Kubernetes:(三)K8s架构及部署
目录
一:K8s架构及流向
二:k8s组件
2.1master组件
2.1.1kube-apiserver
2.1.2kube-controller-manager (控制器管理中心-定义资源类型)
2.1.3kube-scheduler
2.1.4etcd存储中心
2.1.5AUTH :认证模块
2.1.6cloud-controller-manager
2.2node组件
2.2.1kubelet
2.2.2kube-proxy(四层)
2.2.3docker或rocket
三:kubernetes集群环境搭建
3.1 前置知识点
3.1.1kubeadm 部署方式介绍
3.1.2安装要求
3.1.3最终目标
3.2环境准备
3.3环境初始化
3.3.1检查操作系统的版本
3.3.2主机名解析
3.3.3时间同步
3.3.4禁用iptable和firewalld服务
3.3.5禁用selinux
3.3.6禁用swap分区
3.3.7修改linux的内核参数
3.3.8配置ipvs功能
3.3.9安装docker(注意docker 版本要一致)
3.4安装Kubernetes组件
3.5准备集群镜像
3.5.1集群初始化
3.5.2在master上查看节点信息
3.5.3安装网络插件(CNI)
3.5.4给node节点打上“node”的标签
3.5.5查看集群是否健康
3.6集群测试
3.6.1创建一个nginx服务
3.6.2暴露端口
3.6.3查看服务
四:扩展:体验Pod
五: k8s常用命令
六: 总结
一:K8s架构及流向
K8S 也是一个典型的C/S架构,由master端和node端组成
整体流程:
①使用kubectl命令的时候会先进行验证权限(AUTH)
②通过API-server 对容器云的资源进行操作
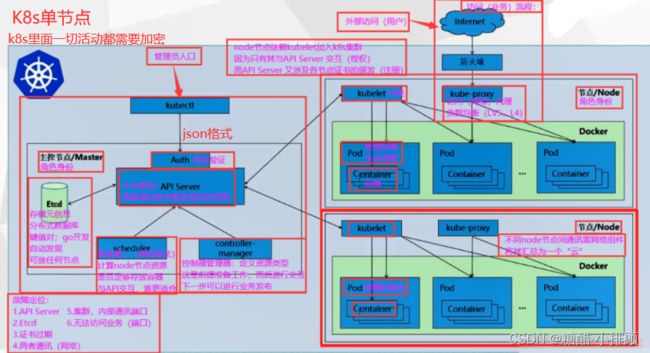
K8S 创建Pod 流程:
kubectl 创建一个Pod(在提交时,转化为json格式)
- 首先经过auth认证(鉴权),然后传递给api-server进行处理
- api-server 将请求信息提交给etcd
- scheduler和controller-manager 会watch(监听) api-server ,监听请求
- 在scheduler 和controller-manager监听到请求后,scheduler 会提交给api-server一个list清单——》包含的是获取node节点信息
- 此时api-server就会向etcd获取后端node节点信息,获取到后,被scheduler watch到,然后进行预选优选进行打分,最后将结果给与api-server
- 此时api-server也会被controller-manager watch(监听) controller-manager会根据请求创建Pod的配置信息(需求什么控制器)将控制器资源给与api-server
- 此时api-server 会提交list清单给与对应节点的kubelet(代理)
- kubelet代理通过K8S与容器的接口(例如containerd)进行交互,假设是docker容器,那么此时kubelet就会通过dockershim 以及runc接口与docker的守护进程docker-server进行交互,来创建对应的容器,再生成对应的Pod
- kubelet 同时会借助于metrics server 收集本节点的所有状态信息,然后再提交给api-server
- 最后api-server会提交list清单给与etcd来存储(最后api-server会将数据维护在etcd中)
简单版:
首先kubectl 转化为json后,向api-server 提交创建Pod请求
api-server将请求信息记录在etcd中
scheduler 监听api-server处理的请求,然后向api-server申请后端节点信息
api-server 从etcd中获取后端节点信息后,给与scheduler
scheduler 进行预选优选、打分,然后提交结果给api-server
controller-manager 监听api-server处理的请求信息,并将所需的控制器资源给与api-server
api-server 对接node节点的kubelet
kubelet调用资源创建pod,并将统计信息返回给api-server
api-server将信息记录在etcd中用户访问流程:
- 假设用户需创建 nginx资源(网站/调度)kubectl ——》auth ——》api-server
- 基于yaml 文件的 kubectl create run / apply -f nginx.yaml(pod 一些属性,pod )
- 请求发送至master 首先需要经过apiserver(资源控制请求的唯一入口)
- apiserver 接收到请求后首先会先记载在Etcd中
- Etcd的数据库根据controllers manager(控制器) 查看创建的资源状态(有无状态化)
- 通过controllers 触发 scheduler (调度器)
- scheduler 通过验证算法() 验证架构中的nodes节点,筛选出最适合创建该资源,接着分配给这个节点进行创建
