新鲜出炉的 yoloV5可视化实战项目(1)
文章目录
- 闲谈
- 展示效果
- 开始
- 改装
- 可视化工具
-
- 界面制作
- 逻辑交互制作
- 关键函数detect
- 模型的初始化和权重参数的加载
- 设置图片识别
- 视频和摄像头
- 知识点
- 完整的代码
- 演示效果
闲谈
-
了解到目标检测算法,越来越觉得有意思,希望能做一些更有趣的东西,发现yolov5是个非常牛逼的框架,做点东西实践下,顺便记录下学习的历程,方便复习。
-
可以到官网下载版本, 目前已更新到v7版本,我们还是用v5版本
-
本项目的代码已上传至github点击前往
-
如遇到问题或疑问,可以直接留言或私信
-
祝大家学习愉快
展示效果
B站效果展示
开始
- 一般官网的代码会比较完整,需要做一些修改才能符合我们的需求
- 下载完官网的项目后,直接运行安装依赖即可
pip install -r requirements.txt
- 安装完运行
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
- 方案二
python detect.py --source data/images/bus.jpg


改装
- 制作一个可视化的界面
- 编写detect.py文件
- 逻辑关联处理
可视化工具
- 我们这里用的是pyqt5的工具
- 关于pyqt5 可以参考这个教程,写的很好了 前往
界面制作
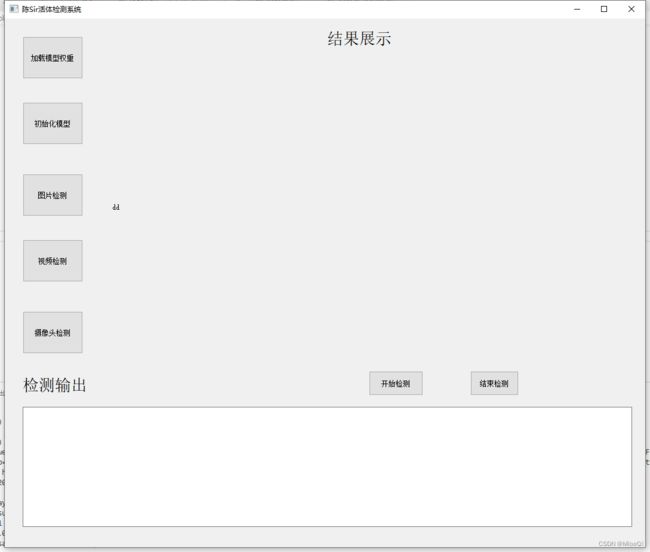
做完大概长这样
逻辑交互制作
def init_slots(self):
self.ui.imgScan.clicked.connect(self.button_image_open)
self.ui.videoScan.clicked.connect(self.button_video_open)
self.ui.capScan.clicked.connect(self.button_camera_open)
self.ui.loadWeight.clicked.connect(self.open_model)
self.ui.initModel.clicked.connect(self.model_init)
self.ui.start.clicked.connect(self.toggleState)
self.ui.end.clicked.connect(self.endVideo)
# self.ui.pushButton_stop.clicked.connect(self.button_video_stop)
# self.ui.pushButton_finish.clicked.connect(self.finish_detect)
self.timer_video.timeout.connect(self.show_video_frame) # 定时器超时,将槽绑定至show_video_frame
- 这部分很简单就是绑定下函数, 这里制作了一个读取视频的定时器,方便控制视频的读取
关键函数detect
- 这个是本项目的关键代码,核心代码,其他的都只能是辅助,同时也是最难的部分。
def detect(self, name_list, img):
'''
:param name_list: 文件名列表
:param img: 待检测图片
:return: info_show:检测输出的文字信息
'''
showimg = img
# 不使用图计算
with torch.no_grad():
# 填充为标准的大小,letterbox 不同于resize, 使用的是边缘填充
img = letterbox(img, new_shape=self.opt.img_size)[0]
# Convert
# 转换成Rgb模式
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
# 转换成连续的内存格式,加快计算速度
img = np.ascontiguousarray(img)
# 图和ndarray的转换,并制定cpu或gpu
img = torch.from_numpy(img).to(self.device)
# 设置精度
img = img.half() if self.half else img.float() # uint8 to fp16/32
# 归一化
img /= 255.0 # 0 - 255 to 0.0 - 1.0
# 统一格式
if img.ndimension() == 3:
# 增加一个维度
img = img.unsqueeze(0)
# Inference
# 使用模型预测
pred = self.model(img, augment=self.opt.augment)[0]
# Apply NMS
# 非极大值抑制
pred = non_max_suppression(pred, self.opt.conf_thres, self.opt.iou_thres, classes=self.opt.classes,
agnostic=self.opt.agnostic_nms)
info_show = ""
# Process detections
for i, det in enumerate(pred):
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], showimg.shape).round()
for *xyxy, conf, cls in reversed(det):
label = '%s %.2f' % (self.names[int(cls)], conf)
name_list.append(self.names[int(cls)])
single_info = plot_one_box2(xyxy, showimg, label=label, color=self.colors[int(cls)], line_thickness=2)
# print(single_info)
info_show = info_show + single_info + "\n"
return info_show
- 具体的都有注释
模型的初始化和权重参数的加载
- 权重加载
def open_model(self):
self.openfile_name_model, _ = QFileDialog.getOpenFileName(self, '选择权重文件', directory='./yolov5\yolo\YoloV5_PyQt5-main\weights')
print(self.openfile_name_model)
if not self.openfile_name_model:
# QtWidgets.QMessageBox.warning(self, u"Warning" u'未选择权重文件,请重试', buttons=QtWidgets.QMessageBox.Ok)
self.log("warining 未选择权重文件,请重试")
else :
print(self.openfile_name_model)
