数字图像处理——大作业 基于车道信息的违法车辆车牌识别
数字图像处理——大作业 基于车道信息的违法车辆车牌识别
- 一、车牌识别研究现状与分析
- 二、车牌识别算法原理
-
- 2.1 车牌定位
-
- 2.1.1 基于RGB阈值的车牌区域初定位
- 2.1.2 基于数学形态学的车牌初定位区域连通处理
- 2.1.3 车牌的精确定位
- 2.1.4 相关参考博客
- 2.2 车牌分割
-
- 2.2.1 车牌区域角点校正
- 2.2.2 基于投影的车牌字符分割
- 2.3 车牌字符识别
- 2.4 实验图像说明
- 三、算法流程及实现
-
- 3.1 算法流程
- 3.2 实现结果展示
- 3.3 实现代码
- 参考文献
一、车牌识别研究现状与分析
车牌识别系统广泛应用于交通管理、收费站、城市交叉口、港口和机场、机动车检测、停车场管理等不同的场所,对提高这些场所交通系统的管理水平和自动化程度具有重要的意义[1]。车牌自动识别系统主要包括车牌定位、车牌分割、车牌字符识别三部分。
其中,仅就车牌字符识别而言,目前基于神经网络、字符笔画特征和模糊识别等方法能够有效地识别解析度较高和图像较为清晰的车牌。时下,根据车牌特征信息分析的车牌识别方法也已陆续问世,如文献[2]中,充分利用车牌定位和字符分割过程中得到的信息对车牌识别过程进行反馈,将二值化、车牌定位和字符分割紧密结合,注重车牌与车辆背景图像分离特征,以连通域分析为字符分割特点,提高正确率。文献[3]采用径向基神经网络(RBFNN)识别车牌,RBFNN的算法采用混合结构优化算法,在识别中使用非全字符输入和多层识别器。混合结构优化算法简化了RBFNN的结构,提高了RBFNN的泛化能力; 非全字符简化了RBFNN的输入,提高了车牌识别的速度; 多层识别器保证了非全字符输入的识别率。将RBFNN的混合结构算法和非全字符输入、多层识别器相结合,在保证识别率的基础上,提高了识别速度。文献[3]中的仿真试验表明: 相对于全字符输入的车牌识别,该方法在时间复杂度上的表现非常优秀; 相对于K-means算法的RBFNN车牌识别,其方法在泛化能力上有一定的优势。
二、车牌识别算法原理
2.1 车牌定位
当人们从远处观察车辆时,判别牌照区域的主要依据是车牌的颜色、亮度和车牌字符的边缘形成的纹理。所以,充分利用这些信息就成了定位车牌的关键。牌照区域有别于其他区域的地方就在于牌照上有字符,结合国内车牌的特征,国内的汽车牌照内容由数字、字母和汉字组成。首位字符是汉字部分,其次是24个英文字符中的一个 (字母O和I除外),后面五位是数字和字母的组合。
根据中国车牌字符的特征制作模板,使用模板匹配的方法来识别字符的识别率较高。图像的灰度水平投影具有较好的连续性,不会有大的起伏,体现在纹理信息上就是其垂直边缘的间距呈现出相应规律[4]。
2.1.1 基于RGB阈值的车牌区域初定位
在本次课程设计中,采用的是车牌定位中较为简单的基于RGB图像阈值的车牌定位方法。查阅资料得知,正常光线强度情况下,车牌蓝色的RGB分量值如 表1 所示:
| 分量 | 蓝色 |
|---|---|
| R | 23 |
| G | 63 |
| B | 138 |
但在大多数情况下,采集到的车牌图像是不能保证正常曝光的,因此需要预设一个阈值以保证不在正常曝光下的车牌区域也能被定位到。计算图像的每个像素点的RGB值与正常曝光下的车牌蓝色RGB值之间的差值,若在阈值范围之内,则认定是车牌区域;若超过阈值,则认定不是车牌区域。依据该方法,可以从采集到的输入图像中获取疑似车牌的区域,该区域可能存在多个,许多符合条件的非车牌区域像素点也有可能存在其中,接下来需要用形态学的方法进一步处理定位出的车牌以获取最终的牌照区域。
2.1.2 基于数学形态学的车牌初定位区域连通处理
如果仅仅依靠蓝色的RGB分量值来定位车牌位置的话,由于外界的光线强度孰强孰弱、采集到的图像中也有可能存有蓝色区域等干扰因素,使得定位出的车牌位置可能存在多个,非常难确定正确的车牌区域。所以,需要用数学形态学的相关操作对图像做相应的处理以为后续的筛选过程做准备。首先对图像做膨胀操作,目的是将车牌区域的各个字符连接为一个整体,然后再对输入图像作形态学腐蚀操作,目的是去掉图像中孤立的噪声点。经形态学操作处理输入图像之后,车牌区域会被规划成一个较为规整的倾斜的长方形区域。
2.1.3 车牌的精确定位
经形态学方法处理之后,图中绝大多数孤立的噪声点已被清除,且车牌区域呈现出一个较为规则的矩形。由于数学形态学处理会减少车牌的信息以及车牌区域发生倾斜等原因,所以预设车牌的宽高比例会比正常情况下的比例范围要更大,设定宽高比例阈值为2.0-5.5,最小面积为200。根据车牌的宽高比例以及预设的最小面积等特征,将不符合条件的可疑矩形区域排除掉,剩下的矩形区域就是车牌区域,并在原始图像上用红色边框表示。
2.1.4 相关参考博客
汽车车牌识别系统实现(二)–车牌定位+代码实现_奋斗丶的博客-CSDN博客_车牌识别代码实现
