Python爬虫和数据可视化
文章目录
- Python基础知识
-
- Python基础
-
- 变量及类型
- 标识符和关键字
- 格式化输出
- 输入
- import导入包
- 判断语句和循环语句
-
- 条件判断语句
- 循环语句
- 字符串、列表、元组、字典
-
- 字符串
-
- 字符串的常见操作
- 列表
-
- 常见操作
- 元组
- 字典
-
- 常用操作
- 集合
- 小结
- 函数
-
- 函数的概念
- 函数定义和调用
-
- 定义函数
- 调用函数
- 函数参数
-
- 定义带有参数的函数
- 调用带有参数的函数
- 全局变量和局部变量
-
- 什么是局部变量
- 什么是全局变量
- 函数使用注意事项
-
- 调用函数
- 作用域
- 文件操作
-
- 文件的打开与关闭
-
- 访问模式
- 写数据
- 读数据
- 文件的相关操作
-
- 文件重命名
- 删除文件
- 创建文件夹
- 获取当前目录
- 改变默认目录
- 获取目录列表
- 删除文件夹
- 错误与异常
- Python爬虫
-
- 任务介绍
- 爬虫初识
- 基本流程
-
- 准备工作
-
- 分析页面
- 编码规范
- 引入模块
- 获取数据
-
- urllib
- 解析内容
-
- 标签解析
- 补充BeautifulSoup
- 正则提取
- 补充re模块
- 保存数据
-
- Excel表存储
- 补充利用xlwt库来存储excel表格
- 使用数据库存储
- 补充SQLite
- 数据可视化
-
- Flask入门
-
- 关于Flask
- 为什么要用Web框架?
- Flask框架的诞生
- 补充flask
- ECharts应用
-
- 补充ECharts
- WordCloud应用
-
- WordCloud示例
-
- 安装
Python基础知识
Python基础
变量及类型
-
变量可以是任何的数据类型,在程序中用一个变量名表示
-
变量名必须是大小写英文、数字和下划线(_)的组合,且不能以数字开头
-

标识符和关键字
-
什么是关键字
python一些具有特殊功能的标示符
不允许开发者自己定义和关键字相同的名字的标示符
-
查看关键字:
import keyword
keyword.kwlist
格式化输出
age = 18
print("我的年纪是:%d 岁"%age)
# %s输出字符串 %d输出十进制整数
print("我的名字是%s,我的国籍是%s"%("小张","中国")) #用元组
print("aaa","bbb","ccc")#aaa bbb ccc
print("www","baidu","com",sep=",") #www.baidu.com
print("hello",end="")#不换行
print("python",end="\t")#以 结尾
print("world",end="\n") #以换行符结尾
输入
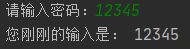
password = input("请输入密码:")
print("您刚刚输入的密码是:",passward)

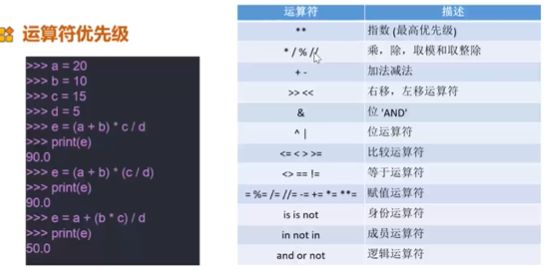
import导入包

判断语句和循环语句
条件判断语句

循环语句
name="chengdu"
for x in name:
print(x,end="\t")
#c h e n g d u

字符串、列表、元组、字典
字符串
Python的核心数据类型

paragraph="""
这是一个段落
可以由多行组成
"""
my_str = "Jason said\"I like you\"" #转义字符
推荐使用双引号。
print(r"hello \nchengdu") #在字符串前面加r,表示直接显示原始字符串,不进行转义
#hello\nchengdu
字符串的常见操作




