效的决策树,一般(CART除外)需要遵守信息增益或信息增益比的规则(点此查看信息熵、信息增益、信息增益比原理)。一般我们选择信息增益或信息增益比最大的特征作为当前的特征。信息增益体现出了特征与类的关联程度,即特征对类的不确定度的影响程度,信息增益比则是对这种程度的修正,避免决策树偏向选择取值较多的特征。
举一个例子:下表是贷款申请情况表,最后一列给出类是否给予贷款。
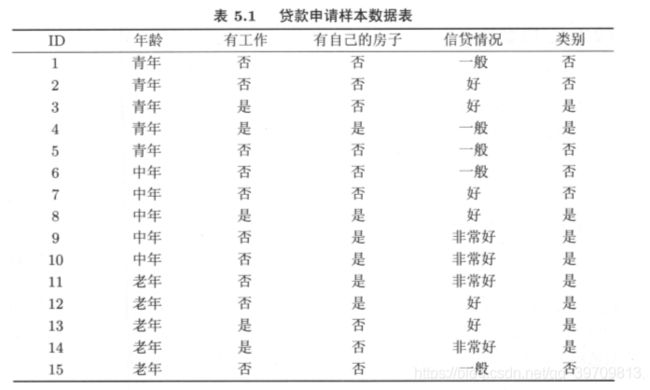
我们要从这表中构建一个决策树,怎样选择特征作为节点呢?
所以需要计算类的信息熵、特征与类的信息增益、信息增益比。
如下图,通过计算得到房子的信息增益最大(0.420),要是以信息增益为特征条件,那么构建决策树的第一个节点(根结点)应该是“房子”这个特征。(此处有详细的计算过程:信息熵、信息增益、信息增益比原理)

如下图,计算得到信息增益比,同样特征“房子”的信息增益比最大(0.4325),当以信息增益比为选择条件的时候,特征“房子”应该作为第一个节点(根结点)

4.决策树生成
4.1 ID3生成算法
ID3算法的核心就是在决策树各个节点上使用信息增益作为选择特征的准则,使用递归方法构建决策树。
输入:训练数据集D,特征集A和阈值
输出:决策树T
- 若D中所有实例属于同一类
,则T为单结点树,并将类
- 若
,则T为单结点树,将D中实例树最大的类
- 否则信息增益算法计算A中各特征对D的信息增益,选择信息增益最大的特征
;
- 如果
- 否则,对
,依照
,将
- 对第i个子节点,以
为新的特征集,递归调用1~5,得到树T,返回T。
以上一个案例为为例:
 作为特征“年龄”,
作为特征“年龄”,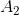 作为特征“工作”,
作为特征“工作”,![]() 作为特征“房子”,
作为特征“房子”,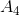 作为特征“信贷”。在上一步的计算中,可以知道特征
作为特征“信贷”。在上一步的计算中,可以知道特征![]() 的信息增益最大,所以选择
的信息增益最大,所以选择![]() 作为根结点的特征。它把数据集划分为两个子集
作为根结点的特征。它把数据集划分为两个子集 (
(![]() 取是)和
取是)和 (
(![]() 取否)。由于只有同一类的样本点,所以单独成为一个叶子结点,结果类标记“是”。
取否)。由于只有同一类的样本点,所以单独成为一个叶子结点,结果类标记“是”。
则下面对从特征、和中选择新的特征,计算各个特征的信息增益:

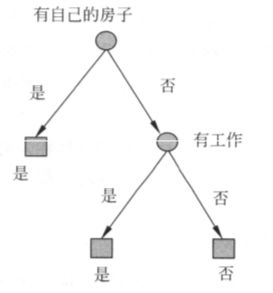
从上图,可以看到信息增益最大,因此作为新的内部结点。
从引出两个节点,即将数据集划分成两个![]() (取是)和
(取是)和![]() (取否)。由于
(取否)。由于![]() 内的类属于同一类,且类标记为“是”,故此数据集为叶子结点,且标记为“是”;
内的类属于同一类,且类标记为“是”,故此数据集为叶子结点,且标记为“是”;![]() 内的类也是属于同一类,故此数据集为叶子结点,且类标记为“否”。这样就生成了一个决策树(下图),仅仅使用了两个特征,使决策树更加高效。
内的类也是属于同一类,故此数据集为叶子结点,且类标记为“否”。这样就生成了一个决策树(下图),仅仅使用了两个特征,使决策树更加高效。
4.2 C4.5生成算法
ID3算法生成树有一个缺点,就是容易过拟合。为此C4.5算法对ID3算法进行改进,使用信息增益比作为选择特征的条件。
输入:训练数据集D,特征集A和阈值
输出:决策树T
- 若D中所有实例属于同一类
- 若
- 否则信息增益算法计算A中各特征对D的信息增益比,选择信息增益比最大的特征
- 如果
- 否则,对
- 对第i个子节点,以
以上一个为例,计算信息增益比:
作为特征“年龄”,作为特征“工作”,![]() 作为特征“房子”,作为特征“信贷”。如下图,可以知道
作为特征“房子”,作为特征“信贷”。如下图,可以知道![]() 的信息增益比最大,因此选择
的信息增益比最大,因此选择![]() 作为根结点。它把数据集划分为两个子集(
作为根结点。它把数据集划分为两个子集(![]() 取是)和(
