基于双层主题模型的技术演化分析框架及其应用
摘要
【目的】 针对开展技术演化分析时依赖主题间相似度计算和人工设定阈值判断窗口技术主题间关联关系的问题,进行方法研究。【方法】 构建基于双层主题模型的技术主题演化分析框架。分别采用基于LDA和基于NMF的双层主题模型识别动态主题,通过主题内一致性和差异度指标评价两种方法的技术主题识别效果,对比选定最优方法,从主题成长性和重要性方面进行技术主题演化分析。【结果】 通过在资源环境领域的应用研究发现,基于NMF的双层主题模型识别的动态主题具有更高的主题内语义一致性和主题间语义差异度,技术演化分析结果能够从《麻省理工科技评论》发布的突破性技术清单中得到验证。【局限】 仅研究了技术从出现到消亡的发展轨迹,未关注技术的分裂、衍生和融合。【结论】 所提方法能够利用特定时间段的文献数据,自动识别动态主题并对主题的演化轨迹进行分析,在科技情报分析工作中具有实际应用价值。
关键词: 技术演化分析; 主题模型; 科技文献挖掘; NMF; 资源环境领域
1 引言
技术演化分析能够刻画技术发展路径,揭示技术发展轨迹,对于新技术布局和创新资源配置具有重要的指导意义,是情报学的热点研究方向之一[1]。随着数据挖掘和机器学习技术的不断发展,技术演化分析已从依赖领域技术专家主观判断向数据驱动的定量化数据分析转变。
目前,基于定量数据开展技术演化分析的思路可以分为三种,分别是基于技术分类号的技术演化分析、基于文献引用关系的技术演化分析和基于科技文献文本挖掘的技术演化分析[2]。其中,基于科技文献文本挖掘是现阶段受关注度较高的研究思路[3],研究过程大致为:利用科技文献(包括论文、专利等)文本数据,采用文本挖掘技术(如主题模型、文本聚类等),识别技术主题并计算其在各个时间窗口的指标特征,呈现技术演化规律和态势[4,5,6]。这些研究为在实际情报研究工作中开展技术演化分析提供了方法基础,但是这些研究存在的问题在于:在识别到各个时间窗口的技术主题之后,需要较多的人工干预或阈值选择才能判断各个时间窗口的技术主题之间的关系。
双层主题模型能够通过两次主题模型的计算实现多个技术主题关联关系的构建,从而进行动态主题分析,已经在政策文本主题的动态分析中应用[7]。因此,本文引入双层主题模型在技术演化分析这一问题上进行方法应用研究。本文发挥了双层主题模型在自动关联计算各个时间窗口的技术主题之间的关系的方法优势,并通过集成技术演化分析指标,形成一套基于双层主题模型的技术演化分析框架。本文分析框架的优势如下。
(1)应用双层主题模型方法识别动态主题,在获取各个时间窗口的技术主题之后,无需人工干预或阈值选择,即可计算得到各个技术主题之间的关联关系,用于分析技术演化态势。
(2)从主题内一致性和主题间差异性两个角度评价主题模型的主题识别效果,辅助情报分析人员根据分析需求选择合适、有效的主题模型。
(3)从技术主题成长性和重要性方面对特定领域的技术主题进行分析和评价,从而识别在演化趋势上具有高成长性和高重要性特征的技术主题。
2 相关研究现状
学术界已经形成了一系列演化分析的方法研究成果,这些演化分析方法根据分析对象的不同,可分为技术演化分析、学科演化分析等,但是这些分析方法在方法原理上并无区别,因此将相关研究的方法均纳入本文研究的技术演化分析方法的综述范畴。
2.1 现有研究分类
整体来看,相关研究可以分为基于技术分类号的技术演化分析、基于文献引用关系的技术演化分析和基于科技文献文本挖掘的技术演化分析三类。
基于技术分类号的技术演化分析利用科技文献中包含的科技文献分类号(如学科分类、专利IPC分类号等)表示技术[8],虽然分析较为便捷,但是这种方法受限于分类体系的框架和粒度,识别的技术主题粒度较粗,且无法识别新的技术主题;基于文献引用关系的技术演化分析是利用科技文献之间的共被引或耦合关系将科技文献划分为若干技术主题簇,然后结合主题之间的关联分析绘制技术演化进程[9,10],这种方法能够有效分析技术之间的流动性,但是受限于引文时滞的影响;基于科技文献文本挖掘的技术演化分析的思路是基于科技文献的文本数据,利用文本挖掘方法和自然语言处理技术来识别技术主题,能够更为细粒度地刻画技术主题[11],并且不受引文时滞影响,是本文的重点关注方向。
2.2 基于科技文献文本挖掘的技术演化分析研究进展
从实施过程来看,基于科技文献文本挖掘的技术演化分析可分为三个步骤。第一步是对时间序列上各时间窗口的技术主题进行识别;第二步是计算判断各个时间窗口主题之间的关系;第三步是开展技术演化分析。现有研究基本都是围绕前两个步骤进行方法创新,其中第一个步骤的方法创新较为丰富,可以分为基于关键词共现分析、基于关键词聚类或社区探测算法和基于主题模型方法三类。
