操作系统实验:Linux下的进程控制实验
进程控制实验
- 一、实验目的:
- 二、实验平台:
- 三、实验内容:
-
- 1.进程的创建与销毁
-
-
- 进程控制相关函数
-
- 实验结果分析
- 2.多进程并发执行
-
-
- time命令
-
- 实验结果分析
- 四、总结分析
一、实验目的:
加深对进程概念的理解,明确进程和程序的区别;掌握Linux操作系统的进程创建和终止操作,体会父进程和子进程的关系及进程状态的变化;进一步认识并发执行的实质,编写并发程序。
二、实验平台:
虚拟机:VMWare15.5.1
操作系统:CentOS7 64位
编辑器:Vim
编译器:Gcc
三、实验内容:
1.进程的创建与销毁
编写一段程序,使用系统调用fork()创建两个子进程,当此程序运行时,在系统中有一个父进程和两个子进程活动。让每一个进程在屏幕上显示“身份信息”:父进程显示“Parent process! PID=xxx1 PPID=xxx2”;子进程显示“Childx process! PID=xxx PPID=xxx”。多运行几次,观察记录屏幕上的显示结果,并分析原因。
说明:
xxx1为进程号,用getpid()函数可获取进程号;
xxx2为父进程号,用getppid()函数可获取父进程号;
Childx中x为1和2,用来区别两个子进程;
wait()函数用来避免父进程在子进程终止之前终止。
实验主要代码:
//print.c
#include//example1.c
#include实验过程:编辑print.c和example1.c两个文件,输入命令行对.c文件进行编译输出。
编译过程:#gcc print.c –o print
#gcc example1.c –o example1
运行截图如下:
进程控制相关函数
1.fork()
用于创建一个新进程(子进程)。
函数原型:
#include
pid_t fork(void);
返回:子进程中为0,父进程中为子进程ID,出错为-1。
子进程被创建后就进入就绪队列和父进程分别独立地等待调度。子进程继承父进程的程序段代码,子进程被调度执行时,也会和父进程一样从fork()返回。
从共享程序段代码的角度来看,父进程和子进程所执行的程序代码是同一个,在内存中只有一个程序副本;
但是从编程的角度来看,为了使子进程和父进程做不同的事,需要在程序中区分父进程和子进程的代码段。这需要借助于fork()的返回值来标志当前进程的身份。从fork()返回后,都会执行语句:pid=frok();
得到返回值pid有三种情况,分别对应出错(小于0)、在父进程中(大于0)、在子进程中(等于0)。
由于父进程和子进程各自独立地进入就绪队列等待调度,所以谁会先得到调度是不确定的,这与系统的调度策略和系统当前的资源状态有关。因此谁会先从fork()返回并继续执行后面的语句也是不确定的。
2.wait()
查询子进程的退出状态(即正常退出的退出码或导致异常终止的信号),并回收子进程的内核资源。
函数原型:
#include
pid_t wait(int * status);
返回值:若成功则返回进程ID,若出错则返回-1。
Wait()函数常用来控制父进程和子进程的同步。在父进程中调用wait()函数,则父进程被阻塞,进入等待队列,等待子进程结束。当子进程结束时,会产生一个终止状态字,系统会向父进程发送SIGCHLD信号。当接到信号后,父进程提取子进程的终止状态字,从wait()函数返回继续执行原程序。
3. exit()
exit()是进程结束最常调用的函数,在main()函数中调用return,最终也是调用exit()函数。这些都是进程的正常终止。在正常终止时,exit()函数返回进程结束状态。
函数原型:
#include
void exit(int status)
从OS角度来看,进程终止会释放进程用户空间的所有资源,而进程描述符并不释放,它将来由其父进程回收。若父进程先于子进程终止,子进程成为“孤儿进程”,“孤儿进程”会被init进程(进程号为1)领养;若子进程先于父进程终止,子进程成为“僵尸进程”,父进程尚未对其进行善后处理(获取终止子进程的有关信息,释放它仍占用的资源)。