取是)和(![]() 取否)。由于只有同一类的样本点,所以单独成为一个叶子结点,结果类标记“是”。
取否)。由于只有同一类的样本点,所以单独成为一个叶子结点,结果类标记“是”。

则下面对从特征、和中选择新的特征,计算各个特征的增益比:
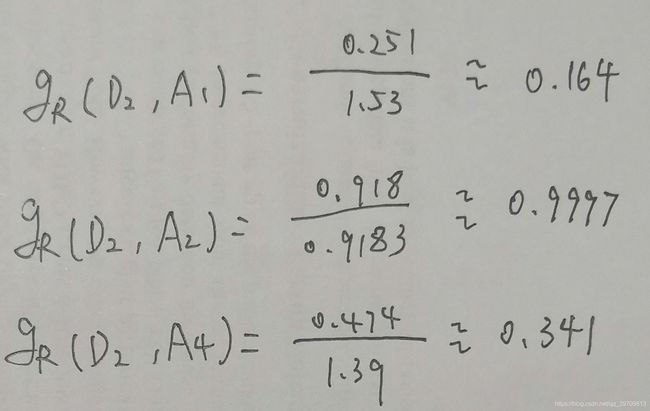
从上图,可以看到信息增益比最大,因此作为新的内部结点。
从引出两个节点,即将数据集划分成两个![]() (取是)和
(取是)和![]() (取否),由于
(取否),由于![]() 内的类属于同一类,且类标记为“是”,故此数据集为叶子结点,且标记为“是”;
内的类属于同一类,且类标记为“是”,故此数据集为叶子结点,且标记为“是”;![]() 内的类也是属于同一类,故此数据集为叶子结点,且类标记为“否”。
内的类也是属于同一类,故此数据集为叶子结点,且类标记为“否”。
这样就生成了一个决策树,在这个案例中,C4.5和ID3生成的决策树是一样的,但是规则上有细微的区别——特征条件不同。
5.决策树剪枝
ID3和C4.5算通过递归产生决策树,直到不能继续。这样产生的树往往对训练数据分类很准确,但是对未知的测试数据的分类却没有那么准确——过拟合。因此需要通过剪枝,对已经生成的树进行简化,增加决策树的鲁棒性。
顾名思义,剪枝,就是裁掉一些已经生成的子树或者叶子结点,将其父结点或者根结点作为新的叶结点,从而简化了分类树模型。
决策树剪枝通过极小化整体损失函数或代价函数实现。
设树T的叶结点个数为 ,t是树T的叶结点,该结点有
,t是树T的叶结点,该结点有 个样本点,其中k类的样本点有
个样本点,其中k类的样本点有![]() 个,
个,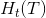 为叶结点t上的经验熵,
为叶结点t上的经验熵, 是参数。则决策树学习的损失函数为:
是参数。则决策树学习的损失函数为:
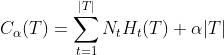
其中经验熵为:![]() ,
,
将损失函数的右边第一项记做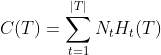 ,这是损失函数变成
,这是损失函数变成![]() 。
。
当
较大时,最优树偏小;
,根结点组成的单结点最优;
,整个树是最优的。
决策树的生成只考虑了通过提高信息增益或信息增益比来训练数据,这样使模型对训练数据有很好的拟合效果,对未知数据的分类效果不是十分好。剪枝,通过优化损失函数,减小模型复杂度,学习整体最好表现。
剪枝,就是当确定时,选择损失函数最小的模型,即损失函数最小的子树。
5.1剪枝算法
输入:生成算法产生的决策树T,参数;
输出:修剪后的子树 。
。
- 计算每个节点的经验熵
- 递归地从树的叶结点向上回溯。设一组叶结点回到其父结点,之前之后整体树分别为
和
,对应的损失函数分别是
和
,如果:
,则进行剪枝,将父结点变为新的叶结点。
- 返回2,直到不能继续剪枝为止,得到损失函数最小的子树
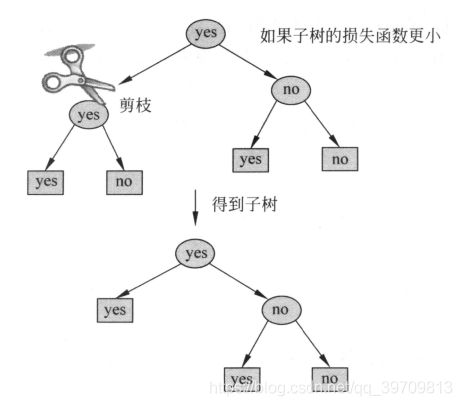
决策树的剪枝是在局部进行的,所以决策树剪枝可以由动态规划算法实现。
6.CART算法
CART(classififcation and regression trees)是一种既可以分类(离散)也可以回归(连续)的决策树。CART只假设决策树是二叉树,因此CART最终生成的树形结构是二叉树。
6.1 CART回归树生成树
假设X与Y是输入和输出变量,并且Y是连续的,给定训练数据集![]() 。将输入控件划分为M个单元,于是回归树模型可以表示为:
。将输入控件划分为M个单元,于是回归树模型可以表示为:
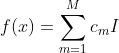
当输入空间事先知道时,使用平方误差![]() 作为回归树的预测误差。
作为回归树的预测误差。
采用启发式方法,选择第 个变量
个变量 作为分类点,取他的值s,把输入数据切分成两部分
作为分类点,取他的值s,把输入数据切分成两部分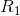 (输入小于s)和
(输入小于s)和 (输入大于s)。