- node节点中的kubelet 负责执行master给与的资源请求,根据不同指令,执行不同操作
- 对外提供服务则由kube-proxy开设对应的规则(代理)
- container 容器开始运行(runtime 生命周期开始计算)
- 外界用户进行访问时,需要经过kube-proxy -》service 访问到container (四层)
- 如果container 因故障而被销毁了,master节点的controllers 会再次通过scheduler 资源调度通过kubelet再次创建容器,恢复基本条件限制(控制器,维护pod状态、保证期望值-副本数量)
- pod ——》ip 进行更改——》service 定义统一入口(固定被访问的ip:端口)
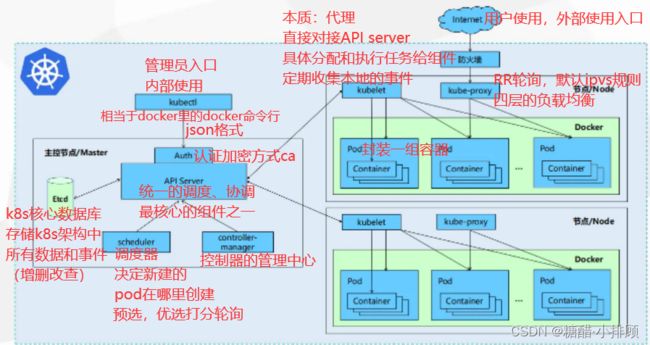
二:k8s组件
2.1master组件
master:集群的控制平面,负责集群的决策 ( 管理 )
2.1.1kube-apiserver
- 用于暴露Kubernetes API,任何资源请求或调用操作都是通过kube-apiserver 提供的接口进行。以HTTP Restful API提供接口服务,所有对象资源的增删改查和监听操作都交给API Server 处理后再提交给Etcd 存储(相当于分布式数据库,以键值对方式存储)。
- 可以理解成API Server 是K8S的请求入口服务。API server 负责接收K8S所有请求(来自UI界面或者CLI 命令行工具),然后根据用户的具体请求,去通知其他组件干活。可以说API server 是K8S集群架构的大脑。
2.1.2kube-controller-manager (控制器管理中心-定义资源类型)
- 运行管理控制器,是k8s集群中处理常规任务的后台线程,是k8s集群里所有资源对象的自动化控制中心。
- 在k8s集群中,一个资源对应一个控制器,而Controller manager 就是负责管理这些控制器的。
- 由一系列控制器组成,通过API Server监控整个集群的状态,并确保集群处于预期的工作状态,比如当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
| 控制器 | 功能 |
| NodeContrpller(节点控制器) | 负责在节点出现故障时发现和响应 |
| Replication Controller ( 副本控制器) | 负责保证集群中一个RC (资源对象ReplicationController) 所关联的Pod副本数始终保持预设值。可以理解成确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量 |
| Endpoints Controller (端点控制器) | 填充端点对象(即连接Services 和Pods) ,负责监听Service 和对应的Pod 副本的变化。可以理解端点是一个服务暴露出来的访问点, 如果需要访问一个服务,则必须知道它的 endpoint |
| Service Account & Token Controllers (服务帐户和令牌控制器) | 为新的命名空间创建默认帐户和API访问令牌 |
| ResourceQuotaController(资源配额控制器) | 确保指定的资源对象在任何时候都不会超量占用系统物理资源 |
| Namespace Controller (命名空间控制器) | 管理namespace的生命周期 |
| Service Controller (服务控制器) | 属于K8S集群与外部的云平台之间的- -个接口控制器 |
2.1.3kube-scheduler
- 根据调度算法(预选/优选的策略)为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
- 可以理解成K8S所有Node 节点的调度器。当用户要部署服务时,scheduler 会根据调度算法选择最合适的Node 节点来部署Pod。
- API Server 接收到请求创建一批Pod,API Server 会让Controller-manager 按照所预设的模板去创建Pod,Controller-manager 会通过API Server去找Scheduler 为新创建的Pod选择最适合的Node 节点。比如运行这个Pod需要2C4G 的资源,Scheduler 会通过预算策略在所有Node节点中挑选最优的。Node 节点中还剩多少资源是通过汇报给API Server 存储在etcd 里,API Server 会调用一个方法找到etcd 里所有Node节点的剩余资源,再对比Pod 所需要的资源,在所有Node 节点中查找哪些Node节点符合要求。
- 如果都符合,预算策略就交给优选策略处理,优选策略再通过CPU的负载、内存的剩余量等因素选择最合适的Node 节点,并把Pod调度到这个Node节点上运行。
- controller manager会通过API Server通知kubelet去创建pod,然后通过kube-proxy中的service对外提供服务接口。(node组件)
2.1.4etcd存储中心
