基于深度学习的表面缺陷检测方法综述-论文阅读笔记
//2022.3.2日阅读笔记
原文链接:基于深度学习的表面缺陷检测方法综述 (aas.net.cn)
个人对本篇综述内容的大致概括
论文首先介绍了表面缺陷检测中不同场景下的成像方案,主要根据表面颜色或表面反射性质来制定;接着介绍了工业界中存在的缺陷检测挑战(关键问题),例如:缺陷成像和背景差异小、缺陷尺度不一致、缺陷图片中存在大量的噪声等。
接着论文对缺陷检测问题的定义、缺陷检测的定义作了详细的介绍。而后从四个大方向(基于全监督学习,半监督,无监督,其他)展开文章。
在全监督方面,作者分为基于表征学习和基于度量学习的方法。
在基于表征学习中,作者从使用的网络不同分为:分类网络,检测网络,分割网络三个方面进行介绍。在分类网络中,作者介绍了经典的基于CNN的深度学习缺陷检测方法,这包括:直接利用网络进行分类,利用网络进行定位,利用网络作为特征提取然后将提取到的特征输入到分类器中。在检测网络中,作者介绍了两阶段和单阶段模型,并介绍了各自代表骨干网络(如:两阶段的FasterRCNN和单阶段的SSD及YOLO)的在不同工业场景下的应用。在分割网络中,作者介绍了全卷积神经网络(FCN)和Mask RCNN的典型原理和应用。
在基于度量学习中,作者介绍了孪生网络的原理和应用案例。
在无监督方面,作者主要介绍了正常样本学习,其中又分为了:基于图像空间的方法和基于特征空间的方法;
在半监督和弱监督方面,由于本人任务不会涉及到相关技术,所以就没有总结。感兴趣的同学,可以直接看这篇综述的原文。
然后,作者又介绍了目前缺陷检测方面存在的关键问题:1.小样本;2.实时性;并将传统的基于图像的缺陷检测方法和深度学习方法做了一个对比;
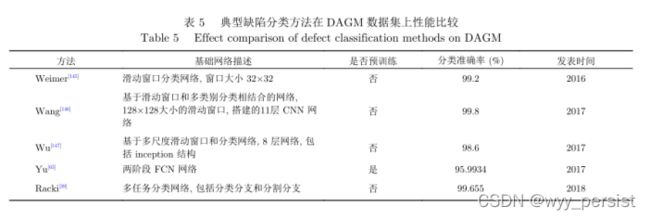
此外,作者又介绍了比较常用缺陷检测相关的数据集,并展示了不同缺陷检测方法在DSGM数据集上的表现对比。
在最后,作者又介绍了表面缺陷检测领域的未来可能发展方向:
- 网络结构设计;
- 网络训练学习(引入类脑等知识指导网络训练);
- 异域联邦学习(对于不同工业场景的数据集进行充分的利用问题)。
目录
个人对本篇综述内容的大致概括
1.论文目的
2.缺陷检测任务的成像方案,工业界中存在的挑战,国内外发展现状介绍
3.论文主要内容
3.1缺陷检测问题的定义
3.2缺陷检测的定义
3.3表面缺陷检测深度学习方法
3.4表征学习(即:经典网络在缺陷检测这一工业领域的应用)
3.4.1分类网络
3.4.2 检测网络
3.4.3 分割网络
3.5 度量学习
3.6 正常样本学习
3.6.1 基于图像空间的方法
3.6.2 基于特征空间的方法
3.7 弱监督和半监督学习方法
3.8 关键问题
3.8.1 小样本
3.8.2 实时性
3.8.3 和传统的基于图像处理的缺陷检测方法对比
3.9 缺陷检测数据集
3.10 总结与展望
1.论文目的
对基于深度学习的表面缺陷检测技术进行总结;从三个不同的方法出发,对典型方法进行分类和对比分析;探讨了缺陷检测中的三个关键问题;介绍常用的缺陷检测数据集;
2.缺陷检测任务的成像方案,工业界中存在的挑战,国内外发展现状介绍
- 一般通用的表面缺陷检测方法往往采用常规图像处理算法或人工设计特征加分类器的方式。利用被检表面或缺陷的不同性质进行成像方案的设计,从而有利显示表面的缺陷;
