深度学习(手写数字识别)
本程序采用百度paddlepaddle深度学习框架,并在百度AI Studio平台上运行
目录
1 实验内容
2 实验流程
3 DNN模型
4 LeNet 模型
4.1 LeNet-1模型
4.2 Lenet-4 模型
4.3 LeNet-5 模型
4.4 LeNet 模型的总结
4.5 LeNet 模型与DNN模型比较
5 模型的应用
5.1 自己的手写数字图片
5.2将手写的图片进行预处理
5.3调用训练好的模型进行预测
5.4 总结
1 实验内容
本次实验采用构造 DNN 模型与 LeNet 模型进行手写数字识别实验,采用经典手写数字识别数据集 MINIST,MINIST 数据集包含60000个训练集与10000个测试集。数据集分为图片与标签,其中图片是28*28的像素矩阵,标签为 0~9 共10个数字。该数据集的官方网址为MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
2 实验流程
在实验过程中为确保最终训练的神经网络拥有较强的泛化能力,本次实验会在最后对自己手写的一些数字图片进行识别。

3 DNN模型
以下的代码判断就是定义一个简单的 DNN模型(多层感知器),一共有三层,两个大小为100的隐层和一个大小为10的输出层,因为MNIST数据集是手写0到9的灰度图像,类别有10个,所以最后的输出大小是10。最后输出层的激活函数是Softmax,所以最后的输出层相当于一个分类器。加上一个输入层的话,多层感知器的结构是:输入层-->>隐层-->>隐层-->>输出层。神经网络结构如下

利用 paddlepaddle 的动态图对初始的 DNN 模型进行定义,代码如下
# 定义多层感知器
#动态图定义多层感知器
class multilayer_perceptron(fluid.dygraph.Layer):
def __init__(self):
super(multilayer_perceptron,self).__init__()
self.fc1 = Linear(input_dim=28*28, output_dim=100, act='relu')
self.fc2 = Linear(input_dim=100, output_dim=100, act='relu')
self.fc3 = Linear(input_dim=100, output_dim=10,act="softmax")
def forward(self,input_):
x = fluid.layers.reshape(input_, [input_.shape[0], -1])
x = self.fc1(x)
x = self.fc2(x)
y = self.fc3(x)
return y经过一段时间的调参最终选择 optimizer 为 Adam,learning rate 为0.001,batch_size 为64,epoch为5,损失函数选择softmax,最终训练曲线与在验证集上的准确率如下
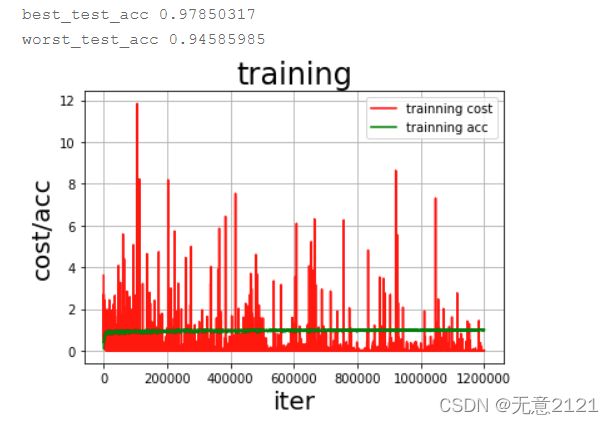