还有很多方法,可以使用时自行搜索
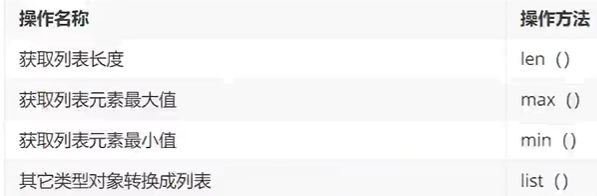
列表

常见操作

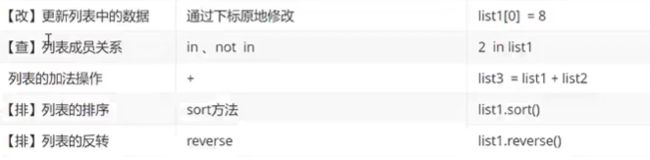
a = [1,2]
b = [3,4]
a.append(b)
print(a) # [1,2,[3,4]]
a.extend(b)
print(a) #[1,2,[3,4],3,4]
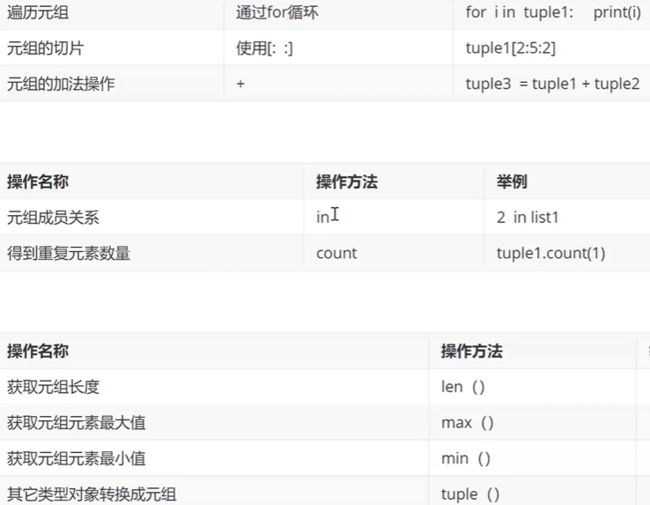
元组

新增操作类似于连接、新建
删除不是删除元组中的元素,而是删除了整个元组
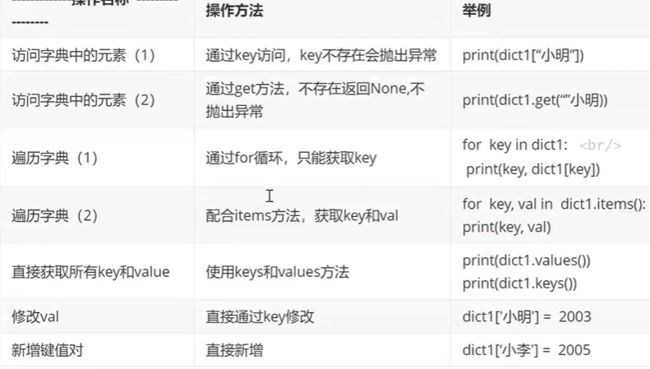
字典

直接访问键,如果键值不存在会报错;如果使用dict.get("keyName"),找不到的话会默认返回None;dict.get("KeyName","Newvalue"),如果找不到键值,会返回一个新的值
常用操作

集合


小结

函数
函数的概念
如果在开发程序时,需要某块代码多次,但是为了提高编写的效率以及代码的重用,所以把具有独立功能的代码块组织为一个小模块,这就是函数。
函数定义和调用
定义函数
函数定义的格式如下:
def 函数名():
代码
调用函数
函数名()
函数参数
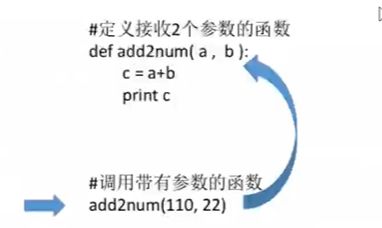
定义带有参数的函数
示例:
def add2num(a, b):
c = a + b
print c
调用带有参数的函数
示例:
add2num(11,22)
全局变量和局部变量
什么是局部变量
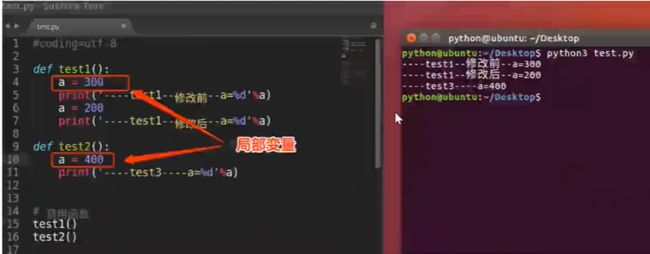
- 局部变量,就是函数内部定义的变量
- 不同的函数,可以定义相同名字的局部变量,但是各用个的不会产生影响
- 局部变量的作用,为了临时保存数据需要在函数中定义变量来进行存储,这就是它的作用
什么是全局变量
如果一个变量,它既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量
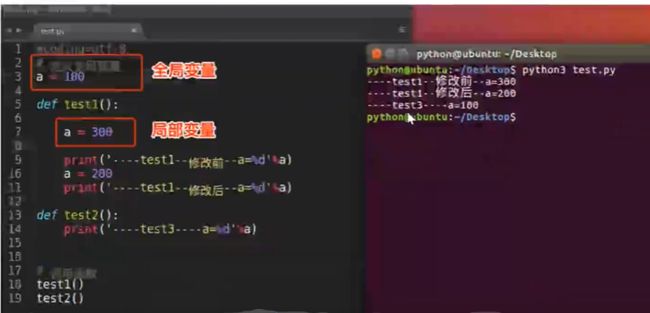
- 定义在函数外面的变量叫做全局变量
- 全局变量能够在所有的函数中进行访问
- 如果在函数中修改全局变量,那么就需要使用
global来进行声明,否则出错 - 如果全局变量和局部变量重名,那么使用的是局部变量的
函数使用注意事项