选择不同成像方案:
- 一种是:根据表面颜色选择成像光源;
- 另外一种是:根据表面反射性质选择成像方案;(明场成像,暗场成像,混和成像)
需要注意的是:期待成像系统完全消除场景等周围环境因素对表面缺陷检测的影响往往是不现实的。
2.工业场景下表面缺陷检测面临的挑战:缺陷成像与背景差异小,对比度低,缺陷尺度变化大且类型多样,缺陷图像中存在大量噪声,缺陷在自然环境下存在大量干扰等;
3.国内外用于缺陷检测的软件:
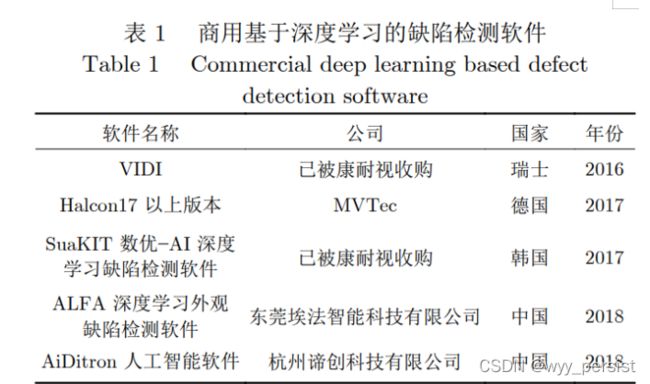
4.基于深度学习的缺陷检测方法研究具有相当的学术研究价值和应用前景:
全球传统工业视觉 及其部件的市场规模在 2025 年将达到 192 亿美元[4] , 其中中国占比约为 30%, 并保持 14% 的年度平均增 长率, 这一领域正在逐步被新一代基于深度学习的 工业视觉技术替代. 同时我国在 《中国制造 2025》 白皮书中提出 “推广采用先进成型和加工方法、在 线检测装置、智能化生产和物流系统及检测设备等, 使重点实物产品的性能稳定性、质量可靠性、环境 适应性、使用寿命等指标达到国际同类产品先进水平”.
3.论文主要内容
- 缺陷检测问题的定义;
- 相关方法的介绍,细分和对比;
- 三个关键问题;
- 工业领域公开的数据集;
- 未来的研究焦点和发展方向;
3.1缺陷检测问题的定义
两种不同的检测手段:
- 有监督方法:利用标记进行训练;
- 无监督方法:使用无缺陷样本进行训练,更关注无缺陷特征;(异常检测)
3.2缺陷检测的定义
分为三个部分:缺陷是什么(分类任务),缺陷在哪里(定位任务),缺陷是多少(分割任务,可以辅助产品进行高一级的质量评估)。
3.3表面缺陷检测深度学习方法
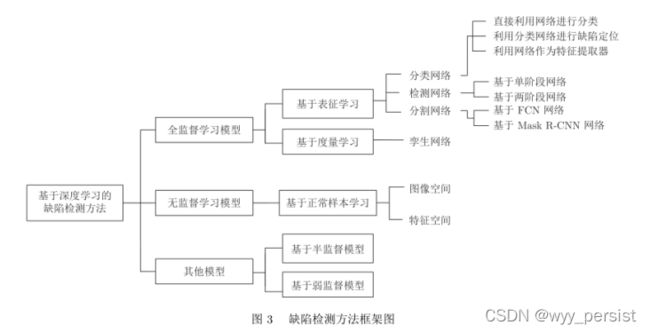
目前大量工作都是全监督学习模型:
3.4表征学习(即:经典网络在缺陷检测这一工业领域的应用)
本质是将计算机视觉中的缺陷检测看作为分类任务;
包括:粗粒度的图像标签分类或区域分类, 以及最精细的像素分类。
3.4.1分类网络
在真实的工业生产中, 检测对象形状、尺寸、纹理、颜色、背景、布局和成像光照的巨大差异使复杂环境下的缺陷分类成为一项艰巨的任务。
使用CNN特征提取的分类部分采用级联的CONV层+Pooling层+FC层+softmax;
常用的网络结构:
AlexNet[5], VGG[6], GoogLeNet[7],ResNet[8], DenseNet[9], SENet[10], ShuffleNet[11], MobileNet[12]等。
或者针对实际问题搭建简易的网络结构, 通过输入一幅测试图像到分类网络中, 网络输出该图像的类别和其类别的置信度。
从分类网络实现任务的差异出发,细分的三个小类:
3.4.1.1 直接利用网络进行分类(最早用的手段)
原图分类:将完整的缺陷图像放入到网络中进行学习训练。
案例分析:
2014年, 奥地利科技研究所[13]最早采集光度立体图像训练 CNN网络来实现轨道表面空洞缺陷分类, 整个网络共包含两个卷积层和两个池化层以及最后一个全连接层, 在钢轨表面数据集上最终达到的错误识别率为1.108%.Convolutional neural networks for steel surface defect detection from photometric stereo images.
