PyTorch模型导出到ONNX文件示例(LeNet-5)
从PyTorch模型导出到ONNX文件是通过调用PyTorch的torch.onnx.export接口实现。
torch.onnx.export:如果pytorch模型既不是torch.jit.ScriptModule也不是orch.jit.ScriptFunction,它(torch.nn.Module)会run一次pytorch模型,以便将其转换为TorchScript graph被导出(相当于torch.jit.trace,跟踪其执行情况,然后将跟踪的模型导出到onnx文件)。生成的onnx文件包含一个二进制protocol buffer,其中包含你导出的模型的网络结构和参数。
参数说明:
(1).model:要导出的pytorch模型,可以为torch.nn.Module, torch.jit.ScriptModule或torch.jit.ScriptFunction。
(2).args:模型的输入,可以为tuple或torch.Tensor。
(3).f:一个类似文件的对象或一个包含文件名的字符串。A binary protocol buffer will be written to this file。
(4).export_params=True:默认值为True。如果为True,则将导出所有参数。如果要导出未经训练的模型,需将此参数设置为False。如果为True,导出的模型将首先将其所有参数作为参数,其顺序由model.stat_dict().values()指定。
(5).verbose=False:默认值为False。如果为True,则打印正在导出到标准输出的模型的描述。此外,最终的ONNX graph将包含来自导出模型的字段"doc_string",其中提到了"model"的源代码位置。
(6).training=TrainingMode.EVAL:默认值为TrainingMode.EVAL。TrainingMode.EVAL:以推理模式导出模型。TrainingMode.PRESERVE:如果model.training为False,则以推理模式导出模型;如果model.training为True,则以训练模式导出模型。TrainingMode.TRAINING:以训练模式导出模型,禁用可能会干扰训练的优化。
(7).input_names=None:类型为str的列表,默认为空列表。按顺序分配给graph的输入节点的名称。如果不设置的话,会自动分配一些简单的名字,如input.1。ONNX模型的每个输入和输出tensor都有一个名字。
(8).output_names=None:类型为str的列表,默认为空列表。按顺序分配给graph的输出节点的名称。如果不设置的话,会自动分配一些简单的名字或数字,如logits、25。ONNX模型的每个输入和输出tensor都有一个名字。
(9).operator_export_type=None:enum类型,默认为None。None通常表示"`OperatorExportTypes.ONNX",但是,如果PyTorch是用"DPYTORCH_ONNX_CAFFE2_BUNDLE"构建的,则None表示"OperatorExportTypes.ONNX_ATEN_FALLBACK"。OperatorExportTypes.ONNX:将所有操作导出为常规ONNX操作(在默认操作域中(opset domain))。OperatorExportTypes.ONNX_FALLTHROUGH:尝试将所有操作转换为默认操作域中的标准ONNX操作。OperatorExportTypes.ONNX_ATEN:所有的ATen操作(ops)都导出为ATen操作。OperatorExportTypes.ONNX_ATEN_FALLBACK:尝试将每个ATen操作导出为常规ONNX操作。
(10).opset_version=None:int类型,在PyTorch 1.11.0版本中,默认值为9,此值范围必须在[7, 15]范围内。每个PyTorch版本对应的值范围不同。ONNX算子集版本。参考:https://github.com/onnx/onnx/blob/main/docs/Operators.md
(11).do_constant_folding=True:默认为True。应用constant-folding优化。constant-folding将用预先计算的常量节点替换一些具有所有常量输入的操作。
(12).dynamic_axes=None:字典类型,默认为空字典。默认情况下,导出的模型将所有输入和输出tensors的shape设置为与args中给出的完全匹配。指定输入输出tensor的哪些维度是动态的,ONNX默认所有参与运算的tensor都是静态的(tensor的shape不发生改变)。
(13).keep_initializers_as_inputs=None:bool类型,默认为None。如果为True,则导出的graph中所有初始化程序(通常对应于参数)也将作为输入添加到graph。如果为False,则初始化程序不会作为输入添加到graph,并且仅将非参数输入添加为输入。
(14).custom_opsets=None:字典类型,默认为空字典。schema字典:Key(str):opset域名;Value(int):opset版本。
(15).export_modules_as_functions=False:bool类型或set of type of nn.Module,默认为False。将所有nn.Module forward调用导出为ONNX中的本地函数(local function)。或指示要在ONNX中导出为本地函数的特定模块类型。
以下是将LeNet-5.pth导出到LeNet-5.onnx的示例:
1.加载LeNet-5.pth:https://blog.csdn.net/fengbingchun/article/details/125462001
此模型的产生见上面的链接,因为此示例代码中会用到另外一个目录下python脚本中的函数,需导入,代码段如下:
import sys
sys.path.append("..") # 为了导入pytorch目录中的内容
from pytorch.lenet5.test_lenet5_mnist import LeNet5, list_files, get_image_label加载LeNet-5.pth模型的代码段如下:需将model设置为评估模式
