背景描述
当下越来越多的企业正在拥抱k8s,如笔者公司基本所有服务都已容器化部署。
容器化场景下,ingress是一种通过http协议暴露k8s内部服务的api对象,也就是说ingress是k8s集群所有服务的访问入口。基于ingress的流量访问链路如下图所示:

ingress解决方案不少,k8s默认推荐的是Nginx Ingress,这也是本篇文章的主角。
7.18 线上服务504
7.18号晚上21点左右,笔者正在小区楼下跳绳(中年码农大肚子危机),看到工作群反馈有业务晚上19点左右出现大量504。业务同学和SRE进行了初步排查分析,19点左右业务有发版,发现问题后也执行了回滚操作;排查发现Nginx ingress转发请求到了不存在的pod IP。难道是Nginx ingress同步上游节点IP有异常,期间也重启了上游服务,问题未解决,19点30分左右,业务恢复。
查询Nginx ingress访问日志,18点49分业务开始出现504,请求响应时间5秒(proxy_connect_timeout 5s),Nginx ingress返回504。另外,18点49分之前(HTTP 200)请求的上游服务IP,与18点49分之后(HTTP 504)请求的上游IP相同。
18点49分业务服务出现异常了?容器同学查询监控发现,该服务在18点49分重新调度了,也就是说,18点49分上游服务的IP已经变了,老的IP地址不可访问了,所以服务才出现504。
kibana查询7.18号19点左右访问日志,发现不止这一个服务504,还有一个服务也出现大量504,而且现象完全一致。两个服务都是19:31分左右恢复。
pod已重新调度,Nginx ingress为什么没有更新上游服务IP?
查找线上环境nginx-ingress-controller日志,发现日志采集(多种日志格式采集到一个topic,解析时可能丢弃了部分日志)有些问题,kibana查询不到有效日志。排查陷入僵局。
7.19 Nginx ingress技术调研
由于之前从来没有接触过Nginx ingress,也不了解其配置同步逻辑,7.19号决定简单研究下Nginx ingress底层原理,以备不时之需。
github地址为 https://github.com/kubernetes... 。服务启动后,包含两个进程:1)nginx-ingress-controller进程基于Golang实现,负责监听k8s ingress资源,转换生成nginx.conf配置文件;2)nginx进程其实就是openresty,另外还基于lua提供本地接口,用于更新上游服务IP。
6 www-data 13h34 /nginx-ingress-controller --configmap=default/nginx-test-config --ingress-class=nginx-test
68 www-data 0:15 nginx: master process /usr/local/nginx/sbin/nginx -c /etc/nginx/nginx.confnginx-ingress-controller同步的配置主要可以分为下面两类:
- ingress规则,需要转化为server + location配置,而且需要注意的是,所有服务的ingress配置最终转换合并到一个配置文件nginx.conf,导致这个文件非常大,一般至少几十万行。另外,这类配置的变更是需要reload nginx进程的。
- 上游服务IP,nginx-ingress-controller监听endpoints,并通过本地接口通知nginx进程,更新上游服务IP地址(http://127.0.0.1:10246/config...)。
查看nginx.conf配置,configuration接口访问日志没有打开,无法确定当时nginx-ingress-controller有没有通过这个接口更新上游IP。
另外由于日志采集问题,也无法查看nginx-ingress-controller日志,7.18号问题,只能靠猜测了。。。只是心里隐隐有点好奇,为什么两个服务都是在7.18号晚19:31恢复正常?那一时刻发生什么了?难道这起case是容器平台造成的?