- 分布式键值存储系统(特性:服务自动发现)。用于保存集群状态数据,比如Pod、Service等对象信息
- k8s中仅API Server 才具备读写权限,其他组件必须通过API Server 的接口才能读写数据
PS:etcd V2版本:数据保存在内存中
v3版本:引入本地volume卷的持久化(可根据磁盘进行恢复),服务发现,分布式(方便扩容,缩容)
etcd是一种定时全量备份+持续增量备份的持久化方式,最后存储在磁盘中
但kubernetes 1.11版本前不支持v3,我用的事K8S 1.15
ETCD一般会做为3副本机制(奇数方式),分布在三台master上(也有的公司单独用服务器部署ETCD )
master:奇数的方式部署(多节点的时候)
2.1.5AUTH :认证模块
K8S 内部支持使用RBAC认证的方式进行认证
2.1.6cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器允许您链接集群到云提供商的应用编程接口中, 并把和该云平台交互的组件与只和您的集群交互的组件分离开。
cloud-controller-manager 仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager 将若干逻辑上独立的 控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
– ● 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
– ● 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
– ● 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
2.2node组件
2.2.1kubelet
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器
kubelet —》先和docker引擎进行交互—》docker容器(一组容器跑在Pod中)
2.2.2kube-proxy(四层)
在Node节点上实现Pod网络代理,维护网络规则、pod之间通信和四层负载均衡工作。默认会写入规则至iptables ,目前支持IPVS、同时还支持namespaces
对于七层的负载,k8s官方提供了一种解决方案;ingress-nginx
2.2.3docker或rocket
容器引擎,运行容器
三:kubernetes集群环境搭建
3.1 前置知识点
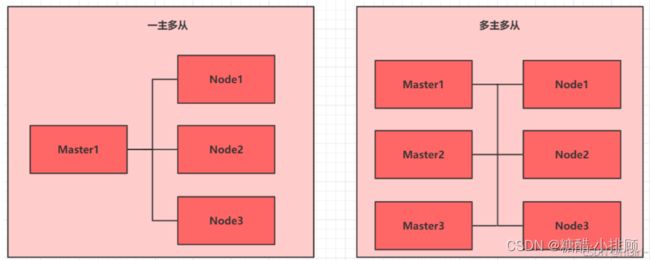
目前生产部署Kubernetes 集群主要有两种方式:
1. kubeadm
Kubeadm 是一个K8s 部署工具,提供 kubeadm init 和 kubeadm join,用于快速部署Kubernetes 集群。
官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
2. 二进制包
从github 下载发行版的二进制包,手动部署每个组件,组成Kubernetes 集群。
Kubeadm 降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes 集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护
3.1.1kubeadm 部署方式介绍
kubeadm 是官方社区推出的一个用于快速部署kubernetes 集群的工具,这个工具能通过两条指令完成一个kubernetes 集群的部署:
- 创建一个Master 节点kubeadm init
- 将Node 节点加入到当前集群中$ kubeadm join
3.1.2安装要求
在开始之前,部署Kubernetes 集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统CentOS7.x-86_x64
- 硬件配置:2GB 或更多RAM,2 个CPU 或更多CPU,硬盘30GB 或更多
- 集群中所有机器之间网络互通
- 可以访问外网,需要拉取镜像
- 禁止swap 分区
3.1.3最终目标
- 在所有节点上安装Docker 和kubeadm
- 部署Kubernetes Master
- 部署容器网络插件
- 部署Kubernetes Node,将节点加入Kubernetes 集群中
- 部署Dashboard Web 页面,可视化查看Kubernetes 资源
3.2环境准备
| 角色 | IP地址 | 组件 |
| master | 192.168.137.20 | docker,kubectl,kubeadm,kubelet |
| node01 | 192.168.137.10 | docker,kubectl,kubeadm,kubelet |
| node02 | 192.168.137.30 | docker,kubectl,kubeadm,kubelet |
3.3环境初始化
3.3.1检查操作系统的版本
cat /etc/redhat-release