调用函数
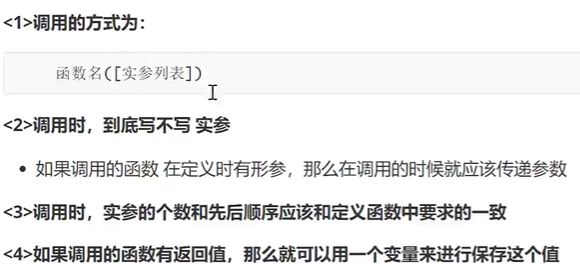
作用域

文件操作
文件,就是把一些数据存放起来,可以让程序下一次执行的时候直接使用,而不必重新制作一份,省时省力
文件的打开与关闭

f = open('test.txt','w') #打开文件
f.close() #关闭文件
访问模式

写数据
使用write()可以完成文件写入数据
- 如果文件不存在那么创建,如果存在那么就先清空,然后写入数据
读数据
read(num)方法,读取指定的字符,开始时定位在文件头部,每执行一次向后移动指定字符数。

-
readlines()方法,按照行的方式把整个文件中的内容进行一次读取,返回的是一个列表,其中每一行的数据为一个元素 -
readline()方法,一次只读一行数据
文件的相关操作
有些时候,需要对文件进行重命名、删除等一些操作,python的os模块中都有这些功能
文件重命名
os模块中的rename()可以完成对文件的重命名操作
rename(需要修改的文件名,新的文件名)
删除文件
os模块中的remove()可以完成对文件的删除操作
remove(待删除的文件名)
创建文件夹
import os
os.mkdir("张三")
获取当前目录
import os
os.getcwd()
改变默认目录
import os
os.chdir("../")
获取目录列表
import os
os.listdir("./")
删除文件夹
import os
os.rmdir("张三")
错误与异常
异常是预料到的,可以针对进行处理的
try:
xxxx
except Exception as e:
try:
xxxxx
except Exception as e:
xxxxx
finally:
xxxxx
还可以嵌套
Python爬虫
任务介绍

爬虫初识

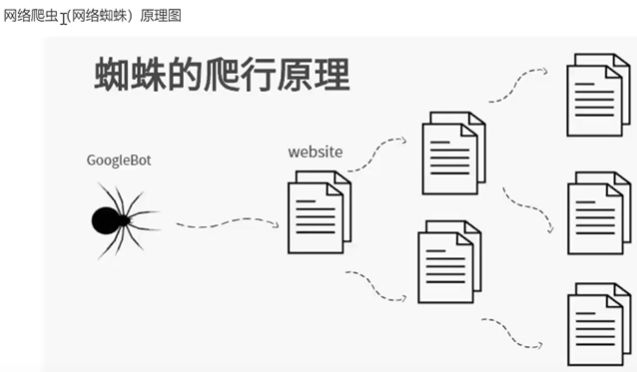
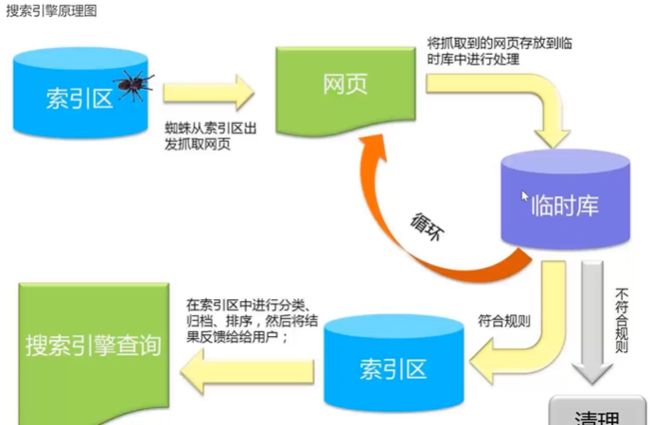
基本流程