车牌分割实战_勇敢牛牛@的博客-CSDN博客
2.2 车牌分割
2.2.1 车牌区域角点校正
在进行车牌分割任务之前,需进行车牌区域的角点校正。由于拍摄车牌的相机位置原因,拍摄得到的图像有极大可能是存在畸变的,因而有必要在进行车牌字符分割之前先进行车牌区域图像的去畸变。
通常去畸变采用的是透视变换 (Perspective Transformation) 方法。透视变换是将图片投影到一个新的视平面 (Viewing Plane),也称作投影映射 (Projective Mapping)。透视变换的目的就是把现实中为直线的物体,在图片上可能呈现为斜线,通过透视变换转换成直线的变换。opencv-python 也提供了十分方便的图像去畸变方案,通过 cv2.getPerspectiveTransform() 函数获取透视变换矩阵后,再通过 cv2.warpPerspective() 函数即可实现透视变换,将包含畸变的车牌图像进行相应的校正。
参考博客:【代码篇】opencv实现图像校正(python版)_Zero_0-1的博客-CSDN博客_python图片梯形校正
2.2.2 基于投影的车牌字符分割
车牌分割的好坏将直接关系着车牌识别效果。通过前述步骤进行车牌定位和图像预处理后,下面就是二值化的字符分割环节。常见的字符分割方法有模板匹配、聚类分析[5]、投影分割等3种方法,在执行分割之前先找到有效区域,并截取有效区域作为分割区域。在检测有效区域时采用行列扫描的方法,先通过统计跳变次数找到上下边界,再通过从左和从右逐列地扫描,认为白色边界最多的是起始列。
通过该方法将车牌中的字符单独分割出来,并且去除每个字符的上下方向上多余的边框。因此得到的字符分割结果,字符应该占满整个分割图像区域。为了便于后期的识别,因此将分割结果图片统一缩放为 25*15 大小。
2.3 车牌字符识别
目前,车牌识别的技术相对来说已趋于成熟,车牌识别的方法也较为多样。一般情况下,利用传统的模板匹配方法来进行车牌识别,识别率已经会达到较高水平,因而无需采用目前大火的深度学习的方法。
本次课程设计采用的就是较为经典的模板匹配进行车牌字符识别,将车牌字符的分割结果 I I I 分别与模板 I ′ I' I′ 进行对比,得出其差值 ∣ I − I ′ ∣ |I-I'| ∣I−I′∣,则所得差值最小的模板即为识别结果。需要额外说明的一点是,由于 opencv-python 中自带 cv2.matchTemplate() 函数,因而在实际实现模板匹配过程中直接是调用该函数计算的。
2.4 实验图像说明
本次实验将使用到一张复杂场景下待车牌识别的图像如 图1 所示:

模板数据与我之前简单场景下车牌识别提供的数据相同,具体可参考:数字图像处理—— 实验五 基于图像分割的车牌定位识别_lan 606的博客-CSDN博客
具体的数据我已打包分享至如下百度网盘链接:5-carNumber_免费高速下载|百度网盘-分享无限制 (baidu.com)
三、算法流程及实现
3.1 算法流程
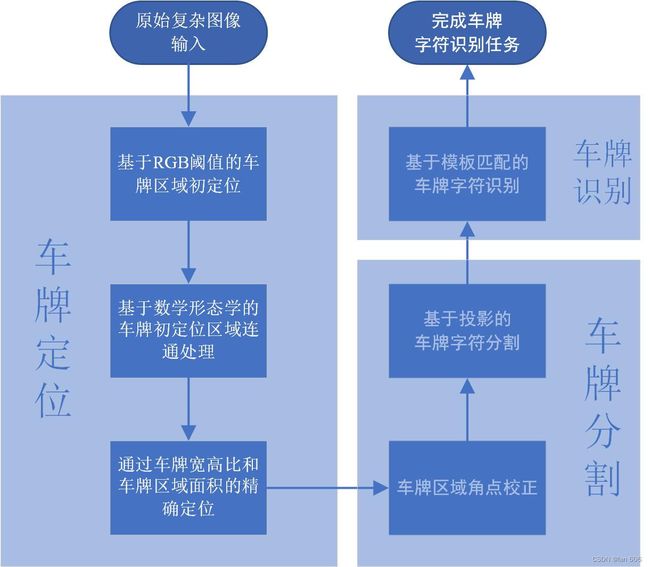
整体的任务流程如报告第二章所述,现给出车牌识别任务的整体框架如 图2 所示:
3.2 实现结果展示
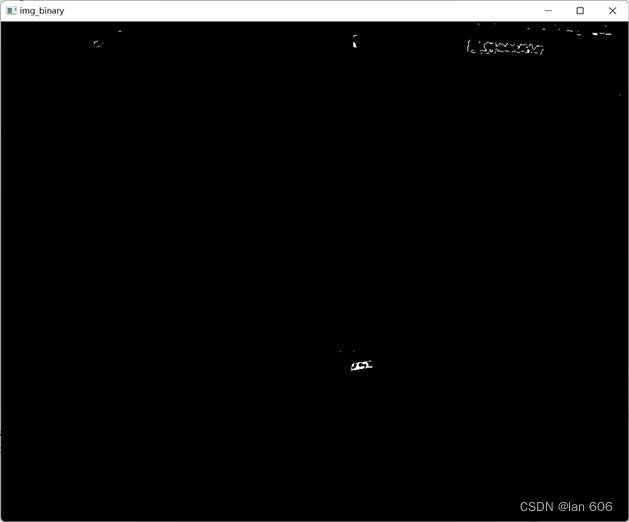
通过rgb阈值初步筛选过后的二值化图像(与给定阈值相近的赋值为255,其余像素点赋值为0):
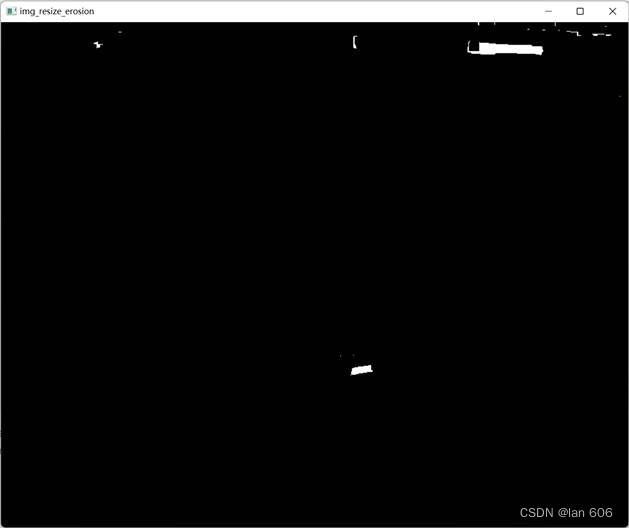
在上述提取出来的二值化图像基础上,进一步通过数学形态学操作(先膨胀后腐蚀),使得车牌区域连通为一整个块:
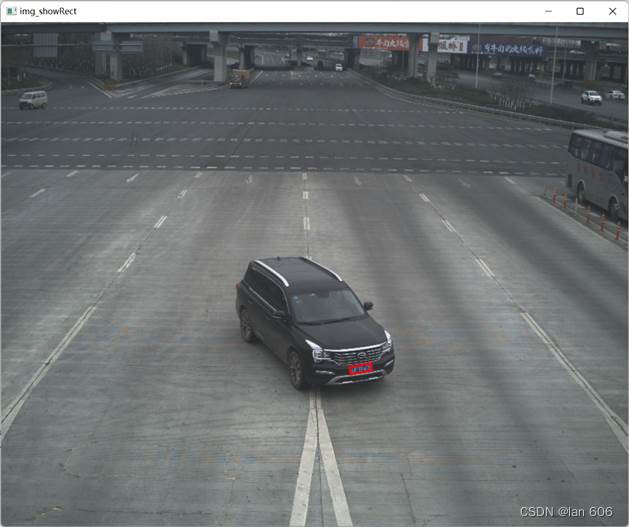
最终提取出来的图像(给车牌区域打上红色方框):
初步提取出来的车牌:

对初步提取出来的车牌进行角点校正,方便后续车牌识别过程:

对角点校正后的图像进行二值化:

通过车牌字符分割方法对车牌上几个字符的分割结果:





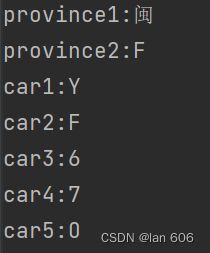
最终的车牌识别结果:
-
注:关于识别结果的说明
由于原始图片上汉字 “川” 存在阴影,尽管在实验过程中通过灰度直方图调整等方法进行处理,但依旧无法正确识别。将分割出来的字符单独拎出如 图11 所示,可以看到存在缺失的汉字确实与闽相似。所以模板匹配的方法对原始输入图像的要求较高,想要获得具有一定鲁棒性的车牌识别算法,还是需要采用深度学习算法。

图11. 单独的“川”字提取
3.3 实现代码
# 数字图像处理期末课程设计1:基于车道信息的违法车辆车牌识别
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 展示图片的函数
def pic_display(dis_name, dis_image):