#此方式下安装kubernetes集群要求Centos版本要在7.5或之上
3.3.2主机名解析
为了方便集群节点间的直接调用,在这个配置一下主机名解析,企业中推荐使用内部DNS服务器
# 主机名成解析 编辑三台服务器的/etc/hosts文件,添加下面内容
192.168.137.20 master
192.168.137.10 node01
192.168.137.30 node02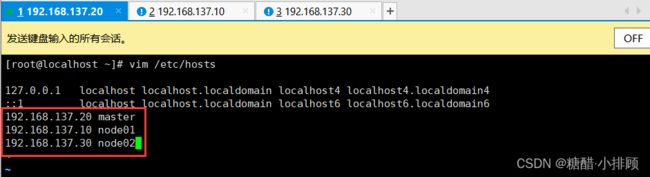
3.3.3时间同步
kubernetes要求集群中的节点时间必须精确一致,这里使用chronyd服务从网络同步时间
企业中建议配置内部的会见同步服务器
#启动chronyd服务
[root@master ~]# systemctl start chronyd
[root@master ~]# systemctl enable chronyd
[root@master ~]# date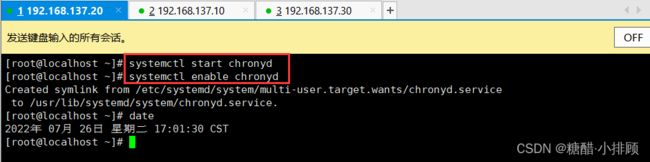
3.3.4禁用iptable和firewalld服务
kubernetes和docker 在运行的中会产生大量的iptables规则,为了不让系统规则跟它们混淆,直接关闭系统的规则
# 1 关闭firewalld服务
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
# 2 关闭iptables服务
[root@master ~]# systemctl stop iptables
[root@master ~]# systemctl disable iptables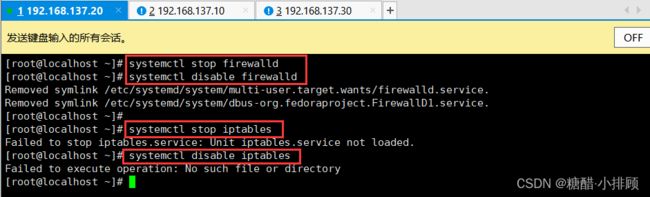
3.3.5禁用selinux
selinux是linux系统一下的一个安全服务,如果不关闭它,在安装集群中会产生各种各样的奇葩问题
#编辑 /etc/selinux/config 文件,修改SELINUX的值为disable
#注意修改完毕之后需要重启linux服务
SELINUX=disabled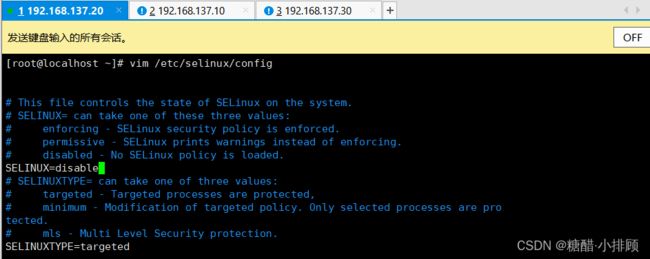
3.3.6禁用swap分区
swap分区值的是虚拟内存分区,它的作用是物理内存使用完,之后将磁盘空间虚拟成内存来使用,启用sqap设备会对系统的性能产生非常负面的影响,因此kubernetes要求每个节点都要禁用swap设备
#编辑分区配置文件/etc/fstab,注释掉swap分区一行
#注意修改完毕之后需要重启linux服务
vim /etc/fstab
注释掉 /dev/mapper/centos-swap swap
# /dev/mapper/centos-swap swap
swapoff -a # 临时关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭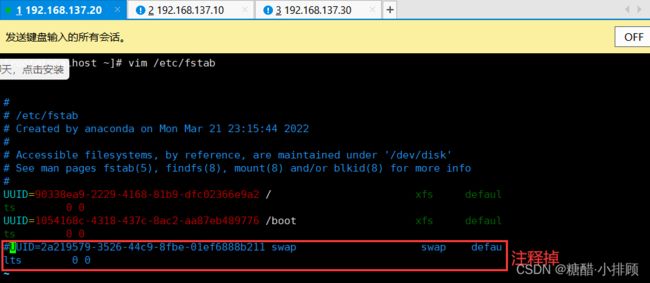
3.3.7修改linux的内核参数
#修改linux的内核采纳数,添加网桥过滤和地址转发功能
#编辑/etc/sysctl.d/kubernetes.conf文件,添加如下配置:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
# 重新加载配置
[root@master ~]# sysctl -p 或者 sysctl --system # 生效
# 加载网桥过滤模块
[root@master ~]# modprobe br_netfilter
# 查看网桥过滤模块是否加载成功
[root@master ~]# lsmod | grep br_netfilter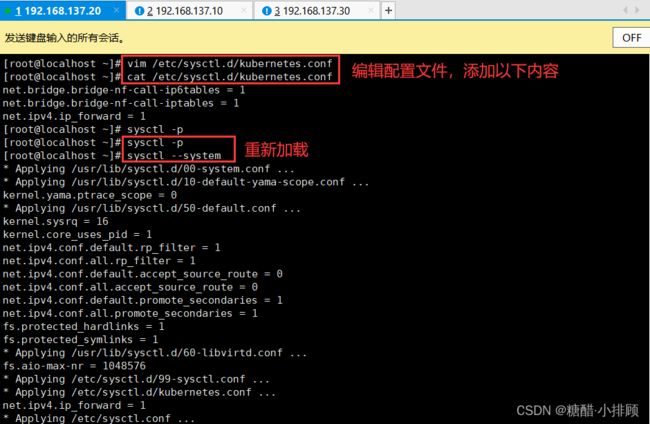

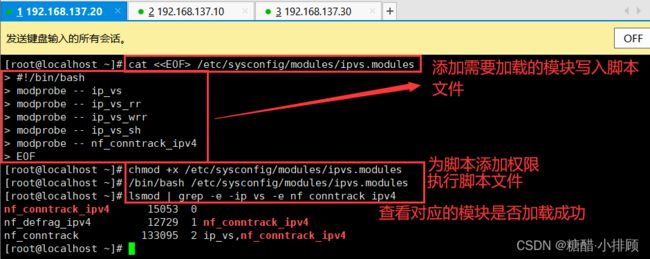
3.3.8配置ipvs功能
在Kubernetes中Service有两种带来模型,一种是基于iptables的,一种是基于ipvs的两者比较的话,ipvs的性能明显要高一些,但是如果要使用它,需要手动载入ipvs模块
# 1.安装ipset和ipvsadm
[root@master ~]# yum install ipset ipvsadmin -y
ipvsadm没有也可以
# 2.添加需要加载的模块写入脚本文件
[root@master ~]# cat < /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
# 3.为脚本添加执行权限
[root@master ~]# chmod +x /etc/sysconfig/modules/ipvs.modules
# 4.执行脚本文件
[root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules
# 5.查看对应的模块是否加载成功
[root@master ~]# lsmod | grep -e -ip_vs -e nf_conntrack_ipv4
nf_conntrack_ipv4 15053 10
