上采样、反卷积、上池化的区别
上采样、反卷积、上池化的区别
最近,工作中遇到了一个小问题,就是pytorch转onnx转caffe转wk(海思相机NNIE支持的深度学习权重文件格式)的时候,最终输出的Tensor的值有些许差别,后来找到了原因:pytorch项目中使用的upsample中mode选择的是"bilinear",但是onnx2caffemodel的时候默认使用是的"nearest",最终就会导致二者输入Tensor的余弦相似度并不是99.9999%。所以,特地把上采样这一块最容易忽略的知识点领出来单独说说,以下内容要是有说的不正确的地方或者与笔者有不同意见的地方,还请勿喷~
一、上采样(upsample)
在pytorch1.2版本中,实现上采样的接口是torch.nn.functional.interpolate中。
def interpolate(input: Tensor,
size: Optional[int] = None,
scale_factor: Optional[List[float]] = None,
mode: str = 'nearest',
align_corners: Optional[bool] = None,
recompute_scale_factor: Optional[bool] = None) -> Tensor: # noqa: F811
其中,mode就是选择上采样的方式,源码中有这么一段话:

pytorch中,默认使用“nearest”,除此以外,常用的还有“bilinear”(双线性插值)
1.最领近插值(nearest)
原理:输出像素的像素值等于邻域内离它距离最近的像素值,什么意思呢,画个草图吧。

假设输入tensor的shape是[1, 1, 2, 2],现在想将其上采样2倍,然后理应应该生成[1, 1, 4, 4](这里需要说明的是,通常我们称上采样是w和h维度上,batch_size和chanels维度不能称为上采样,batch_size维度是不变的,channels维度变换一般用卷积来进行通道数的变化)。
上图中,A1~A12都是需要通过插值来进行填充的。其中,A1、A3、A4距离2、3、4的欧式距离相对于距离1来说是大于的,所以该三处插值1,其余同理…
总结:该方式最大的好处莫过于就是计算简单吧,不需要额外的复杂的计算流程,但是同时生成的上采样的图片就会出现锯齿状
代码实现:
inp = np.array(range(1, 5)).reshape(1,1,2,2)
out = F.upsample(torch.Tensor(inp), (4, 4), None, "nearest")
结果:
inp = [[[[1 2]
[3 4]]]]
out = [[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
2.双线性插值(bilinear)
在讲双线性插值之前,先来说下什么叫线性插值。根据名字中“线性”这两个字就能很好的做出解释:距离越远,插值就越小,反之同理。
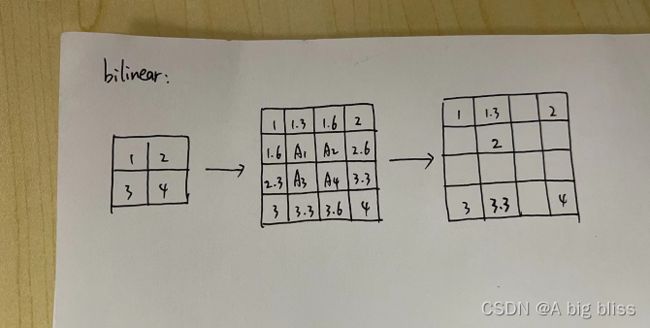
上图所示,先通过距离远近,先计算出四周的插值大小。例如第一行,平分1~2,那么靠近1的就是:
1 + (1 / 3) = 1.33
靠近2的就是:1 + (1 / 3)* 2 =1.67。
计算完四周的插值之后,就要计算中间的A1~A4。比如A1,计算出第一行第二列的1.3和第四行第二列的3.3之后,再做一次线性插值:1.3 + (2 / 3)= 2,同理就得到了其余的插值。
代码实现:
inp = np.array(range(1, 5)).reshape(1,1,2,2)
out2 = F.upsample(torch.Tensor(inp), (4, 4), None, "bilinear", align_corners=True)
结果:
inp = [[[[1 2]
[3 4]]]]
out2 = [[[[1.0000, 1.3333, 1.6667, 2.0000],
[1.6667, 2.0000, 2.3333, 2.6667],
[2.3333, 2.6667, 3.0000, 3.3333],
[3.0000, 3.3333, 3.6667, 4.0000]]]]
这里值得注意,我在最后加了一个align_corners=True的选项。如果设置为False,那么结果又会不一样。
inp = np.array(range(1, 5)).reshape(1,1,2,2)
out1 = F.upsample(torch.Tensor(inp), (4, 4), None, "bilinear")
结果:
inp =[[[[1 2]
[3 4]]]]
out2 = [[[[1.0000, 1.2500, 1.7500, 2.0000],
[1.5000, 1.7500, 2.2500, 2.5000],
[2.5000, 2.7500, 3.2500, 3.5000],
[3.0000, 3.2500, 3.7500, 4.0000]]]]
关于align_corners,可以具体参考这篇文章:pytorch 上采样 upsample 时align_corners 设为true 还是false,该blog里面有一句总结写的很好:
- 当align_corners = True时,像素被视为网格的格子上的点,拐角处的像素对齐.可知是点之间是等间距的
- 当align_corners = False时, 像素被视为网格的交叉线上的点, 拐角处的点依然是原图像的拐角像素,但是差值的点间却按照上图的取法取,导致点与点之间是不等距的
2、反卷积(deconvolution)
知乎上看到一篇写的很好的关于反卷积的blog,这里我就直接copy了(大佬看到,如果觉得侵权可联系我删除)


大佬文章传送门:反卷积(Transposed Convolution)详细推导
3、上最大池化(upmaxpooling)
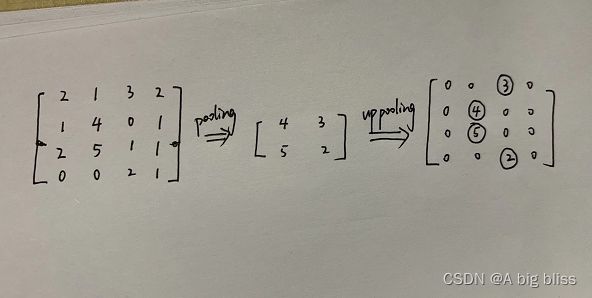
反池化是最简单的了,就是记录正向池化的时候,最大值的位置。比如上图,input是[4,4],经过最大池化之后得到[2,2]。由于记录了这四个值在input的位置,所以进行上池化的时候机会还原其最大值的位置,同事其他位置填充0。
4、总结
在分割网络中,上采样是必不可少的一个模块。通常来说,上采样和上池化是没有参数进行传播的,而反卷积是有参数的。同时,反卷积会出现“棋盘效应”,所以一般不太推荐使用。在对分割要求严格的时候,建议使用上采样中的双线性插值的方法。
参考地址:
https://www.cnblogs.com/linkr/p/3630902.html
https://blog.csdn.net/wangweiwells/article/details/101820932
https://zhuanlan.zhihu.com/p/48501100