在基于关键词共现分析方面,通过专家遴选或规则计算发现多个技术主题表证词,然后基于这些表征词的共词关系,借助一些开源工具(如NetDraw、VOSViewer、CiteSpace等)按照时序进行共词网络可视化呈现,从而直观观察技术演化趋势。例如,郑晓月等[12]基于主题-关键词共现分析对计量学的学科主题演化进行分析。这种方法比较简单,但是在技术主题表证词选取方面存在较大的主观性。
在基于关键词聚类或社区探测算法方面,思路是基于关键词共词网络,采用聚类算法(如K-Means、层次聚类等)或社区探测算法(如Louvain算法)识别网络中的若干关键技术主题,然后通过各技术主题随时间的变化分析技术演化规律。例如,巴志超等[13]基于Word2Vec构建关键词语义网络,采用关键词g指数获取不同年份内频次较高的关键词,通过语义聚类方法,获取特定年份的技术主题,以此开展技术演化分析;王康等[14]采用Louvain社区探测算法识别特定时间序列上各时间窗口的论文主题,采用相似度算法测度相邻时间窗口的主题相似度;刘自强等[4]使用Fast Unfolding社区发现算法聚类发现主题,采用余弦相似度计算学科主题相似度,从而判定特定主题的时序演化关系。这种方法得到的结果可解释性较强,但是受聚类或社区探测算法影响较大,可能会出现超大主题簇,且主题个数需要人为判断给定。
在基于主题模型方法方面,研究思路是基于主题模型,自动地从科技文献中发现主题,并通过指标自动确定主题个数。由于主题模型基于较为严密的数学逻辑对文本进行建模,能够自动化识别主题并确定主题个数,近年来颇受学者关注[15]。例如,廖列法等[16]采用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型按时间窗口对专利文本建模,采用困惑度确定最优主题数。但由于经典LDA模型存在主题辨识度低、可解释性弱等问题,基于主题模型开展技术演化分析的改进研究成果不断形成。例如,陈亮等[17]采用hLDA模型对不同时间片段的专利集合进行层次主题结构抽取;吴菲菲等[18]采用在LDA主题模型基础上引入文档作者信息和时间概念的AToT(Author-Topic-Time)模型挖掘文献数据中不同阶段同一主题关注强度的变化情况、内部演化规律和作者兴趣的变化;吴红等[19]同时考虑专利文本和IPC分类号数据,构建WI-LDA模型进行技术主题识别。可以发现,当前基于主题模型开展技术演化分析采用的主流模型是LDA,但也有学者采用非负矩阵分解(Non-negative Matrix Factorization,NMF),如王园园等[20]采用基于NMF的主题模型方法识别窗口技术主题。
2.3 现有研究评述
通过上述分析发现,基于科技文献文本挖掘的技术演化研究已经形成了一系列窗口主题识别方法的研究成果,其中,基于主题模型方法是当前的热点研究方向。但是,这些研究存在的不足在于:在判断各个时间窗口主题之间的关联关系方面,主要通过计算主题间相似度和人工设定阈值的方式判断窗口技术主题之间的关联关系,这种方式具有较大的主观性;同时,现有方法多侧重采用一种方法(如LDA或NMF)进行技术主题识别,对于模型的效果优劣缺乏对比。
针对这些不足,本文引入双层主题模型,构建了一套基于双层主题模型的技术演化分析框架,该框架能够在无需人工干预或阈值选择的情况下计算各时间窗口技术主题之间的关联关系,从而分析技术演化态势,同时支持对多种主题模型方法效果的对比,还能够从技术主题成长性和重要性方面对特定领域值得关注的技术主题进行识别和重点分析,在情报研究的技术分析工作中具有较高的应用前景。
3 方法框架
本文设计的基于双层主题模型的主题演化分析总体框架如图1所示。
图1
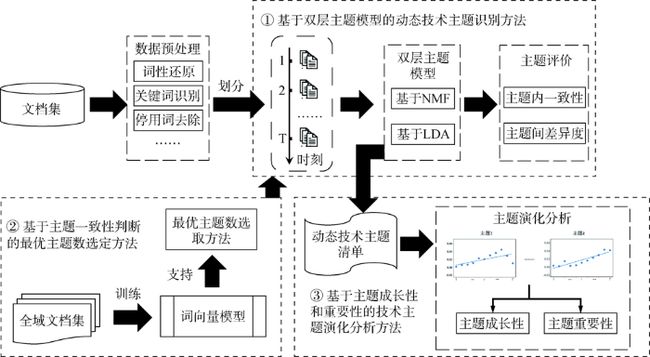
图1 方法总体框架
Fig.1 The Overall Framework of Method
包含三个步骤,分别是基于双层主题模型的动态技术主题识别方法、基于主题一致性判断的最优主题数选定方法和基于主题成长性和重要性的技术主题演化分析方法。在双层主题模型方面,分别采用基于LDA和基于NMF的双层主题模型识别动态主题,通过主题内一致性、主题间差异度指标评价两种方法识别的主题效果,最后选择效果更好的双层主题模型开展演化分析。
3.1 基于双层主题模型的动态技术主题识别方法
(1) 双层主题模型
双层主题模型(Two Layer Topic Model)是在基础主题模型的基础上构建。
主题模型(Topic Model)是一种用于在一系列文档中自动计算和发现主题的统计模型,可以分为基于矩阵分解的主题模型(如LSI和NMF)和概率主题模型(如PLSI 和LDA)两种。