由以上结果可以看出DNN模型在经过调参后在测试集的准确率较高,但是由于这种三层全连接神经网络的结构过于简单,并且经典数据集量较少,所以 loss曲线与acc曲线的震荡都比较厉害,可见模型在预测时的稳定性较差,因此接下来将采用 LeNet 模型进行识别。
4 LeNet 模型
4.1 LeNet-1模型
在Lenet-1中, 28*28 的输入图像矩阵 --> 经过卷积(卷积层4层,卷积核size为5*5,步长为1) --> 4个24*24 feature maps -->平均池化层(2*2 size,步长为2)-->4个12*12 feature maps -->经过卷积(卷积层3层,卷积核size为5*5,步长为1)--> 12个8*8 feature maps平均池化层(2*2 size,步长为2)-->12个4*4 feature maps --> 直接全连接到10个输出。示意图如下
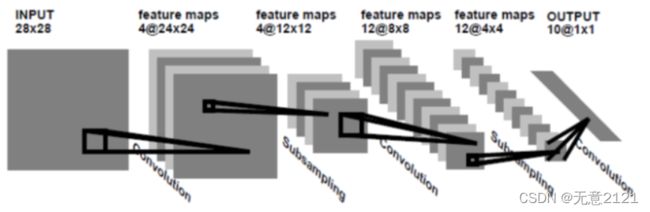
定义 LeNet-1 模型的代码如下
import paddle
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=4, kernel_size=5, stride=1, padding=2)
self.Max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=4, out_channels=12, kernel_size=5, stride=1)
self.Max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=12*5*5, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.Max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.Max_pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
return x最终 LeNet-1模型对MINIST测试集的评估结果如下(准确率达到98.05%)
![]()
4.2 Lenet-4 模型
在Lenet-4中, 32*32 的输入图像矩阵 --> 经过卷积(卷积层4层,卷积核size为5*5,步长为1) --> 4个28*28 feature maps -->平均池化层(2*2 size,步长为2)-->4个14*14 feature maps -->经过卷积(卷积层16层,卷积核size为5*5,步长为1)--> 16个10*10 feature maps平均池化层(2*2 size,步长为2)-->16个5*5 feature maps --> 直接全连接到120个神经元 --> 直接全连接到10个输出。示意图如下

定义 LeNet-4 模型的代码如下
import paddle
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x最终 LeNet-1模型对MINIST测试集的评估结果如下(准确率达到98.54%)
![]()
4.3 LeNet-5 模型
在Lenet-4中, 32*32 的输入图像矩阵 --> 经过卷积(卷积层6层,卷积核size为5*5,步长为1) --> 4个28*28 feature maps -->平均池化层(2*2 size,步长为2)-->4个14*14 feature maps -->经过卷积(卷积层16层,卷积核size为5*5,步长为1)--> 16个10*10 feature maps平均池化层(2*2 size,步长为2)-->16个5*5 feature maps --> 直接全连接到120个神经元 --> 直接全连接到84个输出 --> 直接全连接到10个输出。示意图如下

定义 LeNet-5 模型的代码如下
import paddle
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=100)
self.linear2 = paddle.nn.Linear(in_features=100, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x最终 LeNet-5模型对MINIST测试集的评估结果如下(准确率达到98.89%)
![]()
4.4 LeNet 模型的总结
由上述三个模型的对比可知
(1)神经网络在层数增加时会有更好的识别能力,也就是为什么深层的网络泛化能力更好
(2)最大池化比平均池化的效果更好,因为捕捉更尖锐的特征是识别时更关注的
(3)LeNet-4与LeNet-5通过padding=2使28*28的图变成32*32的图,像素更大,识别会更精确
(4)在实际代码中我采用了最大池化,与原始模型不同,目的是加速收敛,激活函数采用relu, 因为relu的拟合能力更强
(5)LeNet-5效果最好,也是通常LeNet模型所指向的版本
4.5 LeNet 模型与DNN模型比较
LeNet采用卷积神经网络,通过卷积对图像的特征提取能力更强,通过共享参数使图像的平移不变性得到保证,通过池化来减少过拟合,总之在图像处理预测的问题上卷积神经网络具有更强大的能力。
5 模型的应用
5.1 自己的手写数字图片





