版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原
支持向量机(support vector machines,SVM)是一种二类分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划(convex quadratic programming)的问题,也等价于正则化的合页损失函数的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化算法。
支持向量机学习方法包含构建由简至繁的模型:线性可分支持向量机(linear support vector machine in linearly separable case)、线性支持向量机(linear support vector machine)及非线性支持向量机(non-linear vector machine)。简单模型是复杂模型的基础,也是复杂模型的特殊情况。当训练数据线性可分时,通过硬间隔最大化(hard margin maximization),学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机;当训练数据近似线性可分时,通过软间隔最大化(soft margn maximization),也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;当训练数据线性不可分时,通过使用核技巧(kernel trick)及软间隔最大化,学习非线性支持向量机。
——《统计学习方法》P95P95
优点:泛化错误率低,计算开销不大,结果易解释。
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二分类问题。
适用数据类型:数值型和标称型数据。
——《机器学习实战》P89P89
给定线型可分训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为:
Φ(x)Φ(x)。
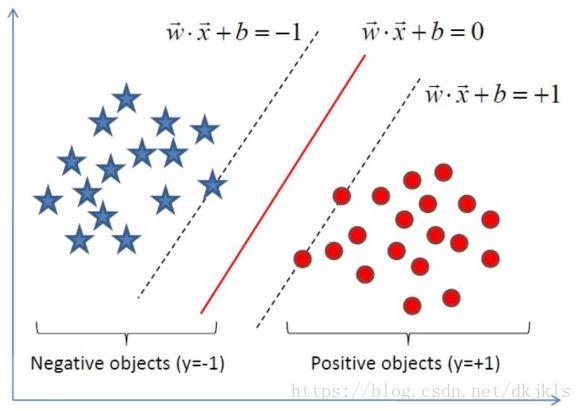
对于上图所示的二分类问题,线性可分支持向量机学习的目标是在特征空间中找到一个分离超平面,然而存在无穷个分离超平面可将两类数据正确分开;线性可分支持向量机则是利用间隔最大化求最优分离超平面,解是唯一的,图中的红色直线即为求解得到的最优分离超平面,将实例分到不同的类。
线性可分支持向量机中的间隔最大化又称为硬间隔最大化(与下面小节的软间隔最大化相对应)。
间隔最大化的直观解释是:对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类。也就是说,不仅将正负实例点分开,而且对最难分的实例点(离超平面最近的点)也有足够大的确信度将它们分开。这样的超平面应该对未知的新实例有很好的分类预测能力。
支持向量(support vector):训练数据集的样本点中与分离超平面距离最近的样本点的实例。上图中两条虚线上的三个点即为支持向量。约束条件为:
间隔边界:支持向量所在的两个超平面。
间隔(margin):间隔边界之间的距离。其值为2||ω||2||ω||。
在决定分离超平面时只有支持向量起作用,而其他实例点并不起作用、如果移动支持向量将改变所求的解;但是如果在间隔边界以外移动其他实例点,甚至去掉这些点,则解是不会改变的。由于支持向量在确定分离超平面中起着决定性作用,所以将这种分类模型称为支持向量机。支持向量的个数一般很少.所以支持向量机由很少的“重要的”训练样本确定。
输入:线型可分训练集T={(x1,y1),(x2,y2),...,(xN,yN)}T={(x1,y1),(x2,y2),...,(xN,yN)}
输出:分离超平面和分类决策树
(1)构造并求解约束最优化问题
(2)计算
对于线性可分问题,上述线性可分支持向量机的学习(硬间隔最大化)算法是完美的。但是,训练数据集线性可分是理想的情形。在现实问题中,训练数据集往往是线性不可分的,即在样本中出现噪声或特异点。这就需要将硬间隔最大化,改为软间隔最大化,允许支持向量机在一些样本上出错。
对每个样本点(xi,yi)(xi,yi)
这里,C>0称为惩罚参数,一般由应用问题决定。
C越大,训练精度会变高,有可能过拟合,过渡带宽度越来越小。
软间隔的支持向量或者在间隔边界上,或者在间隔边界与分离超平面之间,或者在分离超平面误分一侧。若α∗i<Cαi∗
然而,0/1损失函数非凸、非连续,数学性质不太好,使得ζiζi不易直接求解。于是,人们通常用其他一些函数来代替 0/1损失函数, 称为”替代损失” (surrogate loss)。替代损失函数一般具有较好的数学性质,如它们通常是凸的连续函数且是 0/1损失函数的上界。下图给出了三种常用的替代损失函数:
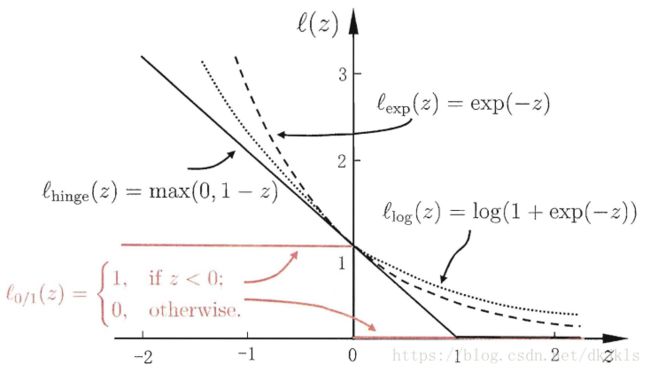
由图可知,”替代损失”不仅要分类正确,而且确信度足够高时损失才是0,也就是说,对学习有更高的要求。
输入:线型可分训练集T={(x1,y1),(x2,y2),...,(xN,yN)}T={(x1,y1),(x2,y2),...,(xN,yN)}
输出:分离超平面和分类决策树
(1)选择惩罚参数C>0,构造并求解凸二次规划问题