非负矩阵分解(NMF)是基于矩阵分解的主题模型的代表[21],它将主题识别问题转化为约束最优化问题来解决,通过矩阵分解的计算实现主题识别,核心思想为:将一个文档-词项的非负矩阵 AA分解成两个非负矩阵 WW和 HH的乘积,表示为公式(1)。
A=WHA=WH
(1)
其中, WW为文档-主题矩阵; HH为主题-词项矩阵。
LDA模型是目前应用最为广泛的概率主题模型[22]。它在PLSI的基础上引入了超参分别为 αα和 ββ的隐含狄利克雷分布 Dir(*)Dir(*)作为文档对主题和主题对词项分布的先验概率分布,是一个生成概率模型。LDA的基本思想是将文档表示为潜在主题(Latent Topic)的随机混合,其中每个主题都由若干单词表示。
由于基础主题模型仅能对某一文档集合进行主题识别,无法实现对某一时间序列上的多个文档集合的主题演变进行分析,因此无法直接用于技术演化分析。而双层主题模型能够在基础主题模型的基础上,通过两轮主题模型计算得到整个时间序列上的动态主题[7],从而实现主题演化的动态分析;同时,该过程无需人工干预或阈值选择,即可计算得到各个主题之间的关联关系,具有较高的客观性。因此,本文引入双层主题模型构建技术演化分析框架。该模型由三个层次组成,分别是输入层、窗口主题识别层和动态主题识别层,如图2所示。
图2
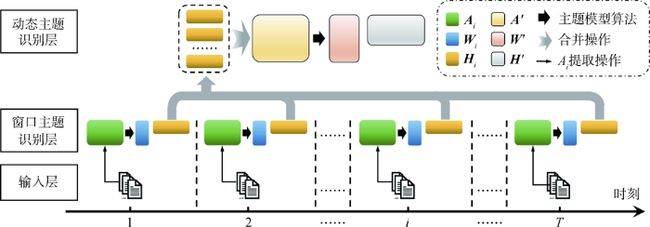
图2 双层主题模型框架[7]
Fig.2 The Framework of Two-Layers Topic Model
其中,输入层的输入数据是 TT个时刻的文档集合,表示为 {D1,D2,…,DT}{D1,D2,…,DT};每个文档集合由若干文档组成,表示为 Di={d1,d2,…,d|Di|}Di={d1,d2,…,d|Di|};每个文档由词的序列构成,表示为 dj=(w1,w2,…,w|dj|)dj=(w1,w2,…,w|dj|)。
第一层为窗口主题识别层,目的是分别对各个时刻的文档集合确定其主题,即对每个时刻的文档集合 DiDi分别利用主题模型算法处理得到其对应的 WiWi和 HiHi,因此,该层对应的输出为式(2)。
{〈W1,H1〉,〈W2,H2〉,…,〈WT,HT〉}{〈W1,H1〉,〈W2,H2〉,…,〈WT,HT〉}
(2)
第二层为动态主题识别层,动态主题识别层的目的是从窗口主题识别层的各个时刻的主题中提取 TT个时刻的文档集合的主题。计算步骤为:首先将第一层处理得到的各个矩阵 HiHi拼接成一个大的矩阵 A'A',该矩阵的行数为 ∑=1iki∑i=1Tki,列数为 |V|V,这样可将第一层识别得到的各个时间段的主题看作第二层的“文档”,第一层主题对于词项的权重可视为第二层“文档”对于词项的权重,也就是矩阵 A'A',然后再利用主题模型算法对 A'A'进行主题提取,得到 W'W'和 H'H'。上述符号的解释如表1所示。
表1 双层主题模型中的符号定义
Table 1 The Symbol Definition in Two-Layer Topic Model
| 符号 |
意义 |
| TT |
总时刻 |
| DiDi |
第 ii个时刻的文档集合 |
| VV |
所有时刻的文档集合的词项集合 |
| dd |
单篇文档 |
| ww |
单个词项 |
| kiki |
第 ii个时刻的文档集的主题个数 |
| AiAi |
第 ii个时刻的文档集合的文档-词项矩阵, Ai∈R|Di|×|Vi|Ai∈RDi×Vi |
| WiWi |
第 ii个时刻的由主题模型得到的文档集合的文档-主题矩阵, Wi∈R|Di|×kiWi∈RDi×ki |
| HiHi |
第 ii个时刻的由主题模型得到的文档集合的主题-词项矩阵, Hi∈Rki×|Vi|Hi∈Rki×Vi |
| k'k' |
第二层主题模型的动态主题个数 |
| A'A' |
由所有 HiHi( i∈[1,T]i∈1,T)合并得到的矩阵, A'∈R∑=iki×|V|A'∈R∑i=1Tki×V |
| W'W' |
以 A'A'作为主题模型的输入得到的文档-主题矩阵, W'∈R∑=iki×k'W'∈R∑i=1Tki×k' |
| H'H' |
以 A'A'作为主题模型的输入得到的主题-词项矩阵, H'∈Rk'×|V|H'∈Rk'×V |
双层主题模型根据所使用的基础主题模型(NMF或LDA)的不同,可分为双层NMF主题模型(Two Layer NMF,TL-NMF)和双层LDA主题模型(Two Layer LDA,TL-LDA),两种模型均可在技术演化分析中应用,但是应用效果需通过计算效果评价指标来对比选定。