nf_defrag_ipv4 12729 1 nf_conntrack_ipv4
nf_conntrack 133095 10 ip_vs,nf_nat,nf_nat_ipv4,nf_nat_ipv6,xt_conntrack,nf_nat_masquerade_ipv4,nf_nat_masquerade_ipv6,nf_conntrack_netlink,nf_conntrack_ipv4,nf_conntrack_ipv6 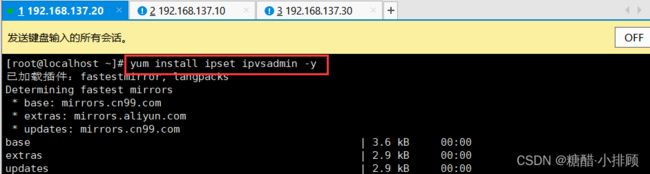
3.3.9安装docker(注意docker 版本要一致)
# 1、切换镜像源
yum install wget -y
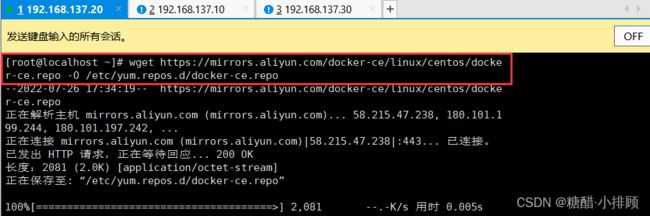
[root@master ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 2、查看当前镜像源中支持的docker版本
[root@master ~]# yum list docker-ce --showduplicates
# 3、安装特定版本的docker-ce
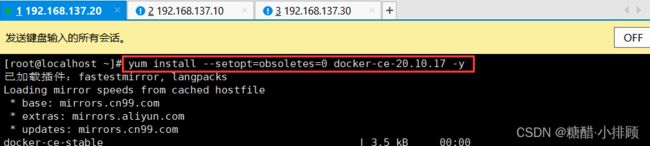
# 必须制定--setopt=obsoletes=0,否则yum会自动安装更高版本
[root@master ~]# yum install --setopt=obsoletes=0 docker-ce-20.10.17 -y
# 4、添加一个配置文件
#Docker 在默认情况下使用Vgroup Driver为cgroupfs,而Kubernetes推荐使用systemd来替代cgroupfs
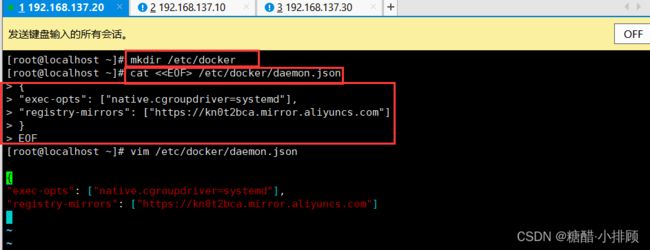
[root@master ~]# mkdir /etc/docker
[root@master ~]# cat < /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://kn0t2bca.mirror.aliyuncs.com"]
}
EOF
# 5、启动dokcer
[root@master ~]# systemctl restart docker
[root@master ~]# systemctl enable docker 

3.4安装Kubernetes组件
# 1、由于kubernetes的镜像在国外,速度比较慢,这里切换成国内的镜像源
# 2、编辑/etc/yum.repos.d/kubernetes.repo,添加下面的配置
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
[root@k8s-node1 ~]# yum makecache
# 3、安装kubeadm、kubelet和kubectl
[root@master ~]# yum install --setopt=obsoletes=0 kubelet-1.19.4 kubeadm-1.19.4 kubectl-1.19.4 -y
# 4、配置kubelet的cgroup
#编辑/etc/sysconfig/kubelet, 添加下面的配置
KUBELET_CGROUP_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
# 5、设置kubelet开机自启
[root@master ~]# systemctl enable --now kubelet
# 6、 查看是否安装成功
yum list installed | grep kubelet
yum list installed | grep kubeadm
yum list installed | grep kubectl 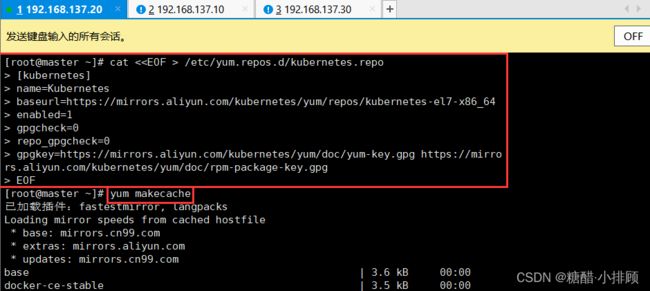
版本查看
kubelet --version
3.5准备集群镜像
# 在安装kubernetes集群之前,必须要提前准备好集群需要的镜像,所需镜像可以通过下面命令查看
[root@master ~]# kubeadm config images list
# 下载镜像
# 此镜像kubernetes的仓库中,由于网络原因,无法连接,下面提供了一种替换方案
images=(
kube-apiserver:v1.17.4
kube-controller-manager:v1.17.4
kube-scheduler:v1.17.4
kube-proxy:v1.17.4
pause:3.1
etcd:3.4.3-0
coredns:1.6.5
)
for imageName in ${images[@]};do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
扩展:
如果正确安装到这里的时候,已经成功安装一大半了,如上的配置都是需要在所有的节点进行配置。可通过xshell工具将所有指令发送到所有的虚拟机,操作如下。
另外,有一些配置是需要重启才能生效的,因此,这里可以重启一下。

3.5.1集群初始化
下面的操作只需要在master节点上执行即可!!!