cv2.imshow(dis_name, dis_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 1.车牌定位
def license_region(image):
img_b = cv2.split(image)[0]
img_g = cv2.split(image)[1]
img_r = cv2.split(image)[2]
# 彩色信息特征初步定位:车牌定位并给resize后的图像二值化赋值
standard_b = 138
standard_g = 63
standard_r = 23
standard_threshold = 50
img_test = image.copy()
for i in range(img_test.shape[0]):
for j in range(img_test.shape[1]):
# 提取与给定的r、g、b阈值相差不大的点(赋值为全白)
if abs(img_b[i, j] - standard_b) < standard_threshold \
and abs(img_g[i, j] - standard_g) < standard_threshold \
and abs(img_r[i, j] - standard_r) < standard_threshold:
img_test[i, j, :] = 255
# 其他所有的点赋值为全黑
else:
img_test[i, j, :] = 0
pic_display('img_binary', img_test)
# 基于数学形态学进一步精细定位车牌区域
kernel = np.ones((3, 3), np.uint8)
img_resize_dilate = cv2.dilate(img_test, kernel, iterations=5) # 膨胀操作
img_resize_erosion = cv2.erode(img_resize_dilate, kernel, iterations=5) # 腐蚀操作
pic_display('img_resize_erosion', img_resize_erosion)
# cv2.cvtColor()函数将 三通道 的二值化图像转变为 单通道 的二值化图像
img1 = cv2.cvtColor(img_resize_erosion, cv2.COLOR_BGR2GRAY)
contours = cv2.findContours(img1, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)[1]
# 通过区域面积,宽高比例的方式进一步筛选车牌区域
MIN_AREA = 200 # 设定矩形的最小区域,用于去除无用的噪声点
car_contours = []
for cnt in contours: # contours是长度为18的一个tuple(元组)
# 框选 生成最小外接矩形 返回值(中心(x,y), (宽,高), 旋转角度)rect[0]:矩形中心点坐标;rect[1]:矩形的高和宽;rect[2]:矩形的旋转角度
rect = cv2.minAreaRect(cnt)
area_width, area_height = rect[1]
# 计算最小矩形的面积,初步筛选
area = rect[1][0] * rect[1][1] # 最小矩形面积
if area > MIN_AREA:
if area_width < area_height: # 选择宽小于高的区域进行宽和高的置换
area_width, area_height = area_height, area_width
# 求出宽高之比(要求矩形区域长宽比在2到5.5之间,其他的排除)
wh_ratio = area_width / area_height
if 2 < wh_ratio < 5.5:
car_contours.append(rect)
box = cv2.boxPoints(rect) # 存放最小矩形的四个顶点坐标(先列后行的顺序)
box = np.int0(box) # 去除小数点,只保留整数部分
region_out = box
return region_out
# 读取需检测的图片
img = cv2.imdecode(np.fromfile(r'./data/Course_Design_1/1基于车道的违法车辆照片1.jpg', dtype=np.uint16), -1)
img = img[97:, :, :] # 去除原始图片最上面的黑边
# 原始图片过大,压缩为原始图像尺寸的1/3,方便opencv-python出图展示
img_resize = cv2.resize(img, None, fx=1 / 3, fy=1 / 3, interpolation=cv2.INTER_CUBIC)