准备工作

分析页面
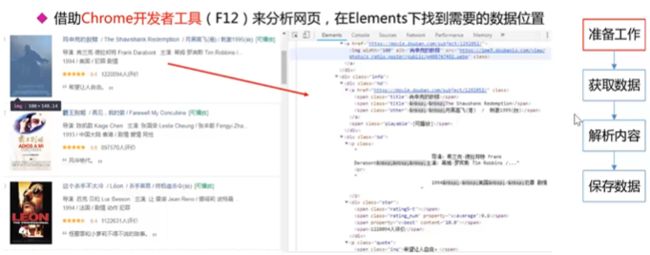
编码规范

引入模块

获取数据

urllib
http://httpbin.org/ 这个网站可以测试你的请求得到了什么相应
# -*- codeing = utf-8 -*-
# @File : testUrllib.py
# @Software: PyCharm
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com") #HTTPResponse
#print(response.read())#网页的源代码
#print(response.read().decode('utf-8'))#用utf-8的形式解析
#获取一个post请求 (模拟用户真实登录请求
import urllib.parse #解析器
#data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding='utf-8')
#response = urllib.request.urlopen("http://httpbin.org/post",data=data)
#print(response.read().decode("utf-8"))
#get请求
#response = urllib.request.urlopen("http://httpbin.org/get")
#print(response.read().decode("utf-8"))
#超时怎么办?
#超时处理:try....catch
#如果连接出现死链接等情况,需要用到超时处理
# try:
# response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
# print(response.read().decode("utf-8"))
# except urllib.error.URLError as e:
# print("time out!")
# response = urllib.request.urlopen("http://www.baidu.com")
# print(response.status) #状态码 #当被人发现是爬虫时会返回418
# print(response.getheaders())
# print(response.getheader("Server")) #拿到具体的一个头信息
#通过在headers中加入网页的所有真实键值对 来模拟浏览器
#url = "https://www.douban.com"
#url = "http://httpbin.org/post"
# headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
# }
# data = bytes(urllib.parse.urlencode({'name':'eric'}),encoding="utf-8")
# req = urllib.request.Request(url=url, data=data, headers=headers, method="POST") #对象封装
# response = urllib.request.urlopen(req) #将封装的对象进行传输
# print(response.read().decode("utf-8"))
url = "https://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
req = urllib.request.Request(url=url, headers=headers) #对象封装
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
解析内容

标签解析
补充BeautifulSoup
得到网页中某一个指定内容的匹配工具
# -*- codeing = utf-8 -*-
# @File : testBs4.py
# @Software: PyCharm
# BeautifulSoup4将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归为4种
# -Tag -NavigableString -BeautifulSoup -Commet
from bs4 import BeautifulSoup
file = open("./baidu.html","rb")
html = file.read().decode("utf-8")
bs = BeautifulSoup(html,"html.parser") #指定解析器来解析html文档
#print(bs.title) #百度一下,你就知道
#print(bs.a) #
#print(type(bs.head)) #正则提取

