torch.fx 简介与量化
pytroch发布的torch.fx工具包可以说是很好的消除一些动态图和静态图的Gap,可以使得我们对于nn.Module的各种变化操作变得非常简单。
动态图和静态图:
动态意味着程序将按照我们编写命令的顺序进行执行。这种机制将使得调试更加容易,并且也使得我们将大脑中的想法转化为实际代码变得更加容易。而静态则意味着程序在编译执行时将先生成神经网络的结构,然后再执行相应操作。按照动态图和静态图最明显的两个框架就是pytorch和tensorflow两个。
静态图的优势就在于,因为我们提前获知了模型结构,这就更方便于我们做一些变化,比如量化和算子融合。但是缺点就在于,不够灵活,我们不能随心所欲,天马行空的设计我们的模型结构。而动态图,程序将按照我们编写命令的顺序进行执行。这种机制将使得调试更加容易,并且也使得我们将大脑中的想法转化为实际代码变得更加容易。
最简单的例子比如,tensorflow中没有forward,而pytorch中有forward.
torch.fx
torch,fx,这是一个用于捕获和转换PyTorch程序的纯Python系统。主要分为三个结构块:符号追踪器(symbolic tracer),中间表示(intermediate representation), Python代码生成(Python code generation)。
这三个组件可以做什么?直观看起来,torch.fx做的就是将一个Module转换为静态图。首先,通过追踪器获取到模型的graph,从而产生中间表示,对于中间表示我们做一系列变化,再通过python代码生成来生成python代码。

这段代码在官网上都有:torch.fx — PyTorch 1.10.1 documentation
首先,通过symbolic_traced来跟踪模型,得到模型的graph,我们可以对这个graph做出一系列变化,后通过代码生成得到对应的python代码,来修改网络结构。
这里来看一个修改Module的简单例子,这个例子中我们将模块中所有的操作替换成 torch.mul() :

torch.fx与量化
在torch.fx提出之前,pytorch的量化方式官方称为 Eager Mode Quantization,而随着torch.fx的提出,由于可以动态地 trace 出网络的图结构,因此就可以针对网络模型动态地添加一些量化节点。官方又称这种新的量化方式为 FX Graph Mode Quantization。
两个方式的区别主要在于,Eager Mode Quantization 需要手工修改网络代码,并对很多节点进行替换,而 FX Graph Mode Quantization 则大大提高了自动化的能力。
举个例子:
定义一个网络模型

在Eager Mode Quantization模式下对模型进行量化:

这意味着,我们需要去修改网络结构,同时由于有些节点是要做 fuse 之后才能量化的(比如:Conv + ReLU),因此我们需要手动指定这些层进行合并。
简单的网络还行,一旦复杂,各种天马行空的结构,复杂程度成倍增加。
在FX Graph Mode Quantization。模式下对模型进行量化:
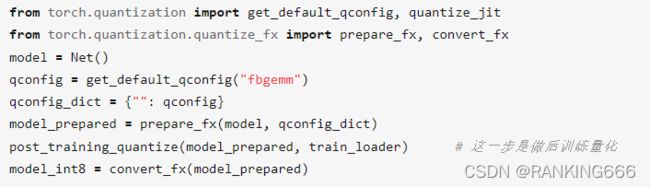
非常简单。
接下来,简单介绍一下代码结构与原理:

pytorch为我们提供了这几种量化方式:
PTQ和QAT就不说了。
模型静态量化:考虑到动态量化的量化方式有时会带来模型预测效果的大幅度下降,因此引入静态量化,它同样发生在模型训练后,为了判断哪些权重或激活值应该被量化,哪些应该保留或小幅度量化,在预测过程开始前,在模型中节点插入“观测者”(衡量节点使用情况的一些计算方法),他们将在一些实验数据中评估节点使用情况,来决定是否将其权重或激活值进行量化,因为在预测过程中,这些节点是否被量化已经确定,因此称作静态量化。
模型动态量化:操作最简单也是压缩效果最好的量化方式,量化过程发生在模型训练后,针对模型权重采取量化,之后会在模型预测过程中,再决定是否针对激活值采取量化,因此称作动态量化(在预测时可能发生量化)
模型静态量化可以分为两种:仅weight量化以及weight与activation同时量化。前者主要目的是使得模型参数所占内存减小,且相对简单。后者则相对较为复杂。
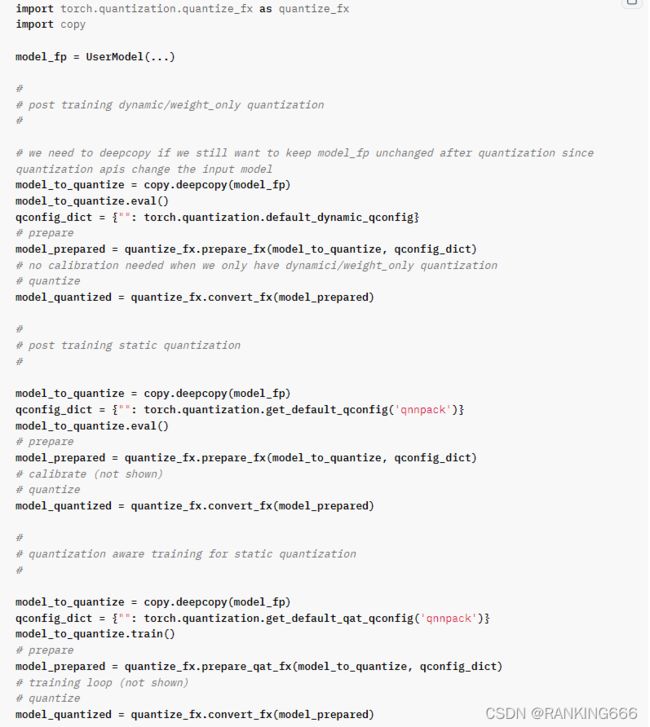
这段是官网给出的例子。
不管是哪种量化方式,代码都差不多。
第一步,也就是模型,没啥可说的。
第二步,qconfig,该步骤目的是设置模型量化的方式,通过插入两个observer来监测activation与weight。同时由于推理平台的不同,pytorch的量化配置也不相同。
 官网上也都有介绍。
官网上也都有介绍。
第三步,prepare,将每个可支持量化的模块插入Observer,收集数据并进行量化分析。
第四步,在激活量化时需要,也就是校准,输入一部分数据来校准激活量化的scale和zeropoint。
第五步,convert,运用代码转化模型。
简单来说:
模型量化后就是量化模型的推理,与浮点模型的区别主要是要进行量化节点的插入以及op替换。
量化节点插入:需要在网络的forward里面插入QuantStub与DeQuantSub两个节点。
op替换:需要将模型中的Add、Concat等操作替换为支持量化的FloatFunctional
如有错误,欢迎各位批评指正!!