self.log("权重文件路径为:%s"%self.openfile_name_model)
pass
- 模型加载
def model_init(self):
# 模型相关参数配置
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='weights/yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.25, help='IOU threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--save', default=False, help='save video to local')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
self.opt = parser.parse_args()
print(self.opt)
# 使用模型的默认参数
source, self.weights, imgsz = self.opt.source, self.opt.weights, self.opt.img_size
# 若有配置自定义权重,
if hasattr(self, "openfile_name_model") and self.openfile_name_model.endswith('.pt'):
self.weights = self.openfile_name_model
self.log('记载自定义权重成功')
else :
self.log('warning:权重文件有误,请重新加载')
# 选择cpu 和gpu
self.device = select_device(self.opt.device)
self.half = self.device.type != 'cpu'
cudnn.benchmark = True
# Load model
self.model = attempt_load(self.weights, map_location=self.device)
stride = int(self.model.stride.max()) # model stride
self.imgsz = check_img_size(imgsz, s=stride) # check img_size
if self.half:
self.model.half() # to FP16
# Get names and colors
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names]
QtWidgets.QMessageBox.information(self, u"Notice", u"模型加载完成", buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
self.log('模型加载完成')
设置图片识别
def button_image_open(self):
print('button_image_open')
name_list = []
try:
img_name, _ = QtWidgets.QFileDialog.getOpenFileName(self, "选择文件")
except OSError as reason:
print('文件出错啦')
QtWidgets.QMessageBox.warning(self, 'Warning', '文件出错', buttons=QtWidgets.QMessageBox.Ok)
else:
if not img_name:
QtWidgets.QMessageBox.warning(self,"Warning", '文件出错', buttons=QtWidgets.QMessageBox.Ok)
self.log('文件出错')
else:
img = cv.imread(img_name)
info_show = self.detect(name_list, img)
date = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time())) # 当前时间
file_extaction = img_name.split('.')[-1]
new_fileName = date + '.' + file_extaction
file_path = self.output_folder + 'img_output/' + new_fileName
cv.imwrite(file_path, img)
self.show_img(info_show, img)
# self.log(info_show) #检测信息
# self.result = cv.cvtColor(img, cv.COLOR_BGR2BGRA)
# self.result = letterbox(self.result, new_shape=self.opt.img_size)[0] #cv.resize(self.result, (640, 480), interpolation=cv.INTER_AREA)
# self.QtImg = QtGui.QImage(self.result.data, self.result.shape[1], self.result.shape[0], QtGui.QImage.Format_RGB32)
# print(type(self.ui.show))
# self.ui.show.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
# self.ui.show.setScaledContents(True) # 设置图像自适应界面大小
视频和摄像头
def button_video_open(self):
video_path, _ = QtWidgets.QFileDialog.getOpenFileName(self, '选择检测视频', filter="*.mp4;;*.avi;;All Files(*)")
flag = self.cap.open(video_path)
if not flag:
QtWidgets.QMessageBox.warning(self,"Warning", '打开视频失败', buttons=QtWidgets.QMessageBox.Ok)
else:
self.timer_video.start(1000/self.cap.get(cv.CAP_PROP_FPS)) # 以30ms为间隔,启动或重启定时器
if self.opt.save:
fps, w, h, path = self.set_video_name_and_path()
self.vid_writer = cv.VideoWriter(path, cv.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
def button_camera_open(self):