程序可以执行到main()的最后一个“}“结束,也可以运行exit();结束,也可以运行到return 0;结束。
4.execl()
系统调用execl()可以将新程序加载到某一进程的内存空间,该进程会从新程序的main()函数开始执行。
函数原型:
#include
int execl (const char * pathname, const char * arg0,…/*(char*)0*/)
pathname是要加载程序的全路径名,arg0及以后为参数列表。
进程的用户内存空间被替换,而进程的其他属性基本不改变。进程完整的内存空间:正文区、堆区、栈区、数据区都被替换,原内容不存在了。代码替换完后,在execl()后面的代码毫无意义。
实验结果分析
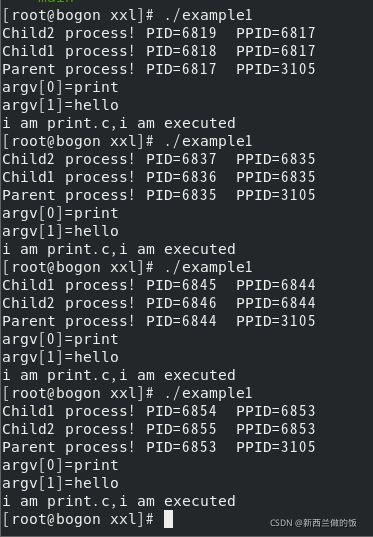
先后四次运行,根据输出分析实验结果:
①每次运行创建的子进程Childx process的PPID均为父进程Parent process的PID,说明两个子进程均为同一父进程创建。
②每次运行的父进程Parent process的PPID均为3105,说明父进程也以子进程的形式存在,其父进程为同一系统进程。
③我们注意第一个if代码段,调用了execl()函数,将当前进程child1替换掉,所以之后的"where am I?”字符串并没有被输出,child1进程从print程序的main()开始执行,输出两个传参以及一段字符串,最终在main()的return 0;后结束。
④进程创建后由于父进程和子进程各自独立地进入就绪队列等待调度,所以谁会先得到调度是不确定,实验数据可以看出child1进程先运行和child2进程先运行各出现两次。
⑤父进程代码段因为调用了wait()函数,等待子进程结束后函数返回继续执行原程序,输出相应信息,所以父进程字符串最后才输出。
2.多进程并发执行
fork()和exec()系列函数能同时运行多个程序,利用上述函数将下面单进程顺序执行的程序single.c改造成可并发执行3个进程的程序multi_process.c;并用time命令获取程序的执行时间,比较单进程和多进程运行时间,并分析原因。
//single.c
#include 编译过程:#gcc single.c –o single
运行截图如下:
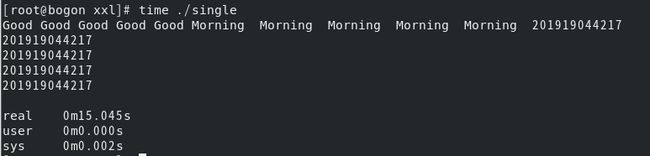
结果分析:单进程执行按次序依次打印五次三个字符串。
创建多个进程代码:
//print1.c
#include//multi_process.c
#include编译过程:#gcc print1.c –o print1
#gcc multi_process.c –o multi
运行截图如下:
time命令
time命令
linux下time命令可以获取到一个程序的执行时间,包括程序的实际运行时间(real time),以及程序运行在用户态的时间(user time)和内核态的时间(sys time)。命令行执行结束时在标准输出中打印执行该命令行的时间统计结果,其统计结果包含以下数据:
1)实际时间(real time): 从command命令行开始执行到运行终止的消逝时间;
2)用户CPU时间(user CPU time): 命令执行完成花费的用户CPU时间,即命令在用户态中执行时间总和;
3)系统CPU时间(system CPU time): 命令执行完成花费的系统CPU时间,即命令在核心态中执行时间总和。
其中,用户CPU时间和系统CPU时间之和为CPU时间,即命令占用CPU执行的时间总和。实际时间要大于CPU时间,因为Linux是多任务操作系统,往往在执行一条命令时,系统还要处理其它任务。
用法:#time ./example
实验结果分析
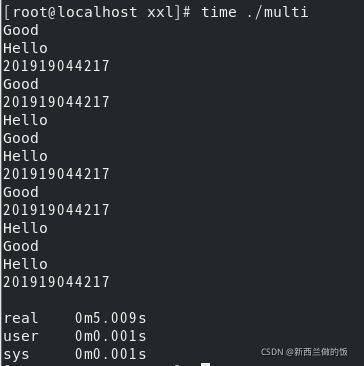
多进程实验中因为是三个进程并发执行,所以时间上几乎是单个进程的1/3;因为是并发执行的,所以打印结果无序。
四、总结分析
通过两天的学习了解,从Linux系统虚拟机环境搭建,到vim编辑保存文本文件(其实我用的文本编辑器),到用gcc编译.c文件,运行查看结果这一套流程,更加深刻了解了Linux系统下进程控制方式,以及多进程并发执行效果。