Park等[14]设计了一种简易 CNN分类网络, 用于自动检测表面零件上的污垢、划痕、毛刺和磨损等缺陷. 该方法在实验缺陷数据集上的平均检测正确率为 98%, 其检测速度为 5 285样本/min(图像分辨率为 32×32像素). Machine learning- based imaging system for surface defect inspection.
Kyeong等[15]提出了一种卷积神经网络框架对半导体行业的晶圆仓图(Wafer bin map, WBM)中的混合类型缺陷模式进行分类. Classification of mixed-type defect patterns in wafer bin maps using convolutional neural networks.
文献 [16]采用修改的 VGG19网络用于识别 300×300分辨率的太阳能面板图像缺陷, 网络的准确率达到 88.42%, 超过多种手工设计特征 (包括KAZE[17]、SIFT (Scale-invariant feature trans-form)[18]、SURF (Speeded-up robust feature)[19])和支撑向量机 (Support vector machine, SVM)方法的效果.Automatic classification of defective photovol- taic module cells in electroluminescence images.
Liang等[20]提出了一种基于 ShuffleNetV2网络分类复杂背景下的瓶子喷墨码缺陷, 所提出的方法在塑料容器行业的在线喷墨码检测设备上获得了 99.88%的分类正确率.In-line inspection solution for codes on complex backgrounds for the plastic container industry.
直接原图分类的方法可以使用的领域:PCB分类;焊接缺陷,锂电池水泡;
定位ROI后分类(较为常见)
方法:先将ROI区域提取出来,然后输入网络进行分类。
案例分析:
Shang等[24]提出了一种两阶段的铁轨缺陷识别算法, 首先利用 Canny算子和直线拟合算法在整个原始图像上对铁轨区域进行裁剪. 然后将裁剪的图像放入 Inception V3网络中提取特征以进行轨道图像分类. Detection of rail surface defects based on CNN image recognition and classification.
文献 [25]中通过级联的目标检测网络对高铁接触网螺栓区域进行获取, 然后将裁剪的螺栓图像输入到 CNN网络中进行缺陷分类. Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network.
Li等[26]首先利用基于局部二值模式 (Local binary pattern,LBP)特征的级联目标检测器实现扫描隧道显微镜成像材料待检测区域定位, 然后采用 CNN模型来获取表面缺陷的具体类型.Automated defect analysis in electron microscopic images.