camera_num = 0
self.cap = cv.VideoCapture(camera_num)
if not self.cap.isOpened():
QtWidgets.QMessageBox.warning(self, u"Warning", u'摄像头打开失败', buttons=QtWidgets.QMessageBox.Ok)
else:
self.timer_video.start(1000/60)
if self.opt.save:
fps, w, h, path = self.set_video_name_and_path()
self.vid_writer = cv.VideoWriter(path, cv.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
知识点
- 图片的显示用qlabel就可以了
def show_img(self, info_show, img):
self.log(info_show)
show = cv.resize(img, (640, 480)) # 直接将原始img上的检测结果进行显示
self.result = cv.cvtColor(show, cv.COLOR_BGR2RGB)
self.result = letterbox(self.result, new_shape=self.opt.img_size)[0]
showImage = QtGui.QImage(self.result.data, self.result.shape[1], self.result.shape[0],
QtGui.QImage.Format_RGB888)
self.ui.show.setPixmap(QtGui.QPixmap.fromImage(showImage))
self.ui.show.setScaledContents(True) # 设置图像自适应界面大小
完整的代码
import argparse
import random
import sys
import time
import torch
from PyQt5.QtWidgets import *
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QApplication,QMainWindow
import name
from functools import partial
from utils.torch_utils import select_device
import torch.backends.cudnn as cudnn
import cv2 as cv
from utils.datasets import letterbox
from utils.plots import plot_one_box2
import numpy as np
from models.experimental import attempt_load
from utils.general import check_img_size, non_max_suppression, scale_coords
# pyuic5 -o name.py test.ui
class UI_Logic_Window(QtWidgets.QMainWindow):
def __init__(self, parent = None):
super(UI_Logic_Window, self).__init__(parent)
self.timer_video = QtCore.QTimer() # 创建定时器
#创建一个窗口
self.w = QMainWindow()
self.ui = name.Ui_MainWindow()
self.ui.setupUi(self)
self.init_slots()
self.output_folder = 'output/'
self.cap = cv.VideoCapture()
# 日志
self.logging = ''
# 控件绑定相关操作
def init_slots(self):
self.ui.imgScan.clicked.connect(self.button_image_open)
self.ui.videoScan.clicked.connect(self.button_video_open)
self.ui.capScan.clicked.connect(self.button_camera_open)
self.ui.loadWeight.clicked.connect(self.open_model)
self.ui.initModel.clicked.connect(self.model_init)
self.ui.start.clicked.connect(self.toggleState)
self.ui.end.clicked.connect(self.endVideo)
# self.ui.pushButton_stop.clicked.connect(self.button_video_stop)
# self.ui.pushButton_finish.clicked.connect(self.finish_detect)
self.timer_video.timeout.connect(self.show_video_frame) # 定时器超时,将槽绑定至show_video_frame
def button_image_open(self):
print('button_image_open')
name_list = []
try:
img_name, _ = QtWidgets.QFileDialog.getOpenFileName(self, "选择文件")
except OSError as reason:
print('文件出错啦')
QtWidgets.QMessageBox.warning(self, 'Warning', '文件出错', buttons=QtWidgets.QMessageBox.Ok)
else:
if not img_name:
QtWidgets.QMessageBox.warning(self,"Warning", '文件出错', buttons=QtWidgets.QMessageBox.Ok)
self.log('文件出错')
else:
img = cv.imread(img_name)
info_show = self.detect(name_list, img)
date = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time())) # 当前时间
file_extaction = img_name.split('.')[-1]
new_fileName = date + '.' + file_extaction
file_path = self.output_folder + 'img_output/' + new_fileName
cv.imwrite(file_path, img)