(2) 模型效果评价指标
针对TL-NMF和TL-LDA两种模型,本文从识别主题的语义一致性和主题间差异性两个角度分别设计两类效果评价指标,分别是主题内一致性指标和主题间差异度指标。
主题内一致性用于评价各个主题内词项相似度的高低。Word2Vec是谷歌公司提出的一项利用低维度连续分布式向量表示词的语义的技术[23],能够实现同义词、近义词等语义相近的词之间相似关系的表示,可以用来判断主题的内的语义一致性。本文利用现有研究的计算方法[7],计算主题内一致性 InnerSim(TM)InnerSimTM,假设对于一个主题模型以主题数为 kk生成的主题集合表示为 TM={t1,t2,…,tk}TM={t1,t2,…,tk}, ti={wi,1,wi,2,…,wi,t}ti={wi,1,wi,2,…,wi,t}, titi表示与第 ii个主题最相关的前 tt个词的集合。 InnerSim(TM)InnerSim(TM)计算方式如公式(3)所示。
InnerSim(TM)=1k∑ki=11(t2)∑t−1j=1∑+1to=jInnerSimTM=1k∑i=1k1t2∑j=1t-1∑o=j+1tCosSim(w2v(wi,j),w2v(wi,o))CosSim(w2v(wi,j),w2v(wi,o))
(3)
其中, w2v(w)w2v(w)表示词项 ww的词向量; CosSim(*)CosSim*表示词向量余弦相似度。
主题内一致性仅能够反映主题内词的语义一致程度,不能反映主题间词的差异度。因此,本文还采用主题间差异度评价各个主题之间的距离远近,主题间差异度越大,说明主题之间的内容越不相关,距离越远。本文采用两种方式度量主题间差异度,一种是基于词向量相似度的方式 OuterDiffW2VOuterDiffW2V,用来度量主题间语义的距离;另一种是基于Jaccard相似度的方式 OuterDiffJCDOuterDiffJCD,用来度量主题间共现词的多少,如公式(4)和公式(5)所示。主题间差异度的输入与主题一致性保持一致。
OuterDiffW2V(TM)=1−1(k2)∑k−1i=1∑kj=i+11t2∑to=1∑tp=1CosSim(w2v(wi,o),w2v(wj,p))OuterDiffW2VTM=1-1k2∑i=1k-1∑j=i+1k1t2∑o=1t∑p=1tCosSim(w2v(wi,o),w2v(wj,p))
(4)
OuterDiffJCD=1−1(k2)∑k−1i=1∑kj=i+1|ti⋂tj||ti⋃tj|OuterDiffJCD=1-1k2∑i=1k-1∑j=i+1k|ti⋂tj||ti⋃tj|
(5)
其中, |*|*表示集合的个数。
3.2 基于主题一致性判断的最优主题数选定方法
主题个数 kk是主题模型算法中一个重要的超参数,它的确定能够直接影响到主题模型算法的效果。对于本文的任务,如果需要专家逐个时间段确定各个时间段文档的主题数,则需要经过大量对比实验。因此,主题一致性可以用来辅助自动确定主题模型的主题个数,以泛化双层主题模型的使用场景。
本文利用Word2Vec模型计算主题语义一致性程度( InnerSimInnerSim)确定最优主题个数。最优主题数 k⋆k⋆的确定如公式(6)所示。
k⋆=arg maxk∈[kmin,kmax]InnerSim(TM)k⋆=arg maxk∈[kmin,kmax]InnerSimTM
(6)
其中, kminkmin和 kmaxkmax分别为根据领域特点或经验设定的主题数的适合区间的上界和下界。
3.3 基于主题成长性和重要性的技术主题演化分析方法
通过分析双层主题模型的动态主题识别层的输出 W'W',能够获得各个动态主题在各个时刻的权重,基于此进行主题演化分析。
根据 W'W',对于第 jj个动态主题,第 ii个时刻对其的权重计算如公式(7)所示。
Weight(i,j)=1ki∑∑ip=jkpo=∑i−1p=1kpW′o,jWeight(i,j)=1ki∑o=∑p=1i−1kp∑p=jikpWo,j′
(7)
例如,如图3所示,点A的权重为 Weight(1,j)=1k1∑k1o=0W'o,jWeight(1,j)=1k1∑o=0k1Wo,j',点B的权重为Weight(T,j)=1kT∑k1+⋯+kTo=k1+⋯+kT−1W′o,jWeight(T,j)=1kT∑o=k1+⋯+kT−1k1+⋯+kTWo,j′。因此,基于 W'W'可以得到第 jj个主题随时刻变化的权重序列 (Weight(1,j),(Weight(1,j),Weight(2,j),…,Weight(T,j))Weight(2,j),…,Weight(T,j))。