多类别分类
当待分类的缺陷类型超过两类时, 常规的缺陷分类网络与原图分类方法一样, 即网络的输出节点为缺陷类型的数目+1 (包括正常类别). 但多类别分类方法往往先采用一个基础网络进行缺陷与正常样本二分类,然后在同一个网络上共享特征提取部分, 修改或者增加缺陷类别的分类分支.通过该方式相当于给后续的多目标缺陷分类网络准备了一个预训练权重参数,这个权重参数通过正常样本与缺陷样本之间二分类训练得到.
案例分析:
Xie等[27]首先训练第 1个 ND (normal-defective)-CNN模型进行二分类 (正常图像和所有其他缺陷图像), 缓解了数据不平衡的问题.在训练好 ND-CNN模型后, 将输出向量更改为 6维向量来训练 ID (interdefect)-CNN模型, 以使其适合于多类缺陷标签问题. 该模型在 ND-CNN权重的基础上使用缺陷图像进行微调, 从而减少了样本量需求并节省了训练时间. Automatic detection and classification of sewer defects via hierarchical deep learning.
Nagata等[28]提出了一种 seeNet (Net with SVMs to classify sample im-ages)网络, 该网络有两个分类分支, 第 1个二分类分支用来分类正常样本和 NG样本, 网络的模型采用 AlexNet进行特征提取, 其分类器采用 SVM; 第2个分支用于 7类别的缺陷分类. 多类别分类采用这种二分支结构, 可以充分利用缺陷样本与正常样本数目不均衡的特点, 挖掘两者特征之间的差异.Fusion method of convolutional neural network and support vector machine for high accuracy anomaly detection.
3.4.1.2 利用网络进行缺陷定位
一般认为, 分类网络只能完成图像标签级别的分类, 实际上结合不同的技巧和方式, 分类网络也可以实现缺陷的定位与逐像素的分类。
根据采用的手段不同, 可进一步将其分为滑动窗口、热力图(heatmap)和多任务学习网络三种形式.
滑动窗口(是最简单和直观的实现缺陷粗略定位的方法)
一般工业表面缺陷检测处理的图像分辨率较大, 通过小尺寸的窗口在原始图像上进行冗余滑动, 将滑动窗口中的图像输入到分类网络中进行缺陷识别.最后将所有的滑动窗口进行连接, 即可获得缺陷粗定位的结果.
案例分析:
Deep learning-based crack damage detection using convolutional neural networks2017年, Cha等[29]最早采用基于滑动窗口的 CNN分类网络实现了裂纹表面缺陷定位,两种滑动窗口冗余路径结合实现图像全覆盖, 如图 4所示, 图 4(a)为滑动窗口路径示意图, 图 4(b)为裂纹定位的结果图.
文献 [30−32]采用相同的方法应用于金属表面裂纹、路面表面裂纹和城市建筑物表面缺陷定位.
热力图
是一种反映图像中各区域重要性程度的图像, 颜色越深代表越重要。在缺陷检测领域, 热力图中颜色越深的区域代表其属于缺陷的概率越大
案例分析:
2018年, Ren等[33]采用图像分块和特征迁移方式获取每个分块所对应属于缺陷的置信度, 并将其转换为热力图. 在热力图基础上运用 Otsu法[34]和图割算法进一步得到准
确的缺陷轮廓区域. A generic deep-learning-based approach for automated surface inspection.
基于灰度直方图的阈值选择方法。 threshold selection method from gray-level histograms.
在计算机视觉领域, 常采用CAM (Class activation mapping)[35]和 Grad-CAM[36]方法获得热力图, 其本质上是通过加权特征图, 确定网络模型是通过哪些像素作为依据来判断输入图片所属的类别. Learning deep features for discriminative localization. + Grad-CAM: Visual explanations from deep networks via gradient-based localization.
Lin等[37]采用 CAM获取热力图, 并利用 Otsu二值化方法分割热力图, 实现 LED灯图像中划痕或线缺陷的定位.Automated defect inspection of LED chip using deep convolutional neural network.
Zhou等[38]采用 grad-CAM方法获取热力图, 并采用 Otsu算法分割得到表面缺陷的准确区域. A generic automated surface defect detection based on a bilinear model.