(输入大于s)。
然后寻找最优切分变量和最优切分点 即可。
即可。
6.2 最小二乘法回归树
按照6.1方法生成的回归树就是最小二乘回归树(二叉树)。
输入:训练数据集
输出:回归树
- 选择最优切分变量
,找到损失最小的
- 用选定的(j,s)划分区域
- 继续对两个区域调用步骤1和2,直到满足停止条件。
- 将输入空间划分为M个子区域
,生成决策树:
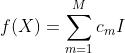
继续以上一个案例为例,如何使用最小二乘回归树来构建决策树。
首先是挨个特征计算,找到损失函数最小的特征。从第一轮结果中可知道![]() 的损失最小(3),因此选择“房子”作为根结点,将数据划分成两部分。左边是,由于中的数据全为一类,因此为一个叶结点。右边是,对其内的特征继续计算损失函数,即第二轮计算。
的损失最小(3),因此选择“房子”作为根结点,将数据划分成两部分。左边是,由于中的数据全为一类,因此为一个叶结点。右边是,对其内的特征继续计算损失函数,即第二轮计算。
从结果中可以看到,的损失值为0,因此可以直接停止后续计算,确定“工作”为新的节点。将数据分成两部分:![]() 和
和![]() 。其中
。其中![]() 数据为一类,所以
数据为一类,所以![]() 是叶子结点。同理
是叶子结点。同理![]() 也是叶子结点。这就生成了一个归回二叉决策树。
也是叶子结点。这就生成了一个归回二叉决策树。

6.3 CART分类树生成
分类树是使用基尼指数作为特征选择,同时决定这个特征的最优二值切分点(生成的同样是二叉树)。
6.3.1 基尼指数
设有K个分类,样本属于第k类的概率是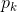 :
:
- 概率分布的基尼指数定义为:
- 二分类问题,属于1的概率是p,基尼指数为:
- 集合问题,
。如果集合D被特征A分割成两部分
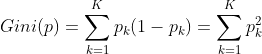
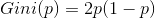

基尼指数和信息增益、信息增益比一样,都近似代表分类误差率。
6.3.2 CART分类树生成
输入:训练数据集D
输出:CART决策树
从根结点开始,递归地对每个结点进行一下操作,构建二叉树:
- 设结点的训练数据集为D,计算现有特征A对D的基尼指数;
- 选择基尼指数最小的特征及其对应点,将数据集分成两部分,分配到两个子节点中。
- 对两个子节点递归调用1和2,直到满足停止条件(节点中样本个数小于预定阈值或基尼指数小于预定阈值)。
- 生成CART决策树
同样以上一个案例为例,如何使用CART算法生成决策树
首先是挨个特征计算,计算基尼指数。从第一轮结果中可知道![]() 的基尼指数最小(0.27),因此选择“房子”作为根结点,将数据划分成两部分。左边是,由于中的数据全为一类,因此为一个叶结点。右边是,对其内的特征继续计算新的基尼指数,即第二轮计算。
的基尼指数最小(0.27),因此选择“房子”作为根结点,将数据划分成两部分。左边是,由于中的数据全为一类,因此为一个叶结点。右边是,对其内的特征继续计算新的基尼指数,即第二轮计算。
从结果中可以看到,的基尼指数为0,确定“工作”为新的节点。将数据分成两部分:![]() 和
和![]() 。其中
。其中![]() 数据为一类,所以
数据为一类,所以![]() 是叶子结点。同理
是叶子结点。同理![]() 也是叶子结点。这就生成了一个归回二叉决策树。
也是叶子结点。这就生成了一个归回二叉决策树。

6.3.3 CART剪枝
从生成的决策树底部开始,剪去一些子树,使决策树变小,从而能够对未知数据有更准确的预测。
剪枝的步骤就是先在已经生成决策树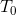 底端不断剪枝,直到的根结点,形成一个子树序列
底端不断剪枝,直到的根结点,形成一个子树序列![]() ;然后通过交叉验证法在独立的验证数据集上对子树序列进行预测,从中选择最优子树。
;然后通过交叉验证法在独立的验证数据集上对子树序列进行预测,从中选择最优子树。
在剪枝的过程中计算子树的损失函数: ,其中