self.show_img(info_show, img)
# self.log(info_show) #检测信息
# self.result = cv.cvtColor(img, cv.COLOR_BGR2BGRA)
# self.result = letterbox(self.result, new_shape=self.opt.img_size)[0] #cv.resize(self.result, (640, 480), interpolation=cv.INTER_AREA)
# self.QtImg = QtGui.QImage(self.result.data, self.result.shape[1], self.result.shape[0], QtGui.QImage.Format_RGB32)
# print(type(self.ui.show))
# self.ui.show.setPixmap(QtGui.QPixmap.fromImage(self.QtImg))
# self.ui.show.setScaledContents(True) # 设置图像自适应界面大小
def show_img(self, info_show, img):
self.log(info_show)
show = cv.resize(img, (640, 480)) # 直接将原始img上的检测结果进行显示
self.result = cv.cvtColor(show, cv.COLOR_BGR2RGB)
self.result = letterbox(self.result, new_shape=self.opt.img_size)[0]
showImage = QtGui.QImage(self.result.data, self.result.shape[1], self.result.shape[0],
QtGui.QImage.Format_RGB888)
self.ui.show.setPixmap(QtGui.QPixmap.fromImage(showImage))
self.ui.show.setScaledContents(True) # 设置图像自适应界面大小
def toggleState(self):
print('toggle')
state = self.timer_video.signalsBlocked()
self.timer_video.blockSignals(not state)
text = '继续' if not state else '暂停'
self.ui.start.setText(text)
def endVideo(self):
print('end')
self.timer_video.blockSignals(True)
self.releaseRes()
def detect(self, name_list, img):
'''
:param name_list: 文件名列表
:param img: 待检测图片
:return: info_show:检测输出的文字信息
'''
showimg = img
# 不使用图计算
with torch.no_grad():
# 填充为标准的大小,letterbox 不同于resize, 使用的是边缘填充
img = letterbox(img, new_shape=self.opt.img_size)[0]
# Convert
# 转换成Rgb模式
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
# 转换成连续的内存格式,加快计算速度
img = np.ascontiguousarray(img)
# 图和ndarray的转换,并制定cpu或gpu
img = torch.from_numpy(img).to(self.device)
# 设置精度
img = img.half() if self.half else img.float() # uint8 to fp16/32
# 归一化
img /= 255.0 # 0 - 255 to 0.0 - 1.0
# 统一格式
if img.ndimension() == 3:
# 增加一个维度
img = img.unsqueeze(0)
# Inference
# 使用模型预测
pred = self.model(img, augment=self.opt.augment)[0]
# Apply NMS
# 非极大值抑制
pred = non_max_suppression(pred, self.opt.conf_thres, self.opt.iou_thres, classes=self.opt.classes,
agnostic=self.opt.agnostic_nms)
info_show = ""
# Process detections
for i, det in enumerate(pred):
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], showimg.shape).round()
for *xyxy, conf, cls in reversed(det):
label = '%s %.2f' % (self.names[int(cls)], conf)
name_list.append(self.names[int(cls)])
single_info = plot_one_box2(xyxy, showimg, label=label, color=self.colors[int(cls)], line_thickness=2)
# print(single_info)
info_show = info_show + single_info + "\n"
return info_show
def button_video_open(self):
video_path, _ = QtWidgets.QFileDialog.getOpenFileName(self, '选择检测视频', filter="*.mp4;;*.avi;;All Files(*)")
flag = self.cap.open(video_path)
if not flag:
QtWidgets.QMessageBox.warning(self,"Warning", '打开视频失败', buttons=QtWidgets.QMessageBox.Ok)
else:
self.timer_video.start(1000/self.cap.get(cv.CAP_PROP_FPS)) # 以30ms为间隔,启动或重启定时器
if self.opt.save:
fps, w, h, path = self.set_video_name_and_path()
self.vid_writer = cv.VideoWriter(path, cv.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
def set_video_name_and_path(self):