补充re模块



# -*- codeing = utf-8 -*-
# @Time : 2021/6/8 11:52
# @Author : TangSiyu
# @File : testRe.py
# @Software: PyCharm
# 正则表达式:字符串模式(判断字符串是否符合一定的标准)
import re
#创建模式对象
pat = re.compile("AA") #此处的AA,是正则表达式,用来去验证其他的字符串
#m = pat.search("CBA") #search字符串被校验的内容
#m = pat.search("ABCAA")
#m = pat.search("ABCAADDCCAAA") #只会找到第一个匹配的位置
# 没有模式对象
# m = re.search("asd","Aasd") #前面的字符串是规则(模版),后面的是被校验的对象
# print(m)
#print(re.findall("a","ADFaDFGAa")) #前面字符串是规则(正则表达式),后面是被校验的字符串
#print(re.findall("[A-Z]","ADFaDFGAa"))
#print(re.findall("[A-Z]+","ADFaDFGAa"))
#sub
#print(re.sub("a","A","abcdcasd")) #找到a用A来替换,在第三个字符串中查找
#建议在正则表达式中,被比较的字符串前面加上r,不用担心转义字符的问题
# a = r"\adgae-\'"
# print(a)
保存数据
Excel表存储
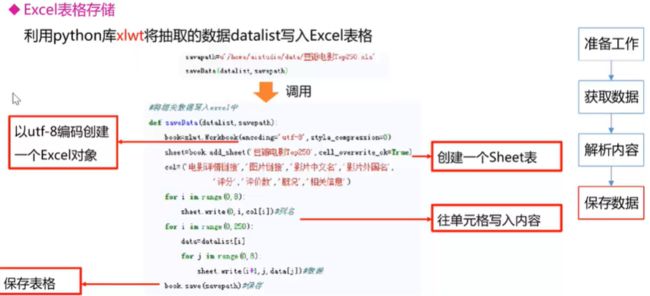
补充利用xlwt库来存储excel表格
# -*- codeing = utf-8 -*-
# @File : testXwlt.py
# @Software: PyCharm
import xlwt
# workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
# worksheet = workbook.add_sheet('sheet1') #创建工作表
# worksheet.write(0,0,'hello') #写入数据,第一个参数“行”,第二个参数“列”,写入内容
# workbook.save('student.xls') #保存数据表
#写入九九乘法表
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
worksheet = workbook.add_sheet('sheet1') #创建工作表
x = 1
while x <= 9:
for i in range(x):
worksheet.write(x-1, i, "{}×{}={}".format(x,i+1,(x*(i+1))))
x += 1
workbook.save('九九乘法表.xls') #保存数据表
使用数据库存储
补充SQLite
常见操作
# -*- codeing = utf-8 -*-
# @File : testSqlite.py
# @Software: PyCharm
import sqlite3
# # 1.连接数据库
# conn = sqlite3.connect("test.db") #打开或创建数据库文件
#
# print("成功打开数据库")
# # 2.创建数据表
# c = conn.cursor() #获取游标
#
# sql = '''
# create table company
# (id int primary key not null,
# name text not null,
# age int not null,
# address char(50),
# salary real);
# '''
#
# c.execute(sql) #执行sql语句
# conn.commit() #提交数据库操作
# conn.close() #关闭数据库连接
#
# print("成功建表")
# 3.插入数据
# conn = sqlite3.connect("test.db") #打开或创建数据库文件
# print("成功打开数据库")
#
# c = conn.cursor() #获取游标
#
# sql1 = '''
# insert into company(id,name,age,address,salary)
# values (1,'张三',32,'成都',8000);
# '''
#
# sql2 = '''
# insert into company(id,name,age,address,salary)
# values (2,'李四',30,'重庆',15000);
# '''
#
# c.execute(sql1) #执行sql语句
# c.execute(sql2)
# conn.commit() #提交数据库操作
# conn.close() #关闭数据库连接
#
# print("成功插入数据")
# 4.查询数据
conn = sqlite3.connect("test.db") #打开或创建数据库文件
print("成功打开数据库")
c = conn.cursor() #获取游标
sql = "select id,name,address,salary from company"
c.execute(sql) #执行sql语句
for row in c:
print("id = ",row[0])
print("name = ",row[1])
print("address = ",row[2])
print("salary = ", row[3],"\n")
conn.close() #关闭数据库连接
print("查询数据完毕")
数据可视化
Flask入门
关于Flask


为什么要用Web框架?
web网站发展至今,特别是服务器端,涉及到的知识、内容,非常广泛。这对程序员的要求会越来越高。如果采用成熟,稳健的框架,那么一些基础的工作,比如,网络操作、数据库访问、会话管理等都可以让框架来处理,那么程序开发人员可以把精力放在具体的业务逻辑上面。使用Web框架开发Web应用
总结一句话:避免重复造轮子
Flask框架的诞生
Flask诞生于2010年,是Armin ronacher(人名)用Python语言基于Werkzeug工具箱编写的轻量级Web开发框架。它主要面向需求简单的小应用。
Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件扩展Flask-Mail,用户认证Flask-Login),都需要用第三方的扩展来实现。比如可以用Flask-extension加入ORM、窗体验证工具,文件上传、身份验证等。Flask没有默认使用的数据库,你可以选择MySQL,也可以用NoSQL。其 WSGI 工具箱采用 Werkzeug(路由模块) ,模板引擎则使用 Jinja2 。
可以说Flask框架的核心就是Werkzeug和Jinja2
Werkzeug进行请求的路由转发
Jinja2进行界面框架渲染
Python最出名的框架要数Django,此外还有Flask、Tornado等框架。虽然Flask不是最出名的框架,但是Flask应该算是最灵活的框架之一,这也是Flask受到广大开发者喜爱的原因。