图3
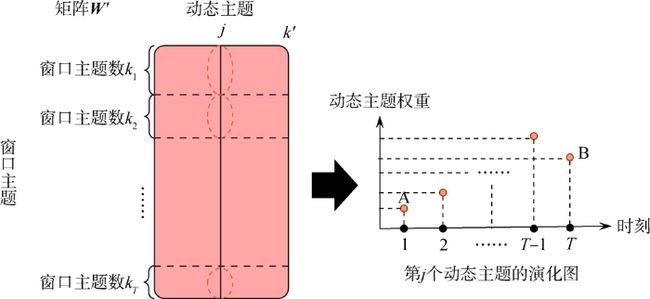
图3 动态主题在各个时间窗口的权重计算示意图
Fig.3 The Weight Calculation Method of Dynamic Theme in Each Time Window
本文基于主题对时刻的权重序列设置两个指标辅助主题演化分析,分别是主题成长性 GrowthGrowth和主题重要性 ImportanceImportance。
主题成长性 GrowthGrowth用于判断主题的变化趋势。对于第 jj个主题,将时间窗口作为X轴,第 jj个主题随时刻变化的权重序列作为Y轴,通过线性回归分析方法对其走势进行拟合,求解一元线性回归方程,如公式(8)所示。
y=Growth⋅x+by=Growth·x+b
(8)
其中, GrowthGrowth表示斜率,同时也表示主题的成长性; bb为截距。
主题重要性 ImportanceImportance用于判断主题的重要程度。对于第 jj个主题,主题重要性为其在各个时刻权重的平均值,如公式(9)所示。
Importance=1T∑Ti=1Weight(i,j)Importance=1T∑i=1TWeight(i,j)
(9)
4 方法应用
近年来,资环生态环境领域在我国的受关注度不断提高。我国“十四五”规划和2035远景目标提及“生态环境”20次,提及“资源”过百次。解决资源约束趋紧、生态环境问题突出等经济发展过程中的瓶颈问题,是我国实现两阶段发展目标的重要条件。在此背景下,对资源环境领域涉及的技术进行演化分析,对于技术布局和决策参考具有现实意义。因此,本文选择资源环境领域(简称资环领域)进行方法的应用研究。
4.1 数据及预处理
本文采用的文献数据来自Web of Science(WOS)数据库的资环领域Highly Cited Papers①(①Highly Cited Papers:高被引论文,是指最近10年发表的各领域被引频次排名前1%的论文。)和Hot Papers②(②Hot Papers:热点论文,是指最近两年发表的、在最近两个月被引用频次排名前0.1%的论文。),共计15 185篇论文,数据获取时间是2021年1月14日。按照年份划分数据集后,结果如表2所示。
表2 论文数据分布
Table 2 The Distribution of WOS Paper
| 年份 |
论文数量 |
| 2010 |
959 |
| 2011 |
1 078 |
| 2012 |
1 103 |
| 2013 |
1 173 |
| 2014 |
1 260 |
| 2015 |
1 268 |
| 2016 |
1 391 |
| 2017 |
1 504 |
| 2018 |
1 703 |
| 2019 |
2 166 |
| 2020 |
1 580 |
4.2 结果与评价
(1) 最优主题k选取
本文通过与资环领域情报专家的研讨,设定TL-NMF和TL-LDA模型的窗口主题识别层的最优主题数的区间为 ki∈[5,20],ki∈Nki∈5,20,ki∈N。
两个模型的窗口主题识别层在各个时刻选取最优主题k的结果分别如图4和图5所示,其中,横轴代表主题个数,纵轴代表主题内一致性的数值。由图4和图5可知,在窗口主题识别层,对于2010-2020年11个年份时刻,TL-NMF模型自动设定的最优主题个数分别为16、17、19、19、15、13、8、16、12、18、19;TL-LDA模型自动设定的最优主题个数分别为19、19、18、12、10、10、13、20、16、10、13。
图4

图4 基于TL-NMF计算的各时间窗口的最优主题个数
Fig.4 Result of the Optimal Number of Window Topics by TL-NMF
图5
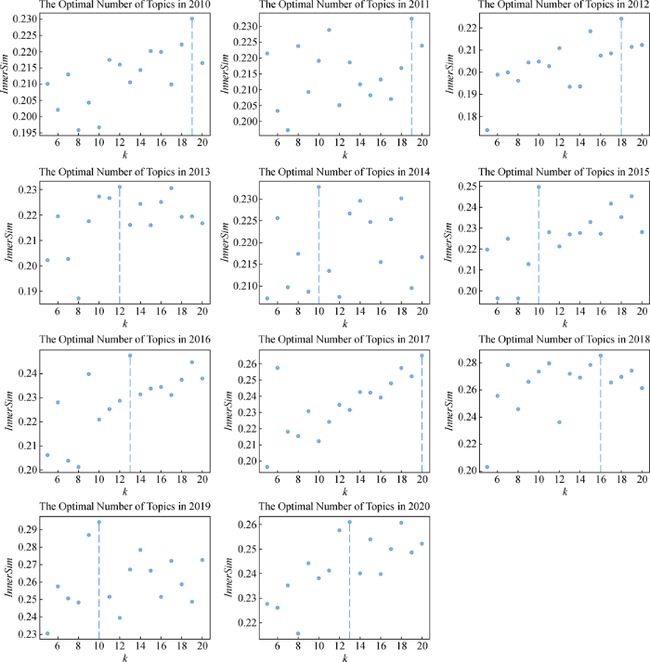
图5 基于TL-LDA计算的各时间窗口的最优主题个数
Fig.5 Result of the Optimal Number of Window Topics by TL-LDA
在各时间窗口取最优主题数的条件下,TL-NMF和TL-LDA识别的主题一致性平均值对比结果如图6所示。可以发现,TL-NMF在各个时间窗口的主题一致性平均值均高于TL-LDA模型,并且TL-NMF模型窗口主题识别层各个主题模型的主题内一致性最小值0.306 1(2013年数据)也高于TL-LDA模型窗口主题识别层各个主题模型的主题内一致性最大值0.294 4(2019年数据)。因此,从窗口主题的主题一致性指标来说,TL-NMF模型的效果要优于TL-LDA模型。