# 对原始图片进行平滑和滤波处理
# 高斯平滑
img_resize_gaussian = cv2.GaussianBlur(img_resize, (5, 5), 1)
# 中值滤波
img_resize_median = cv2.medianBlur(img_resize_gaussian, 3)
# 定位车牌区域并绘图展示
region = license_region(img_resize_median)
# 在原始图像中用红色方框标注
img_showRect = img_resize.copy()
img_showRect = cv2.drawContours(img_showRect, [region], 0, (0, 0, 255), 2)
pic_display('img_showRect', img_showRect)
# 将车牌区域提取出来
region_real = region*3
car_region = img[np.min(region_real[:, 1]):np.max(region_real[:, 1])+5,
np.min(region_real[:, 0]):np.max(region_real[:, 0])+10, :]
pic_display('car_region', car_region)
# 2.对车牌区域进行角点校正
# 原始车牌的四个角点(左下、左上、右下、右上,先列后行)
pts1 = np.float32([[7, 47], [9, 23], [100, 35], [102, 9]])
# 变换后分别在左下、左上、右下、右上四个点
pts2 = np.float32([[0, 50], [0, 0], [110, 50], [110, 0]]) # 对应resize后的图像尺寸大小
# 生成透视变换矩阵
M = cv2.getPerspectiveTransform(pts1, pts2)
# 进行透视变换
dst = cv2.warpPerspective(car_region, M, (110, 50))
plt.subplot(121), plt.imshow(car_region[:, :, ::-1]), plt.title('input') # img[:, :, ::-1]是将BGR转化为RGB
plt.subplot(122), plt.imshow(dst[:, :, ::-1]), plt.title('output')
plt.show()
# 3.车牌区域灰度化、二值化
car_region_gray = cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY) # 将RGB图像转化为灰度图像
# # otus二值化
# car_region_binary = cv2.threshold(car_region_gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# 普通二值化方法
car_region_binary = cv2.threshold(car_region_gray, 87, 255, cv2.THRESH_BINARY)[1]
pic_display('car_region_binary', car_region_binary)
# 4.车牌分割(均分割为25*15的图片)height=25,width=15
# 模板分割函数,只针对单个字符,用于去除其周围的边缘,并resize
def template_segmentation(origin_img):
# 提取字符各列满足条件(有两个255的单元格)的索引
col_index = []
for col in range(origin_img.shape[1]): # 对于图像的所有列
if np.sum(origin_img[:, col]) >= 2*255:
col_index.append(col)
col_index = np.array(col_index)
# 提取字符各行满足条件(有两个255的单元格)的索引
row_index = []
for row in range(origin_img.shape[0]):
if np.sum(origin_img[row, :]) >= 2*255:
row_index.append(row)
row_index = np.array(row_index)
# 按索引提取字符(符合条件的行列中取min-max),并resize到25*15大小
output_img = origin_img[np.min(row_index):np.max(row_index)+1, np.min(col_index):np.max(col_index)+1]
output_img = np.uint8(output_img)