# 获取当前系统时间,作为img和video的文件名
now = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime(time.time()))
# if vid_cap: # video
fps = self.cap.get(cv.CAP_PROP_FPS)
w = int(self.cap.get(cv.CAP_PROP_FRAME_WIDTH))
h = int(self.cap.get(cv.CAP_PROP_FRAME_HEIGHT))
# 视频检测结果存储位置
save_path = self.output_folder + 'video/' + now + '.mp4'
return fps, w, h, save_path
def button_camera_open(self):
camera_num = 0
self.cap = cv.VideoCapture(camera_num)
if not self.cap.isOpened():
QtWidgets.QMessageBox.warning(self, u"Warning", u'摄像头打开失败', buttons=QtWidgets.QMessageBox.Ok)
else:
self.timer_video.start(1000/60)
if self.opt.save:
fps, w, h, path = self.set_video_name_and_path()
self.vid_writer = cv.VideoWriter(path, cv.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
def open_model(self):
self.openfile_name_model, _ = QFileDialog.getOpenFileName(self, '选择权重文件', directory='./yolov5\yolo\YoloV5_PyQt5-main\weights')
print(self.openfile_name_model)
if not self.openfile_name_model:
# QtWidgets.QMessageBox.warning(self, u"Warning" u'未选择权重文件,请重试', buttons=QtWidgets.QMessageBox.Ok)
self.log("warining 未选择权重文件,请重试")
else :
print(self.openfile_name_model)
self.log("权重文件路径为:%s"%self.openfile_name_model)
pass
def model_init(self):
# 模型相关参数配置
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='weights/yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.25, help='IOU threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--save', default=False, help='save video to local')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
self.opt = parser.parse_args()
print(self.opt)
# 使用模型的默认参数
source, self.weights, imgsz = self.opt.source, self.opt.weights, self.opt.img_size
# 若有配置自定义权重,
if hasattr(self, "openfile_name_model") and self.openfile_name_model.endswith('.pt'):
self.weights = self.openfile_name_model
self.log('记载自定义权重成功')
else :
self.log('warning:权重文件有误,请重新加载')
# 选择cpu 和gpu
self.device = select_device(self.opt.device)
self.half = self.device.type != 'cpu'
cudnn.benchmark = True
# Load model
self.model = attempt_load(self.weights, map_location=self.device)
stride = int(self.model.stride.max()) # model stride
self.imgsz = check_img_size(imgsz, s=stride) # check img_size
if self.half:
self.model.half() # to FP16
# Get names and colors
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names]
QtWidgets.QMessageBox.information(self, u"Notice", u"模型加载完成", buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
self.log('模型加载完成')
def show_video_frame(self):
name_list = []
flag, img = self.cap.read()
if img is None:
self.releaseRes()
else:
info_show = self.detect(name_list, img)
if self.opt.save:
self.vid_writer.write(img) # 检测结果写入视频
self.show_img(info_show, img)
def releaseRes(self):
print('读取结束')
self.log('检测结束')
self.timer_video.stop()
self.cap.release() # 释放video_capture资源
self.ui.show.clear()
if self.opt.save:
self.vid_writer.release()
def log(self, msg):
self.logging += '%s\n'%msg
self.ui.log.setText(self.logging)
if __name__=='__main__':
# 创建QApplication实例
app=QApplication(sys.argv)#获取命令行参数
current_ui = UI_Logic_Window()
current_ui.show()
sys.exit(app.exec_())
演示效果

B站效果展示