图6
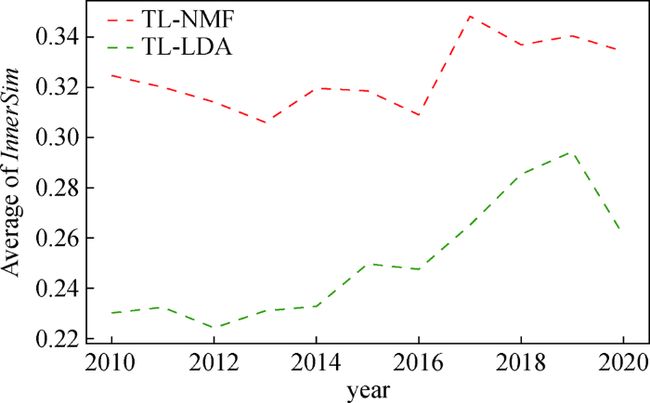
图6 在各时间窗口取最优主题数的条件下,TL-NMF和TL-LDA识别的主题一致性平均值
Fig.6 The Topic Consistence Average Value by TL-NMF and TL-LDA When Taking the Optimal Number of Window Topics
对于动态主题识别层的主题模型,本文通过与资环领域情报专家研讨,设定其最优主题数的区间为 k'∈[20,70],k'∈Nk'∈20,70,k'∈N。TL-NMF模型和TL-LDA模型动态主题识别层主题模型的最优主题数分别为50和42,如图7所示。
图7
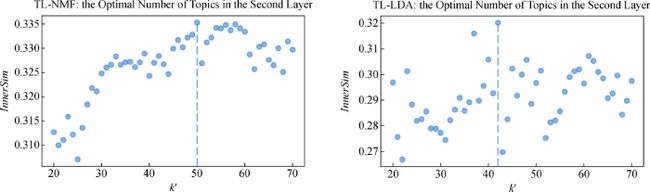
图7 基于TL-NMF和TL-LDA的动态主题识别层的最优主题个数
Fig.7 Result of the Optimal Number of Dynamic Topics by TL-NMF and TL-LDA
(2) 主题模型评价
针对TL-NMF和TL-LDA模型的评价结果如表3所示。可以发现,TL-NMF模型的主题一致性(InnerSim)和利用词向量度量的主题差异度(OuterDiffW2V)都要优于TL-LDA模型,这说明在基于词向量的评价指标下,TL-NMF模型产生的动态主题主题内的一致性更高,主题间词的差异更大。在基于Jaccard度量的主题差异度(OuterDiffJCD)方面,两个模型的主题差异度均在0.98以上,且模型间差异极小,TL-LDA比TL-NMF高约0.006 1,这说明两个模型生成的主题间的共现词都很少。
表3 模型效果对比
Table 3 Comparison of Model Effect
| 模型 |
主题一致性 InnerSimInnerSim |
主题差异度 OuterDiffW2VOuterDiffW2V |
主题差异度 OuterDiffJCDOuterDiffJCD |
| TL-NMF |
0.366 9 |
0.806 9 |
0.986 7 |
| TL-LDA |
0.351 3 |
0.714 5 |
0.992 8 |
因此,从主题间词的共现角度来看,TL-NMF和TL-LDA模型识别的主题均具有较高的区别度;而从主题间词的语义角度看,语义上相近的词在TL-LDA模型中有可能分到不同的主题,TL-NMF识别的主题间具有更高的语义差异度,主题内具有更高的语义相似度,更利于技术主题的区别和发现。
此外,本文将两种模型识别的主题结果进行了专家判断。如表4和表5所示,TL-NMF模型的主题(Top5)在专家看来更合适解读为一个主题,如主题0属于气候变化主题,主题7属于锂金属电池主题,主题27表示神经网络主题,主题35属于流行病主题。相比较而言,TL-LDA模型的主题(Top5)可解释性较差,如主题26,虽然与该主题最相关的词是COVID(冠状病毒),但是后4个词并不与此相关,如Mediterranean(地中海)、Soil Erosion(水土流失)等。
表4 基于TL-NMF的动态技术主题识别示例
Table 4 Examples of Dynamic Topics Based on TL-NMF
| Top5 |
t0t0 |
t7t7 |
t10t10 |
t27t27 |
t35t35 |
t49t49 |
| 1 |
Climate |
Lithium |
GIS |
Network |
COVID |
Microalgae |
| 2 |
Change |
Ion Batteries |
Support Vector Machine |
Prediction |
Coronavirus |
Biodiesel |
| 3 |
Impacts |
Li |
Spatial Prediction |
Artificial Neural |
SARS |
Algae |
| 4 |
Temperature |
Capacity |
Regression |
Algorithm |
COV |
Biodiesel Production |
| 5 |
Climate Change |
Storage |
Logistic |
ANN |
Pandemic |
Biofuels |
表5 基于TL-LDA的动态技术主题识别示例