# 创建集群
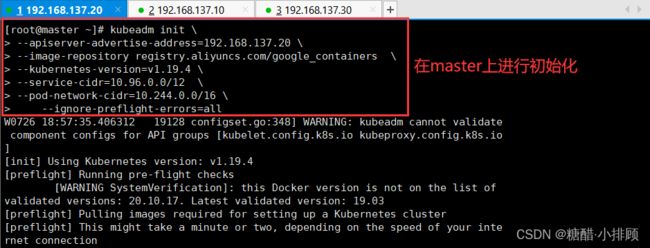
[root@master ~]# kubeadm init \
--apiserver-advertise-address=192.168.137.20 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.19.4 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all
--apiserver-advertise-address 集群通告地址
--image-repository 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
--kubernetes-version K8s版本,与上面安装的一致
--service-cidr 集群内部虚拟网络,Pod统一访问入口
--pod-network-cidr Pod网络,与下面部署的CNI网络组件yaml中保持一致
#####################################################################
# 创建必要文件,拷贝k8s认证文件
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config192.168.137.20是主节点的地址,要自行修改。其它的不用修改


部分英文翻译
# 恭喜你Kubernetes control-plane创建成功
Your Kubernetes control-plane has initialized successfully!
# 接下来你要运行下面这三段话
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
# 你应该在集群上部署一个pod网络。
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
#你可以添加任意多的control-plane,用下面这段命令:
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join master-cluster-endpoint:6443 --token 9ezt8v.yx2owzdiaif06so8 \
--discovery-token-ca-cert-hash sha256:a637ba2a840714a375e6bbc7212123bf8cdd1333317e53731425b6d39af9eafe \
--control-plane
#你可以添加任意多的worker-nodes ,用下面这段命令:
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join master-cluster-endpoint:6443 --token 9ezt8v.yx2owzdiaif06so8 \
--discovery-token-ca-cert-hash sha256:a637ba2a840714a375e6bbc7212123bf8cdd1333317e53731425b6d39af9eafe 下面的操作只需要在node节点上执行即可 !!!
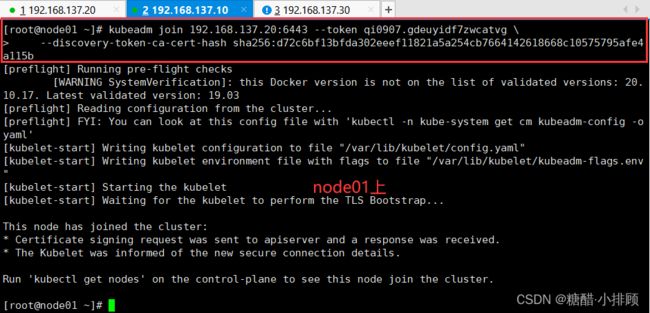
这里复制上面生成的一串命令,我这里只是示例,命令根据你实际生成的复制去node节点执行
kubeadm join 192.168.137.20:6443 --token qi0907.gdeuyidf7zwcatvg \
--discovery-token-ca-cert-hash sha256:d72c6bf13bfda302eeef11821a5a254cb7664142618668c10575795afe4a115b
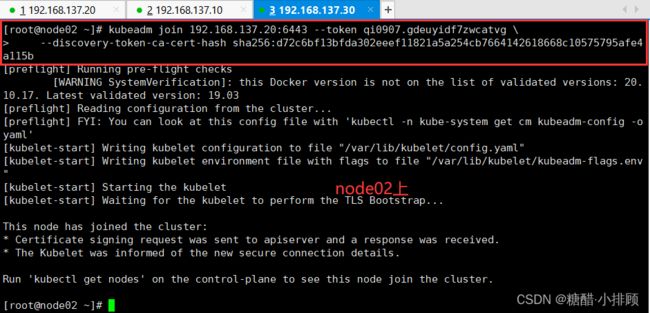
扩展:默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,可以直接使用命令快捷生成:
kubeadm token create --print-join-command#列出token
kubeadm token list | awk -F" " '{print $1}' |tail -n 1
#然后获取CA公钥的的hash值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^ .* //'
#替换join中token及sha256:
kubeadm join 192.168.137.20:6443 --token zwl2z0.arz2wvtrk8yptkyz \
--discovery-token-ca-cert-hash sha256:e211bc7af55310303fbc7126a1bc7289f16b046f8798008b68ee01051361cf023.5.2在master上查看节点信息
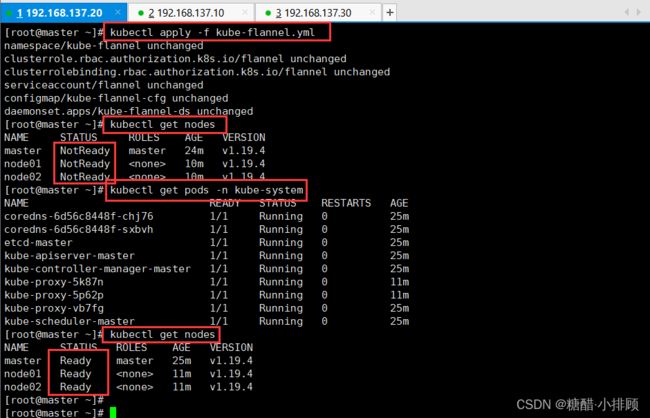
kubectl get nodes查看的时候所有的节点是NotReady状态。
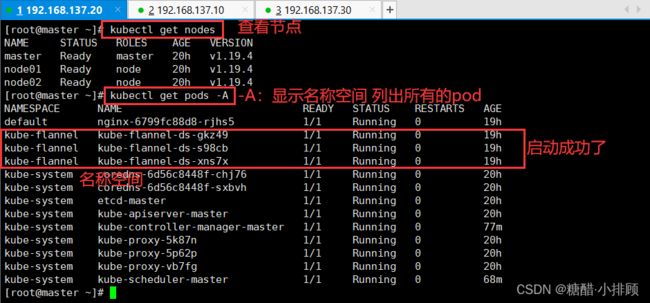
3.5.3安装网络插件(CNI)
下面两种插件二选一,master上执行,如果是云服务器建议按照flannel,calico可能会和云网络环境有冲突
1. 安装flannel插件(轻量级用于快速搭建使用,初学推荐)
下载yaml文件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml修改net-conf.json下面的网段为上面init pod-network-cidr的网段地址(必须正确否则会导致集群网络问题)
sed -i 's/10.240.0.0/10.244.0.0/' kube-flannel.yml修改完安装插件,执行
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system2. 安装calico插件(用于复杂网络环境)
下载yaml文件
wget https://docs.projectcalico.org/v3.9/manifests/calico.yaml修改配置文件的网段为上面init pod-network-cidr的网段地址(必须正确否则会导致集群网络问题)
sed -i 's/192.168.0.0/10.244.0.0/g' calico.yaml修改完安装插件,执行
kubectl apply -f calico.yaml
确认一下calico是否安装成功(耐心等待,coredns和calico为Running状态后再进行后面的操作)
kubectl get pods --all-namespaces -w
kubectl get pod --all-namespaces -o wide由于外网不好访问,如果出现无法访问的情况,可以直接用下面的 记得文件名是kube-flannel.yml,位置:/root/kube-flannel.yml内容:
https://github.com/flannel-io/flannel/tree/master/Documentation/kube-flannel.yml
#这里使用的是flannel插件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system
kubectl get nodes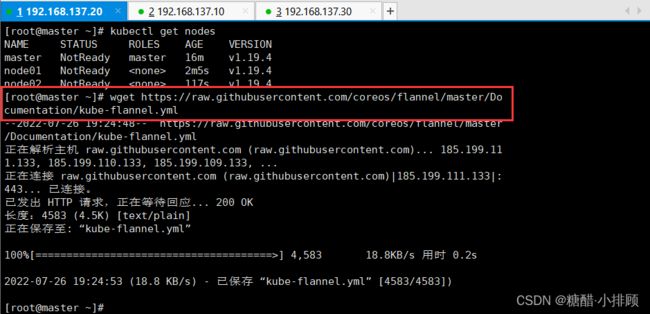
扩展:
更改以下俩个文件
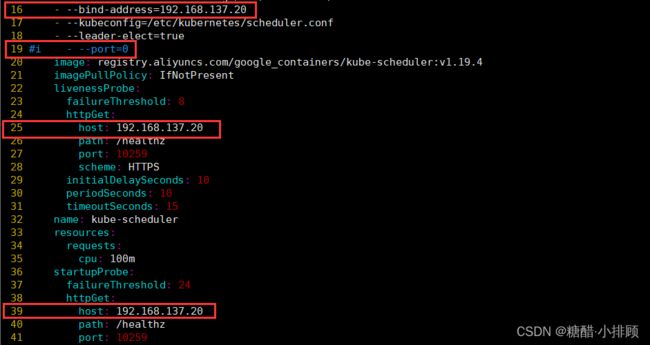
vim /etc/kubernetes/manifests/kube-scheduler.yaml
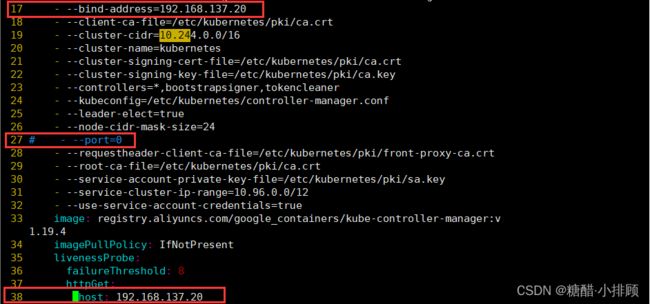
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
#一个是控制资源管理器,一个是资源调度器
# 修改如下内容
把--bind-address=127.0.0.1变成--bind-address=192.168.137.20 #修改成k8s的控制节点master的ip