,其中 是对训练数据的预测误差,是子树的叶子结点个数,
是对训练数据的预测误差,是子树的叶子结点个数,![]() 是参数为时的子树
是参数为时的子树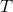 的整体损失。
的整体损失。
当
或
当
所以,只要
,
和t就有相同的损失函数,t是单结点,
,同时将
设为
,那么
的最优子树。如此一直剪下去,直到根结点。
剪枝得到子树序列![]() ,利用独立验证的数据集测试子树序列中各个子树的平方误差或者基尼指数。在子树序列中,一个子树对应一个
,利用独立验证的数据集测试子树序列中各个子树的平方误差或者基尼指数。在子树序列中,一个子树对应一个 ,选择损失最小的子树作为最终的剪枝结果,得到最优化决策树。
,选择损失最小的子树作为最终的剪枝结果,得到最优化决策树。
6.3.4 CART剪枝流程
输入:CART回归生成树
输出:最优决策树
- 设
- 设
- 自下而上地对各个内部结点t计算
,
以及
,
。其中
是对训练数据的预测误差,
- 对
的内部结点t进行剪枝,并对叶结点t以多数表决法(投票)决定其类,得到树T。
- 设
- 如果
不是由根结点以及两个叶结点构成的数,则返回到步骤2;否则令
。
- 采用交叉验证法在子树序列
中选择最优的子树
7.代码实现
关于案例的ID3算法和C4.5算的信息增益和信息增益比的代码实现,见信息熵、信息增益、信息增益比原理。
案例的ID3算法实现如下(不使用机器学习库):
import numpy as np
import pandas as pd
from math import log
def create_data():
datasets = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否'],
]
labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']
# 返回数据集和每个维度的名称
return datasets, labels
# 定义节点类 二叉树
class Node:
def __init__(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {'label:': self.label, 'feature': self.feature, 'tree': self.tree}
def __repr__(self):
return '{}'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
return self.tree[features[self.feature]].predict(features)
class DTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# 熵
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p) / data_length) * self.calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data.iloc[:, :-1], train_data.iloc[:, -1], train_data.columns[:-1]
# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回T
if len(y_train.value_counts()) == 1:
return Node(root=True,
label=y_train.iloc[0])
# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回T
if len(features) == 0:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回T
if max_info_gain < self.epsilon:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 5,构建Ag子集