7.21 测试环境502
7.21号中午12点左右,测试容器平台和网关平台白屏,调试发现,前端某静态资源获取异常,前端伙伴排查修复。
7.21号下午14:10分,反馈容器平台和网关平台前端所有接口请求全部502。kibana查询网关日志,发现全部是Nginx ingress返回502。
502不是网关造成的,继续协助容器团队排查吧,毕竟网关团队在分析5xx问题是比较有经验的。登录测试环境Nginx ingress所在节点(还好之前排查问题申请过节点权限,而ingress访问日志kibana貌似没有采集),grep异常服务访问日志。
7.21号下午15点左右,初步确定原因,与7.18号情况类似,Nginx ingress请求的上游服务IP是错误的。
//error日志如下
connect() failed (113: host is unreachable) while connecting to upstream, upstream: http://xxxx:80/
//access日志记录了上游服务的ingressName,serviceName
//查询上游服务endpoints
kubectl get endpoints xxxx -n xxxx上游服务的IP为什么又是错误的?nginx-ingress-controller配置同步有异常了?那好吧,重启下上游服务试试。
重启了两次,还是没有恢复,502异常。
7.21号下午15:10分左右,既然已经确定nginx-ingress-controller同步配置异常,要不重启下Nginx ingress?即使配置比较多,理论上分钟内也可以重建配置。(事后证明,理论果然只是理论)
7.21号下午15:15分重启两个Nginx ingress节点,重启成功后,故障彻底扩散了,大量服务404。(PS 这时候还被业务方调侃了,经过两小时的努力,502变404了)
404大概率是丢了配置,网关查询404域名,查看Nginx ingress配置文件nginx.conf,发现两个配置文件都丢失了部分域名配置。
这些域名的ingress丢了?但是查询发现ingress正常啊,而且查看nginx-ingress-controller启动日志(记录所有资源变更事件),确实获取到了该域名的ingress,为什么会丢失配置呢?是不是重启异常了?要不然再重启一次。
再看看Nginx ingress节点监控,发现一个节点负载非常高,难道是这个原因吗?
时间已经到了下午16点多了,重启下Nginx ingress节点吧,数分钟后,节点重启成功,Nginx ingress服务重启成功。
7.21号下午16:30分左右,业务基本恢复正常,但是还存在部分404请求,发现请求都是在另一个节点(未重启节点)上,网关修改upstream,摘掉该节点,业务完全恢复。
一个下午就这么心惊胆战的度过了,而事故的原因依然未知。。。
7.22 深入分析
7.21号测试环境故障依然是一个迷,事后想想和7.18线上问题非常类似。另外,为什么Nginx ingress重启会丢失大量配置呢?下次要再发生类似的问题怎办么?依然束手无策吗?
只能再去深入研究nginx-ingress-controller配置同步逻辑了。
//ingress-nginx/internal/ingress/controller/controller.go
func (n *NGINXController) syncIngress(interface{}) error {
//获取所有ingress规则
ings := n.store.ListIngresses
//配置转化,包括上游IP配置
pcfg := n.getConfiguration(ings)
if 非纯upstream节点变更 {
klog.Infof("Configuration changes detected, backend reload required.")
//更新nginx.conf
if 更新失败 {
klog.Errorf("Unexpected failure reloading the backend:\n%v", err)
return err
}
klog.Infof("Backend successfully reloaded.")
}
//更新upstream节点配置(接口方式)
if 更新失败 {
klog.Warningf("Dynamic reconfiguration failed: %v", err)
}
}同步配置都有记录详细的日志,7.21号测试环境可以查询日志,那一条一条日志搜索呗。此时也发现原来日志已采集,可以在kibana搜索。
果然,搜索到了大量的"Configuration changes detected, backend reload required",然后搜索对应的"Backend successfully reloaded"却只有寥寥几条日志。那就是更新配置失败了,再搜索"Unexpected failure reloading the backend",果然有很多。但是这条日志后面的换行符是什么鬼,err关键词到底是什么,该怎么搜索。
细化时间线,放宽筛选条件,一条一条日志找找看,果然,找到了对应的错误信息:
nginx: [emerg] "underscores_in_headers" directive is not allowed here in /tmp/nginx-cfg185859647:251712原来是nginx.conf语法错误,而且所有ingress配置会打包为一个配置文件,只要出现语法错误,那么所有后续所有ingress变更,以及upstream变更,都无法同步。
这是什么配置,为什么会语法错误呢?看一下这个配置的官方说明,以及生成nginx.conf的模板:
Syntax: underscores_in_headers on | off;
Default:
underscores_in_headers off;
Context: http, server