把httpGet:字段下的hosts由127.0.0.1变成192.168.137.20(有两处)
#- --port=0 # 搜索port=0,把这一行注释掉
systemctl restart kubelet #重新启动

3.5.4给node节点打上“node”的标签
kubectl label node node01 node-role.kubernetes.io/node=node
kubectl label node node02 node-role.kubernetes.io/node=node
kubectl get nodes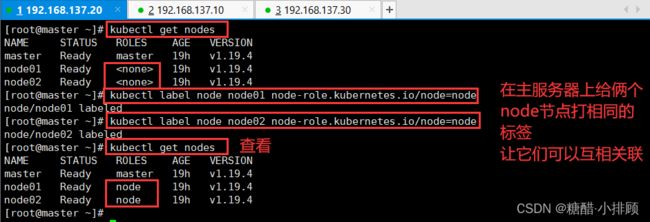
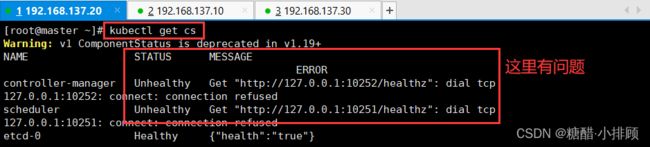
3.5.5查看集群是否健康

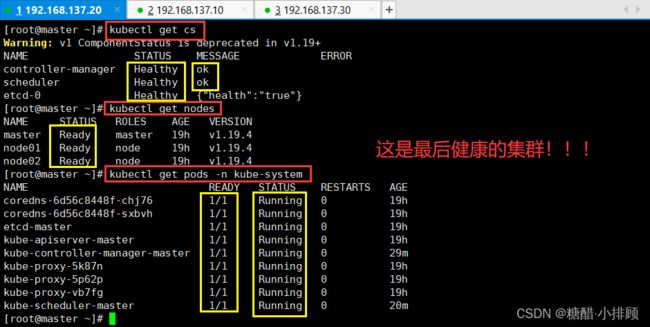
至此,集群搭建完成!!!
3.6集群测试
3.6.1创建一个nginx服务
kubectl create deployment nginx --image=nginx
3.6.2暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
3.6.3查看服务
kubectl get pod,svc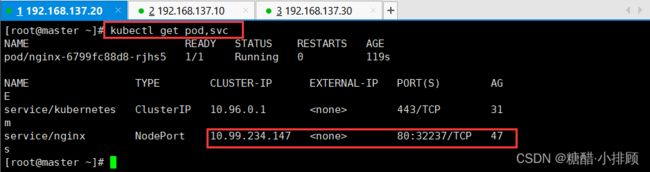
浏览器测试结果:
四:扩展:体验Pod
1.定义pod.yml文件,比如pod_nginx_rs.yaml
cat > pod_nginx_rs.yaml <2.根据pod_nginx_rs.yml文件创建pod
kubectl apply -f pod_nginx_rs.yaml3.查看pod
kubectl get pods
kubectl get pods -o wide
kubectl describe pod nginx4.感受通过ReplicaSet将pod扩容
kubectl scale rs nginx --replicas=5
kubectl get pods -o wide5.删除pod
kubectl delete -f pod_nginx_rs.yaml五: k8s常用命令
查看pod,service,endpoints,secret等等的状态
kubectl get 组件名
# 例如kubectl get pod 查看详细信息可以加上-o wide 其他namespace的指定 -n namespace名
创建、变更一个yaml文件内资源,也可以是目录,目录内包含一组yaml文件(实际使用中都是以yaml文件为主,直接使用命令创建pod的很少,推荐多使用yaml文件)
kubectl apply -f xxx.yaml
# 例如kubectl apply -f nginx.yaml 这里是如果没有则创建,如果有则变更,比create好用删除一个yaml文件内资源,也可以是目录,目录内包含一组yaml文件
kubectl delete -f xxx.yaml
# 例如kubectl delete -f nginx.yaml查看资源状态,比如有一组deployment内的pod没起来,一般用于pod调度过程出现的问题排查
kubectl describe pod pod名
# 先用kubectl get pod查看 有异常的复制pod名使用这个命令查看pod日志,用于pod状态未就绪的故障排查
kubectl logs pod名
# 先用kubectl get pod查看 有异常的复制pod名使用这个命令查看node节点或者是pod资源(cpu,内存资源)使用情况
kubectl top 组件名
# 例如kubectl top node kubectl top pod进入pod内部
kubectl exec -ti pod名 /bin/bash
# 先用kubectl get pod查看 有需要的复制pod名使用这个命令六: 总结
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