5.2将手写的图片进行预处理
为了保证训练数据的一致性(不受光照等因素影响),将图片转变成黑白图片,代码如下
#读取图片进行预处理
def load_image(infer_path):
image=Image.open(infer_path).convert('L')
image=image.resize((28, 28), Image.ANTIALIAS)
image=np.array(image).reshape(28,28).astype(np.float32)
image=image/255*2-1
#将图片转化为黑白图
for i in range(image.shape[0]):
for j in range(image.shape[1]):
if image[i][j]>0.1:
image[i][j]=-1
else:
image[i][j]=1
plt.imshow(image.reshape(28,28),cmap='gray')
plt.show()
return image.reshape(1,1,28,28) 5.3调用训练好的模型进行预测
代码如下
infer_path='微信图片_20220331172616.jpg'
#获取图片
test_data, test_label= load_image(infer_path),0 #标签值自己设定
test_data = test_data.reshape([28,28])
plt.figure(figsize=(2,2))
#展示图片
print(plt.imshow(test_data, cmap=plt.cm.binary))
print('test_data 的标签为: ' + str(test_label))
#模型预测
result = model.predict([test_data.reshape(1,1,28,28)])
#打印模型预测的结果
print('预测值为:%d' %np.argmax(result))预测结果如下图





5.4 总结
虽然此次识别都正确,但是在真正的生活场景中,训练好的神经网络又不再适用,因为数字大小、位置、背景、光照、颜色等因素影响比较大,在MINIST数据集与自己手写导入的数据中,图片都是分辨率较低,外界的影响都比较相似,所以要获得一个适用于较广场景的数字手写识别神经网络,需要有包含各种环境的庞大数据集,并且还需要设计更复杂的网络模型。
5.5 完整 LeNet 模型源程序
#导入需要的包
import zipfile
import os
import random
import paddle
import matplotlib.pyplot as plt
from paddle.nn import MaxPool2D,Conv2D,BatchNorm
from paddle.nn import Linear
import sys
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import paddle
from multiprocessing import cpu_count
import matplotlib.pyplot as plt
import json
#导入数据集Compose的作用是将用于数据集预处理的接口以列表的方式进行组合。
#导入数据集Normalize的作用是图像归一化处理,支持两种方式: 1. 用统一的均值和标准差值对图像的每个通道进行归一化处理; 2. 对每个通道指定不同的均值和标准差值进行归一化处理。
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5],std=[127.5],data_format='CHW')])
# 使用transform对数据集做归一化
print('下载并加载训练数据')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('加载完成')
#让我们一起看看数据集中的图片是什么样子的
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
print(plt.imshow(train_data0, cmap=plt.cm.binary))
print('train_data0 的标签为: ' + str(train_label_0))
#定义LeNet
import paddle
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=100)
self.linear2 = paddle.nn.Linear(in_features=100, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x
from paddle.metric import Accuracy
model = paddle.Model(LeNet()) # 用Model封装模型
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
model.fit(train_dataset,
epochs=4,
batch_size=128,
verbose=1
)
model.evaluate(test_dataset, batch_size=64, verbose=1)
#读取图片进行预处理
def load_image(infer_path):
image=Image.open(infer_path).convert('L')
image=image.resize((28, 28), Image.ANTIALIAS)
image=np.array(image).reshape(28,28).astype(np.float32)
image=image/255*2-1
#将图片转化为黑白图
for i in range(image.shape[0]):
for j in range(image.shape[1]):
if image[i][j]>0.1:
image[i][j]=-1
else:
image[i][j]=1
plt.imshow(image.reshape(28,28),cmap='gray')
plt.show()
return image.reshape(1,1,28,28)
infer_path='xxxx.jpg'#填写照片路径
#获取图片
test_data, test_label= load_image(infer_path),0
test_data = test_data.reshape([28,28])
plt.figure(figsize=(2,2))
#展示图片
print(plt.imshow(test_data, cmap=plt.cm.binary))
print('test_data 的标签为: ' + str(test_label))
#模型预测
result = model.predict([test_data.reshape(1,1,28,28)])
#打印模型预测的结果
print('预测值为:%d' %np.argmax(result))