//只能配置在http以及server,不能配置在location
//模板
http {
underscores_in_headers {{ if $cfg.EnableUnderscoresInHeaders }}on{{ else }}off{{ end }};
//生成server配置
{{ range $server := $servers }}
server {
}
{{ end }}
}出问题的配置underscores_in_headers只在模板里http配置块有啊,只能是转化ingress生成server时引入的,而且一定是在location配置块引入的。
更改nginx.conf配置还有两种方式:1)修改configmap,检查了下configma配置,没有异常,而且这个一般不会变更,暂时跳过;2)ingress变更引起,大概率就是了。
那么到底是哪一个ingress引入的呢?按关键字"underscores_in_headers"搜索7.21号下午日志,突然发现在14点出问题之前,就有大量报错。扩大搜索时间范围,发现语法错误在7.21号11:57就出现了。
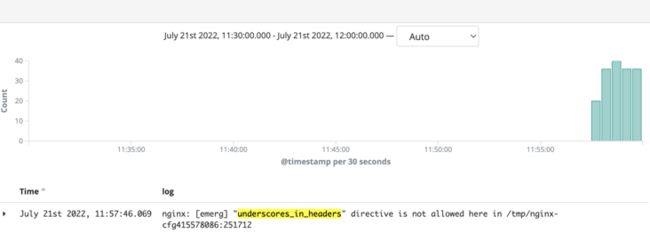
既然确定了7.21号11:57第一次出现语法错误,而且这个语法错误肯定是ingress变更引起的,那么只需要查找ingress变更记录就行了。找一个测试服务,打开浏览器调试模式,提交ingress变更,抓到接口地址,kibana搜索11:57分左右的ingress变更日志。
还真找到了,7.21号11:57分有业务编辑ingress,提交配置如下:
nginx.ingress.kubernetes.io/configuration-snippet":"underscores_in_headers on;"原来是通过注解方式引入的。查看官方文档对这个注解的解释:
//using this annotation you can add additional configuration to the NGINX location. For example:
yaml
nginx.ingress.kubernetes.io/configuration-snippet: |
more_set_headers "Request-Id: $req_id";终于水落石出了,这个注解的配置会生成在location,而恰恰underscores_in_headers是不允许出现在location的!
再扩大时间范围,搜索这个ingress的变更记录,7.21号下午16:30分变更,删掉了这个注解。原来如此,16:30分故障恢复也是一个巧合!至于16:30分后还出现部分404,是因为另一个节点没有重启,事件处理是有序串行的,之前处理异常的事件还在消费,即使不摘除过一会也会恢复的。
至此,真相大白。
7.18 问题回顾
7.21号问题算是搞清楚了。那么7.18号线上问题呢,是否也是如此?赶紧查询线上日志,不幸的是日志已经清除,kibana也查不到了。
幸运的是,想起来机器上一般还会压缩存储钱前几天的日志。网关也就10个节点左右,一个节点一个节点登录看一下呗。这里查什么呢?依然是无法查询nginx-ingress-controller的日志,但是还记得不,7.18号晚31分两个服务同时恢复,那么如果问题同测试环境,一定是那一时刻ingress变更导致的恢复。
历尽千山万水,终于找到了日志:
//2022-07-18T19:31:53+08:00,找到一条ingress变更记录;
//参照ingressName,查找7.18号19点之前变更历时
//2022-07-18T18:29:51+08:00
"nginx.ingress.kubernetes.io/proxy-next-upstream":"on"Syntax: proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | non_idempotent | off ...;
Default:
proxy_next_upstream error timeout;
Context: http, server, locationproxy_next_upstream配置的值不是简单的on!就是他导致的上游IP同步失败,而7.18号晚19点左右,恰好有两个服务重新调度了,IP改变了,所以才504。
这么看来,7.21号测试环境问题也带来了正向收益,不然难以定位到7.18号线上问题的根本原因。而且这个问题还是个不定时炸弹,谁知道什么时候会再发生,下次发生又会引起多大故障!
反思总结
- 理论果然只是理论,现实往往更残酷,理论上认为重启会重新构建配置,可以解决问题,但是重启却反而扩大了故障面;
- 重启不能万能的,在重启之前要认真评估分析重启恢复的可能性;
- 所有的开源组件,不能只是简单使用,平时应该积累,探究其底层原理,不然真正遇到问题将束手无策;特别是系统的核心依赖组件!
- 核心系统/组件一定要有预案,分析可能出现的情况,提前制定一些止损手段,不然等故障发生了,干瞪眼吗?
- 日志采集非常重要,遇到问题没有日志,难道靠猜吗?
- 不要放过任何一个问题,7.18号线上问题,7.21号测试环境问题,如果没有排查出根因,谁知道什么时候会再次发生?下次会不会引起更大范围事故呢?
附录
- ingress:https://kubernetes.io/zh-cn/d...
- Nginx ingress:https://github.com/kubernetes...
- endpoints:https://kubernetes.io/zh-cn/d...
- 官方文档:https://kubernetes.github.io/...
- kubectl:https://kubernetes.io/zh-cn/d...
- Nginx config: http://nginx.org/en/docs/diri...