Hadoop HDFS 运行原理
一、HDFS 简介
1.HDFS的设计思想及作用
HDFS 是 hadoop 的分布式文件存储系统,它的设计思想为分而治之,就是说将大文件、大批量文件、分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析。在大数据系统中主要为各类分布式的运算框架(如:mapreduce、spark等)提供数据存储服务。
2.HDFS的概念及特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件。其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。重要特性如下:
(1).HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,hadoop1.x 版本中是64M。
(2).HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3).目录结构及文件分块信息(元数据)的管理由namenode节点承担,namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4).文件的各个block的存储管理由datanode节点承担,datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5).HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高
二、HDFS 的工作机制
1.HDFS 概述
(1).HDFS集群分为两大角色:NameNode、DataNode
(2).NameNode负责管理整个文件系统的元数据
(3).DataNode 负责管理用户的文件数据块
(4).文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
(5).每一个文件块可以有多个副本,并存放在不同的datanode上
(6).Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
(7).HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
2.写数据流程
流程概述:
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本.
详细步骤图

详细步骤解析
(1).根据 namenode 通信请求上传文件,namenode检查目标文件及目标文件的父目录是否存在
(2).namenode返回是否可以上传
(3).client 请求第一个block 该传输到哪一个datanode服务器上
(4).namenode应客户端要求返回指定数量的datanode(比如上图中返回node1、node2、node3)
(5).client 请求三台dn中的一台 DataNode1上传数据(本质上是一个RPC调用,建立pipeline,即管道),node1请求会继续调用node1、node3,将整个管道建立完成,逐级返回客户端
(6).client 开始上传第一个block(从本地磁盘读取数据先写入到缓存中,再写入datanode的文件中,同时以数据包packet为单位,传输给别的datanode,node1收到一个packet就会传给node2,node2传给node3,node1每传一个packet就会放入一个应答队列等待应答)
(7).当一个block传输完成之后,client再次请求namenode上传第二个block到服务器
3.读数据流程
流程概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
详细步骤图

详细步骤解析
(1).跟namenode通信查询元数据,找到文件块所在的datanode服务器
(2).挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
(3).datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
(4).客户端以packet为单位接收,先在本地缓存,然后写入目标文件
4.NameNode 工作机制
首先我们知道namenode的职责就是负责客户端的请求及响应、管理元数据,namenode对数据的管理采用了三种存储形式,本别为:内存元数据(NameSystem)、磁盘元数据镜像文件(FsImage)、数据操作日志文件(editslog,可通过日志运算出元数据)
注意:HDFS不适合存储小文件的原因,每个文件都会产生元信息,当小文件多了之后元信息也就多了,对namenode会造成压力。
元数据存储机制介绍
内存:内存中有一份完整的元数据,即当前namenode正在使用的元数据,存储在内存中
磁盘文件:磁盘有一个“准完整”的元数据镜像文件,保存在namenode的工作目录中,作用是为了在namenode宕机后,磁盘文件和数据操作日志合并快速准确的恢复元数据,称为fsimage。
数据操作日志:记录元数据的操作日志,每次更改元数据后,都会追加到操作日志中,主要作用是用来完善fsimage,减少fsimage和内存中元数据的差距,称为editlog。
checkpoint机制分析
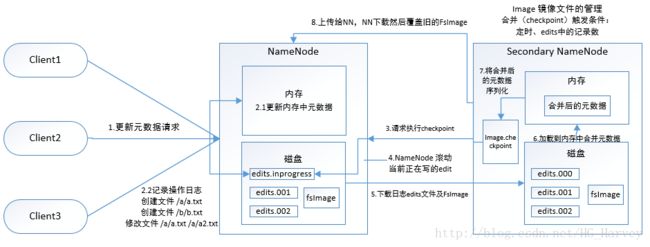
(1). namenode 节点每隔一段时间向 secondary namenode 发送 rpc 请求,请求合并editslog到fsimage
(2). secdondary namenode 收到请求后 从 namenode 中下载 fsimage 和 editlog 到磁盘中(sedondary namenode 下载前,namenode 会对当前正在写的edits进行滚动,这样新的元数据的日志就会追加到新的文件中)
(3). secondary namenode 将磁盘中的fsimage 和 editlog 加载内存中,还原成元数据结构,合并,再生成文件,新文件的文件名为fsimage.checkpoint
(4). namenode 下载合并后的fsimage.checkpoint,将fsimage.checkpoint命名为原来的文件名(这样之后的fsimage 和 内存中的元数据就只差edits.new了)
(5).至此,一个轮回完成,等待下一次checkpoing 触发 secondary namenode 进行工作,一直这样循环操作。
常见问题解答
1.namenode 如果宕机,hdfs是否能够正常提供服务
毫无疑问答案是不可以
2.如果namenode的的硬盘损坏,元数据是否能恢复,如果可以,如何恢复可以?
可以恢复绝大部分的元数据,将secondary namenode中的工作目录中的fsimage.checkpoint 拷贝到namenode的工作目录中,namenode在启动后会自动加载,从而恢复namenode的元数据(因为secondary namenode和namenode的工作目录存储结构完成相同)