node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1)
# 6, 递归生成树
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
# pprint.pprint(node_tree.tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(train_data)
print(tree)
print('预测结果:', dt.predict(['老年', '否', '否', '一般']))
结果展示:
树的结构:{'label:': None, 'feature': 2, 'tree': {'否': {'label:': None, 'feature': 1, 'tree': {'否': {'label:': '否', 'feature': None, 'tree': {}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}
对'老年', '否', '否', '一般'的预测结果是:否
使用机器学习库:可以实现ID3、CART算法,具体的需求可以根据注释的地方更改即可。
from sklearn import tree
import numpy as np
def create_data():
datasets = [[1, 0, 0, 1, 0],
[1, 0, 0, 2, 0],
[1, 1, 0, 2, 1],
[1, 1, 1, 1, 1],
[1, 0, 0, 1, 0],
[2, 0, 0, 1, 0],
[2, 0, 0, 0, 0],
[2, 1, 1, 0, 1],
[2, 0, 1, 3, 1],
[2, 0, 1, 3, 1],
[2, 0, 1, 3, 1],
[2, 0, 1, 2, 1],
[2, 1, 0, 2, 1],
[2, 1, 0, 3, 1],
[2, 0, 0, 1, 0],
]
datasets = np.array(datasets)
# 返回数据集和每个维度的名称
return datasets[:, :4], datasets[:, -1]
train_x, train_y = create_data()
# 标准的格式
# tree.DecisionTreeClassifier(criterion='gini',splitter='best',
# max_depth=None,min_samples_split=2,
# min_samples_leaf=1,min_weight_fraction_leaf=0.0,
# max_features=None,random_state=None,
# max_leaf_nodes=None,min_impurity_decrease=0.0,
# min_impurity_split=None,class_weight=None,
# presort=False)
clf = tree.DecisionTreeClassifier(criterion='entropy') # ID3
# clf = tree.DecisionTreeClassifier(criterion='gini') # CART
clf.fit(train_x, train_y)
# 测试一个数据集
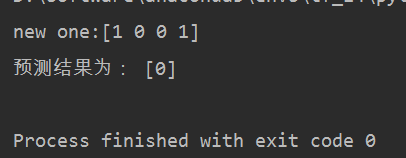
new = train_x[0, :]
print('new one:' + str(new))
print('预测结果为:', clf.predict(new.reshape(1,-1)))
结果展示,找一个数据进行测试的结果如下:
下一篇:【机器学习(五)】从决策树到随机森林
-------------------------------------------------------------------------------------------------------------------------------------
2020-6-17更新了ID3实现案例的代码部分、使用机器学习库实现决策树的部分。