使用DGL构建自己的GNN模型
说明:这个系列来自于DGL上面的A Blitz Introduction to DGL。如果看英文习惯的小伙伴还是建议直接看官网文档。
本节结束您能够完成以下任务
- 理解DGL的消息传递API
- 使用GraphSAGE
本节开始前加入你已经掌握了节点分类操作
先导包
import dgl
import torch
import torch.nn as nn
import torch.nn.functional as F消息传递机制(这是GNN中最重要的一个部分),消息传递满足以下式子。基本上都是两个部分组成:①消息的传递 ②消息的汇聚更新。消息传递是有方向的。
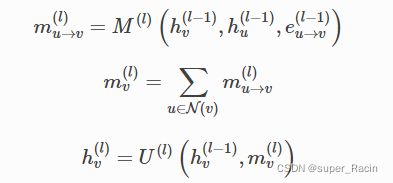
GraphSAGE使用以下式子进行消息传递

DGL已经直接提供了现成可用的GraphSAGE操作,通过dgl.nn.SAGEConv,但是这里方便理解,还是从头写一个SAGEConv模块
class SAGEConv(nn.Module):
def __init__(self,in_feat,out_feat):
super(SAGEConv,self).__init__()
self.linear=nn.Linear(in_feat*2,out_feat)
def forward(self,g,h):
'''
g:graph
h:node feature
'''
with g.local_scope(): #被g.local_scope()包围的代码块操作不会影响到原来图
g.ndata['h']=h
#update_all is a message passing API
#消息传递的“传递、更新”两大操作都是通过在update_all中完成的
g.update_all(message_func=fn.copy_u('h','m'),reduce_func=fn.mean('m','h_N'))
h_N=g.ndata['h_N']
h_total=torch.cat([h,h_N],dim=1)
return self.linear(h_total)说明:
- fn.copy_u('h','m') :将节点的‘h’特征传递给邻居节点,并保存在'm'中
- fn.mean('m','h_N'):使用平均的方法进行信息汇聚,并保存在h_N中
- update_all:触发更新
当定义完SAGEConv后,你就可以多层模型了
class Model(nn.Module):
def __init__(self,in_feat,h_feats,num_classes):
super(Model,self).__init__()
self.conv1=SAGEConv(in_feat,h_feats)
self.conv2=SAGEConv(h_feats,num_classes)
def forward(self,g,in_feat):
h=self.conv1(g,in_feat)
h=F.relu(h)
h=self.conv2(g,h)
return h训练(和前面的训练流程一样)
import dgl.data
dataset=dgl.data.CoraGraphDataset()
g=dataset[0]
def train(g,model):
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)
all_logits=[]
best_val_acc=0
best_test_acc=0
features=g.ndata['feat']
labels=g.ndata['label']
train_mask=g.ndata['train_mask']
val_mask=g.ndata['val_mask']
test_mask=g.ndata['test_mask']
for e in range(100):
logits=model(g,features)
pred=logits.argmax(1)
loss=F.cross_entropy(logits[train_mask],labels[train_mask])
train_acc=(pred[train_mask]==labels[train_mask]).float().mean()
val_acc=(pred[val_mask]==labels[val_mask]).float().mean()
test_acc=(pred[test_mask]==labels[test_mask]).float().mean()
if best_val_acc多种消息汇聚方式(例如下面根据边权重的方式进行消息汇聚),由于Cora数据集没有边权重,所以就用1代替,主要是看一下语法
class WeightedSAGEConv(nn.Module):
def __init__(self,in_feat,out_feat):
super(WeightedSAGEConv,self).__init__()
self.linear=nn.Linear(in_feat*2,out_feat)
def forward(self,g,h,w):
with g.local_scope():
g.ndata['h']=h
g.edata['w']=w
g.update_all(message_func=fn.u_mul_e('h','w','m'),reduce_func=fn.mean('m','h_N'))
h_N=g.ndata['h_N']
h_total=torch.cat([h,h_N],dim=1)
return self.linear(h_total)
class Model(nn.Module):
def __init__(self,in_feats,h_feats,num_classes):
super(Model,self).__init__()
self.conv1=WeightedSAGEConv(in_feats,h_feats)
self.conv2=WeightedSAGEConv(h_feats,num_classes)
def forward(self,g,in_feat):
h=self.conv1(g,in_feat,torch.ones(g.num_edges(),1).to(g.device))
h=F.relu(h)
h=self.conv2(g,h,torch.ones(g.num_edges(),1).to(g.device))
return h
model=Model(g.ndata['feat'].shape[1],16,dataset.num_classes)
train(g,model)DGL同时也允许用户自己定义消息传递函数和消息汇聚函数,灵活多样。
GNN中消息传递占据了很重要的地位,所以能够自己实现一些消息传递函数和汇聚函数,是很重要的。