Table 5 Examples of Dynamic Topics Based on TL-LDA
| Top5 |
t0t0 |
t5t5 |
t17t17 |
t26t26 |
t32t32 |
t41t41 |
| 1 |
Membrane Bioreactor |
Trend Analysis |
Model |
COVID |
Membrane Fouling |
Hydraulic Fracture |
| 2 |
Temporal |
Microgrids |
Water |
Holocene |
Aerobic Granular Sludge |
Neural Network |
| 3 |
Flower Pollination Algorithm |
Monitor |
Climate |
Ecological Footprint |
Biosynthesis |
Electricity Market |
| 4 |
Nanoscale Zero |
Water Management |
Carbon |
Mediterranean |
Density Functional Theory |
Transfer Learning |
| 5 |
Artificial Bee Colony |
Statistics |
Temperature |
Soil Erosion |
Hydrogen Generation |
Surface Mass |
基于以上分析,结合客观指标和实际结果综合考虑,本文认为TL-NMF模型的效果要好于TL-LDA模型,并选择TL-NMF模型开展进一步的技术主题演化分析。
(3) 技术主题演化分析结果
针对TL-NMF模型得到50个技术主题,本文分别从主题成长性和主题重要性角度开展技术主题演化分析。
主题成长性反映某个主题随时间的演化趋势,根据本文对主题成长性的定义,如果其值越大,则说明拟合的一元方程的斜率越大,能够反映该主题随时间变化越来越受到重视(权重越大)。
50个技术主题中成长性排名Top3的主题分别为的主题10、主题27和主题7,其演化图如图8所示,它们的主题的成长性分别为0.004 9、0.004 6和0.004 2,主题分别为关于智能遥感卫星数据分析、人工智能防灾减灾和锂金属电池技术,具体的词项见支撑数据。
图8
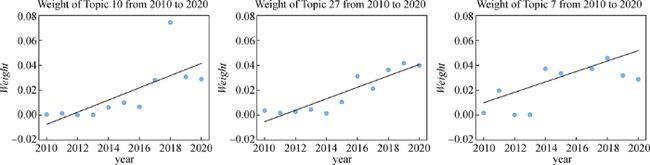
图8 成长性排名Top3的动态技术主题演化分析
Fig.8 The Evaluation Analysis of Top3 Dynamic Topics in Growth
①技术主题10主要围绕智能遥感卫星数据分析,该主题相关的词项涉及了一些机器学习模型(如Support Vector Model和Random Forest等)和GIS(Geographic Information System)相关的一些词汇(如Spatial Prediction和Landslide Susceptibility等)。在2021年《麻省理工科技评论》发布的十大突破性技术[24]中,第6项技术超高精度定位(Hyper-Accurate Positioning)技术与该技术契合。
②技术主题27主要围绕人工智能防灾减灾,该主题相关的词项涉及人工智能模型(如Artificial Neural Network、ANN、Genetic Algorithm、Particle Swarm Optimization和Hybrid Model等)和任务词汇(如Prediction、Regression、Optimization、Application和Forecasting等)。该技术主题与2020年《麻省理工科技评论》发布的十大突破性技术[25]中第10项气候变化归因(Climate-Change Attribution)契合。
③技术主题7主要围绕锂金属电池,该主题相关的词项涉及锂离子电池(如Lithium、Ion Batteries和Solid等)和电池容量存储电极(如Capacity Predict、Storage、Electrode和Electrode Material等),与2021年《麻省理工科技评论》发布的十大突破性技术中的第4项锂金属电池(Lithium-Metal Batteries)技术[24]契合。
主题重要性反映了某个主题在整个时间段的重要性。根据本文对主题重要性的定义,如果其值越大,说明该主题越重要。
50个技术主题中重要性排名Top3的主题分别为主题4、主题3和主题6,其演化图如图9所示,它们的主题的重要性分别为0.033 7,0.033 0和0.031 6,主题分别为关于模型模拟、减少碳排放和生物多样性,具体的词项见支撑数据。