if col_index.shape[0] <= 3 or row_index.shape[0] <= 3:
output_img = origin_img[np.min(row_index):np.max(row_index)+1, np.min(col_index):np.max(col_index)+1]
pad_row1 = np.int8(np.floor((25 - output_img.shape[0]) / 2))
pad_row2 = np.int8(np.ceil((25 - output_img.shape[0]) / 2))
pad_col1 = np.int8(np.floor((15 - output_img.shape[1]) / 2))
pad_col2 = np.int8(np.ceil((15 - output_img.shape[1]) / 2))
output_img = np.pad(output_img, ((pad_row1, pad_row2), (pad_col1, pad_col2)), 'constant',
constant_values=(0, 0))
output_img = np.uint8(output_img)
else:
output_img = cv2.resize(output_img, (15, 25), interpolation=0)
return output_img
# 对原始车牌抠图,抠出每一个字符
temp_col_index = []
car_region_binary[47:50, :] = 0
car_region_binary[:, 0:4] = 0
car_region_binary[:, -1] = 0
for col in range(car_region_binary.shape[1]):
if np.sum(car_region_binary[:, col]) > 5*255: # 提取大于5个255的列
temp_col_index.append(col)
temp_col_index = np.array(temp_col_index)
flag = 0 # 值是7个字符的起始列
flag_i = 0 # 值的变化范围:从0到6(对应车牌的7个字符)
car_license_out_col = np.uint8(np.zeros([7, 30])) # 7行的数组存储车牌上的7个需识别的字
for j in range(temp_col_index.shape[0]-1):
# 提取的>=3个255的列之间不是相邻的且至少有8长度的字符
if temp_col_index[j+1]-temp_col_index[j] >= 3 and (temp_col_index[j+1]-temp_col_index[flag]) >= 8:
temp = temp_col_index[flag:j+1]
temp = np.append(temp, np.zeros(30-temp.shape[0])) # 补成30维的向量,方便最后赋值给car_license_out_col
temp = np.uint8(temp.reshape(1, 30))
car_license_out_col[flag_i, :] = temp
flag = j+1
flag_i = flag_i+1
temp = temp_col_index[flag:]
temp = np.append(temp, np.zeros(30-temp.shape[0]))
temp = np.uint8(temp.reshape(1, 30))
car_license_out_col[flag_i, :] = temp
# 分别提取7个字符(通过行进行筛选)
car_license_out_row = np.uint8(np.zeros([7, 30]))
for row in range(car_license_out_row.shape[0]): # 对应车牌上的7个字符
temp = car_license_out_col[row, :]
index = 0
for i in range(temp.shape[0]): # 去除列索引中多余的0
if temp[i] == 0:
index = i
break
col_temp = temp[0:index]
temp_img = car_region_binary[:, np.min(col_temp):np.max(col_temp)+1]
t = np.nonzero(np.sum(temp_img, axis=1))
if row == 0:
province1 = temp_img[t, :] # 汉字后续扩展成40*40
province1 = province1[0, :, :]