补充flask

此时没有开启debug模式,每次修改都需要重启服务器
如何在pycharm中开启debug模式?
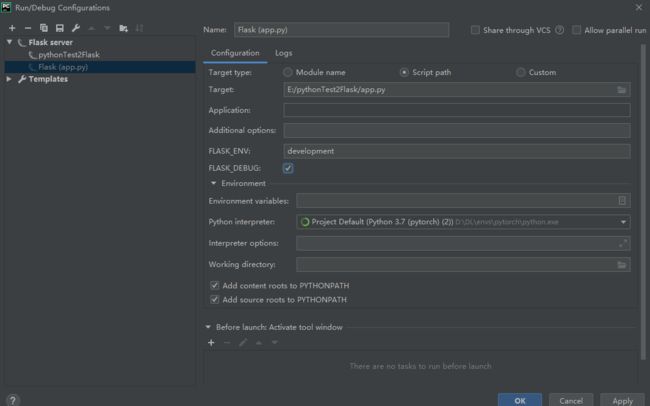
app.py
from flask import Flask, render_template,request #渲染模板
import datetime
app = Flask(__name__)
#解析路由,通过用户访问的路径,匹配响应的函数
# @app.route('/') #匹配/路径 #用户访问方式
# def hello_world():
# #return 'Hello World!'
# return '你好!欢迎光临'
# debug模式开启
@app.route("/index")
def hello():
return "你好"
#通过访问路径,获得用户的字符串参数
@app.route("/user/" ) #拿到指定内容
def welcome(name):
return "你好,%s"%name
#通过访问路径,获得用户的整形参数
@app.route("/user/" ) #此外还有float类型
def welcome2(id):
return "你好,%d 号的会员"%id
#路由路径不能重复,用户通过唯一路径访问特定的函数
#返回给用户渲染后的html网页文件
# @app.route("/")
# def index2():
# return render_template("index.html") #渲染文件
#向页面传递一个变量
@app.route("/")
def index2():
time = datetime.date.today() #普通变量
name = ["小张","小王","小赵"] #列表类型
task = {"任务":"打扫卫生","时间":"3个小时"} #字典类型
return render_template("index.html",var = time, list = name, task=task)
#表单提交
@app.route('/test/register')
def register():
return render_template("test/register.html")
#接收表单提交的路由,需要指定methods为post
@app.route('/result',methods=['POST','GET'])
def result():
if request.method == 'POST':
result = request.form #将表单内容形成一个字典传给result
return render_template("test/result.html",result=result)
if __name__ == '__main__':
app.run()
index.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
今天是{{ var }},欢迎光临。<br/>
今天值班的有:<br/>
{% for data in list %}
<li>{{ data }}li>
{% endfor %}
任务:<br/>
<table border="1">
{% for key,value in task.items() %}
<tr>
<td>{{ key }}td>
<td>{{ value }}td>
tr>
{% endfor %}
table>
body>
html>
register.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<form action="{{ url_for('result') }}" method="post">
<p>姓名:<input type="text" name="姓名">p>
<p>年龄:<input type="text" name="年龄">p>
<p>性别:<input type="text" name="性别">p>
<p>地址:<input type="text" name="地址">p>
<p><input type="submit" value="提交">p>
form>
body>
html>
result.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<form action="{{ url_for('result') }}" method="post">
<p>姓名:<input type="text" name="姓名">p>
<p>年龄:<input type="text" name="年龄">p>
<p>性别:<input type="text" name="性别">p>
<p>地址:<input type="text" name="地址">p>
<p><input type="submit" value="提交">p>
form>
body>
html>
http://www.cssmoban.com/ 网站模板下载
https://www.iconfont.cn/ 阿里的开源的图标库,可以下载任意图标
ECharts应用
https://echarts.apache.org/zh/index.html Eharts 网站
完全可以根据需求来在线定制
补充ECharts
在一个网页中可以有多张图表,但多张图的命名要不同
教程:https://echarts.apache.org/v4/zh/tutorial.html#ECharts%20%E5%9F%BA%E7%A1%80%E6%A6%82%E5%BF%B5%E6%A6%82%E8%A7%88
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<!-- 引入 ECharts 文件 -->
<script src="echarts.min.js"></script>
<title>ECharts</title>
</head>
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
应用时,可以在实例标签下使用可视化工具,直接得到对应代码

然后把左边代码复制到自己html文件中的