图9
别为0.033 7,0.033 0和0.031 6,主题分别为关于模型模拟、减少碳排放和生物多样性,具体的词项见支撑数据。
图9
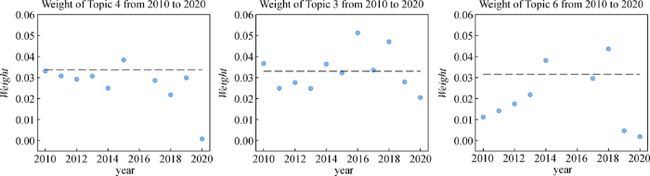
图9 重要性排名Top3的动态技术主题演化分析
Fig.9 The Evaluation Analysis of Top3 Dynamic Topics in Importance
①技术主题4主要围绕模型模拟,相关主题词有Model(模型)、Simulation(模拟)、Validation(验证)、Numerical(数值)和Uncertainty(不确定性)。该主题涉及科学实验的模型验证,是开展研究的必要方法手段。
②技术主题3主要围绕降碳问题,相关主题词有Energy Efficiency(能源效率)、Energy Consumption(能源消耗)、CO2 Emission(二氧化碳排放)、Circular Economy(循环经济)和Urbanization(城市化)等。降碳一直是资环领域的重要研究问题,是全球应对气候变化的共识,大多数国家均提出了碳达峰和碳中和的目标,我国也在2020年提出了力争于2030年前达到峰值,努力争取到2060年前实现碳中和的目标。
③技术主题6主要围绕保护生物多样性问题,相关主题词有Biodiversity(生物多样性)、Ecosystem Service(生态系统服务)、Conservation(保护)、Diversity(多样性)、Ecological System(生态系统)和Governance(治理)等。该主题也是资环领域具有共识性的重要研究问题。
50个技术主题的成长性和重要性分布如图10所示。可以发现,主题7“锂金属电池技术”同时兼具高成长性(第3名)与高重要性(第4名),表现最为突出,代表性的主题词包括Lithium(锂)、Ion Batteries(离子电池)、Storage(储能)、Solid(固态)等。该技术主题在两项指标上的突出表现与科技界认知一致。近年来,随着便携电子设备、电动汽车、储能电站等新生事物的不断涌现,锂电池技术的受重视程度不断提升,但是目前普遍使用的锂离子电池由于其所依赖的液体电解质在碰撞时极易起火,因此需要新的技术突破来弥补安全缺陷。基于固态电解质的锂金属电池能够兼顾能量密度、安全性和快充性能,将有望实现与锂离子电池相互补充甚至替代,近年来颇受科技界重视,硅谷初创公司QuantumScape声称已经开发出全新的锂金属,《麻省理工科技评论》也在2021年将锂金属电池列为十大突破性技术之一[24]。基于以上分析可知,本文方法识别出的高成长性和高重要性的技术主题是具有可解释性的,能够证明本文方法具有较好的应用效果。
图10

图10 50个主题的成长性和重要性分布
Fig.10 The Growth and Importance Distribution of 50 Dynamic Topics
5 结语
开展技术演化分析,揭示技术演化规律,洞察技术趋势对于新技术布局和创新资源配置具有重要决策价值。本文针对现有研究开展技术演化分析时依赖主题间相似度计算和人工设定阈值判断窗口技术主题间关联关系的问题,提出一套基于双层主题模型的技术主题演化分析框架,该框架利用双层主题模型识别特定时间周期的动态主题,通过基于Word2Vec的主题一致性指标选择最优主题个数,从主题成长性和重要性两方面进行技术主题演化分析;在双层主题模型方面,分别采用基于LDA和基于NMF的双层主题模型识别动态主题,通过主题内一致性和主题间差异度指标评价两种方法识别的技术主题效果,最后选择效果更好的主题识别结果开展演化分析。
通过在资源环境领域的应用研究发现,基于NMF的双层主题模型在动态主题识别上的效果更优,基于技术演化分析发现的“锂金属电池技术”“智能遥感卫星数据分析技术”“人工智能防灾减灾”等代表性技术能够从《麻省理工科技评论》2020年以来发布的突破性技术清单中得到验证。
但是,本文仍存在一些不足。仅对技术从出现到消亡的发展轨迹进行了研究,未关注技术的分裂、衍生和融合等技术演化现象,这些现象如何揭示需要在未来的研究中予以关注。同时,本文专注于对两种双层主题模型(LDA和NMF)的动态主题识别效果进行了深入对比,并未与其他动态主题模型(如DTM[26]等)的效果进行对比,这项工作将在下一步研究中开展。
整体来看,本文方法能够利用特定时间段的文献数据,自动识别动态主题,判断动态主题间关联关系并对主题的演化轨迹进行分析,在实际的科技情报分析工作中具有较高的应用价值,值得推广。