province1 = template_segmentation(province1)
province1 = np.uint8(province1)
if row == 1:
province2 = temp_img[t, :] # 字母和数字后续扩展成40*40
province2 = province2[0, :, :]
province2 = template_segmentation(province2)
province2 = np.uint8(province2)
if row == 2:
car_number1 = temp_img[t, :]
car_number1 = car_number1[0, :, :]
car_number1 = template_segmentation(car_number1)
car_number1 = np.uint8(car_number1)
if row == 3:
car_number2 = temp_img[t, :]
car_number2 = car_number2[0, :, :]
car_number2 = template_segmentation(car_number2)
car_number2 = np.uint8(car_number2)
if row == 4:
car_number3 = temp_img[t, :]
car_number3 = car_number3[0, :, :]
car_number3 = template_segmentation(car_number3)
car_number3 = np.uint8(car_number3)
if row == 5:
car_number4 = temp_img[t, :]
car_number4 = car_number4[0, :, :]
car_number4 = template_segmentation(car_number4)
car_number4 = np.uint8(car_number4)
if row == 6:
car_number5 = temp_img[t, :]
car_number5 = car_number5[0, :, :]
car_number5 = template_segmentation(car_number5)
car_number5 = np.uint8(car_number5)
cv2.imshow('province1', province1)
cv2.imshow('province2', province2)
cv2.imshow('car_number1', car_number1)
cv2.imshow('car_number2', car_number2)
cv2.imshow('car_number3', car_number3)
cv2.imshow('car_number4', car_number4)
cv2.imshow('car_number5', car_number5)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 5.车牌识别
# 读取所有的字母字符列表及其模板
Alphabet_character = open(r'./data/5-carNumber./英文.txt', encoding="gbk").read()
Alphabet_character = Alphabet_character.split("\n")
Alphabet_char_template = np.load(r'./data/5-carNumber/Alphabet_char_template.npy')
# 读取所有的汉字字符列表及其模板
Chinese_character = open(r'./data/5-carNumber./汉字.txt', encoding="gbk").read()
Chinese_character = Chinese_character.split("\n")
Chinese_char_template = np.load(r'./data/5-carNumber/Chinese_char_template.npy')
# 读取所有的数字字符列表及其模板
Number_character = open(r'./data/5-carNumber./数字.txt', encoding="gbk").read()
Number_character = Number_character.split("\n")
Number_char_template = np.load(r'./data/5-carNumber/Number_char_template.npy')
# 进行字符识别
car_character = np.uint8(np.zeros([7, 25, 15]))