def load_pytorch_model(model_name):
model = LeNet5(n_classes=10).to('cpu') # 实例化一个LeNet5网络对象
model.load_state_dict(torch.load(model_name)) # 加载pytorch模型
model.eval() # 将网络设置为评估模式
return model2.导出到onnx文件,并验证此onnx文件的正确性,代码段如下:
def export_model_from_pytorch_to_onnx(pytorch_model, onnx_model_name):
batch_size = 1
# input to the model
x = torch.randn(batch_size, 1, 32, 32)
out = pytorch_model(x)
#print("out:", out)
# export the model
torch.onnx.export(pytorch_model, # model being run
x, # model input (or a tuple for multiple inputs)
onnx_model_name, # where to save the model (can be a file or file-like object)
export_params=True, # store the trained parameter weights inside the model file
opset_version=9, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['input'], # the model's input names
output_names = ['output'], # the model's output names
dynamic_axes={'input' : {0 : 'batch_size'}, # variable length axes
'output' : {0 : 'batch_size'}})
def verify_onnx_model(onnx_model_name):
# model is an in-memory ModelProto
model = onnx.load(onnx_model_name)
#print("the model is:\n{}".format(model))
# check the model
try:
onnx.checker.check_model(model)
except onnx.checker.ValidationError as e:
print(" the model is invalid: %s" % e)
exit(1)
else:
print(" the model is valid")3.准备测试图像,此测试图像也来自于上面的链接:一共10幅,0到9各一幅,如下图所示,注意:训练图像背景色为黑色,而测试图像背景色为白色:

def image_preprocess(image_names, image_name_suffix):
input_data = []
labels = []
for image_name in image_names:
label = get_image_label(image_name, image_name_suffix)
labels.append(label)
img = cv2.imread(image_name, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (32, 32))
# MNIST图像背景为黑色,而测试图像的背景色为白色,识别前需要做转换
img = cv2.bitwise_not(img)
norm_img = cv2.normalize(img, None, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_32F)
norm_img = norm_img.reshape(1, 1, 32, 32).astype('float32')
#print(f"img type: {type(norm_img)}, shape: {norm_img.shape}")
input_data.append(norm_img)
return input_data, labels4.通过ONNX Runtime进行推理,验证LeNet-5.onnx,代码段如下:
def softmax(x):
x = x.reshape(-1)
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def postprocess(result):
return softmax(np.array(result)).tolist()
def inference(model_name, image_names, input_data, labels):
session = onnxruntime.InferenceSession(model_name, None)
# get the name of the first input of the model
input_name = session.get_inputs()[0].name
count = 0
for data in input_data:
raw_result = session.run([], {input_name: data})
res = postprocess(raw_result)
idx = np.argmax(res)
image_name = image_names[count][image_names[count].rfind("/")+1:]
print(f" image name: {image_name}, actual value: {labels[count]}, predict value: {idx}, percentage: {round(res[idx]*100, 4)}%")
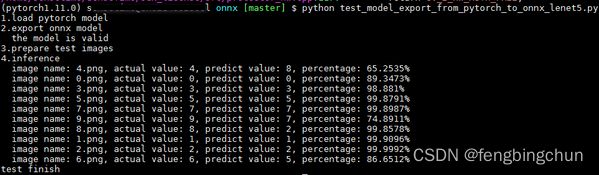
count += 1执行结果如下:与上面链接中的结果一致
GitHub:https://github.com/fengbingchun/PyTorch_Test