car_character[0, :, :] = province1.copy()
car_character[1, :, :] = province2.copy()
car_character[2, :, :] = car_number1.copy()
car_character[3, :, :] = car_number2.copy()
car_character[4, :, :] = car_number3.copy()
car_character[5, :, :] = car_number4.copy()
car_character[6, :, :] = car_number5.copy()
match_length = Chinese_char_template.shape[0]+Alphabet_char_template.shape[0]+Number_char_template.shape[0]
match_mark = np.zeros([7, match_length])
Chinese_char_start = 0
Chinese_char_end = Chinese_char_template.shape[0]
Alphabet_char_start = Chinese_char_template.shape[0]
Alphabet_char_end = Chinese_char_template.shape[0]+Alphabet_char_template.shape[0]
Number_char_start = Chinese_char_template.shape[0]+Alphabet_char_template.shape[0]
Number_char_end = match_length
for i in range(match_mark.shape[0]): # 7个需识别的字符
for j in range(Chinese_char_start, Chinese_char_end): # 所有的汉字模板
match_mark[i, j] = cv2.matchTemplate(car_character[i, :, :], Chinese_char_template[j, :, :], cv2.TM_CCOEFF)
# 所有的字母模板
for j in range(Alphabet_char_start, Alphabet_char_end):
match_mark[i, j] = cv2.matchTemplate(car_character[i, :, :],
Alphabet_char_template[j-Alphabet_char_start, :, :],
cv2.TM_CCOEFF)
# 所有的数字模板
for j in range(Number_char_start, Number_char_end):
match_mark[i, j] = cv2.matchTemplate(car_character[i, :, :],
Number_char_template[j-Number_char_start, :, :],
cv2.TM_CCOEFF)
output_index = np.argmax(match_mark, axis=1)
output_char = []
for i in range(output_index.shape[0]):
if 0 <= output_index[i] <= 28:
output_char.append(Chinese_character[output_index[i]])
if 29 <= output_index[i] <= 54:
output_char.append(Alphabet_character[output_index[i]-29])
if 55 <= output_index[i] <= 64:
output_char.append(Number_character[output_index[i]-55])
# 打印识别结果
for i in range(len(output_char)):
if i == 0:
print('province1:' + output_char[0])
if i == 1:
print('province2:' + output_char[1])
if i == 2:
print('car1:' + output_char[2])
if i == 3:
print('car2:' + output_char[3])
if i == 4:
print('car3:' + output_char[4])
if i == 5:
print('car4:' + output_char[5])
if i == 6:
print('car5:' + output_char[6])