多任务学习网络
单纯的分类网络若不加入其他技巧, 一般只能实现图像级别的分类. 因此, 为了精细定位缺陷位置, 往往设计的网络会加上额外的分割分支, 两个分支共享特征提取的骨架 (backbone)结果, 这样网络一般有分类和分割两个输出, 构成多任务学习网络. 它兼顾两个网络特点, 对于分割网络分支, 图像中每个像素都能被当作训练样本来训练网络. 因此, 多任务学习网络不仅利用分割分支输出缺陷具体的分割结果, 而且可以大大减少分类网络对样本的需求.
案例分析:
Racki等[39]设计了一个紧凑的一体化多任务 CNN结构用于表面缺陷的分割和分类. 所提出的网络在各种表面纹理缺陷数据集 DAGM 2007上取得了最好的效果.
A compact convolutional neural network for textured surface anomaly detection.
Tabernik等[40]也提出了一个融合分类和分割分支的多任务缺陷检测网络, 整个网络只用了 50幅 1 408×512分辨率的缺陷图像进行训练, 取得的缺陷准确识别率超过了商业 CognexViDi Suite软件.Segmentation-based deep-learning approach for surface-defect detection.
3.4.1.3 利用网络作为特征提取器
在早期基于深度学习的缺陷分类方法中, 不少文献利用 CNN特征提取的强大功能, 先将图像输入到预训练网络中获取图像表征特征, 再将获取的特征输入到常规的机器学习分类器 (例如 SVM等)中进行分类.
案例分析:
Zhao等[41]采用 CNN对电力航拍绝缘子图像块进行特征抽取, 将特征输入到SVM中进行二分类, 同时作者还比较了从不同全连接层抽取特征分类效果的差异. Multi-patch deep features for power line insulator status classification from aerial images.
Malekzadeh等[42]采用由 VGG-DNN中的 fc6层的输出作为特征, 输入到 SVM中实现飞机表面缺陷分类, 缺陷分类精度达到 96%以上.Aircraft fuselage defect detection using deep neural networks.

3.4.2 检测网络
目标定位是计算机视觉领域中最基本的任务之一, 同时它也是与传统意义上缺陷检测最接近的任务, 其目的是获得目标精准的位置和类别信息.
基于深度学习的缺陷检测网络从结构上划分:
两阶段:FasterRCNN
一阶段:YOLO SSD
两者差别:
两者主要差异在于两阶段网络需要首先生成可能包含缺陷的候选框 (Proposal), 然后再进一步进行目标检测. 一阶段网络则直接利用网络中提取的特征来预测缺陷的位置和类别.
3.4.2.1 两阶段缺陷检测网络架构
两阶段检测网络 (Faster R-CNN)的基本流程是首先通过 Backbone网络获取输入图像的特征图,利用区域生成网络 (Region proposal network,RPN)计算锚框 (anchor box)置信度, 获取 Pro-posal区域. 然后对 Proposal区域的特征图进行ROIpooling后输入网络, 通过对初步检测结果进行精细调整, 最终得到缺陷的定位和类别结果。
改进的切入点:因此,针对缺陷检测的特点, 常用方法往往针对 Backbone结构或其特征图、锚框比例、ROIpooling和损失函数等方面进行改进。
案例分析:
2018年, Cha等[46]最早将Faster R-CNN直接应用在桥梁表面缺陷定位, 其 Backbone网络被替换为 ZF-net, 在包含 2 366幅 500×375像素大小的 5类桥梁建筑数据集中, 其 mAP
(Mean average precision)值达到 87.8%. Autonomous structural visual inspection using region-based deeplearning for detecting multiple damage types.
Zhong等[47]提出了一种基于三阶段 PVANET++ 的部件缺陷定位系统, 用于高速铁路的悬链支撑装置—开口销的松动和缺失检测, PVANET++ 是一个改进版的 Faster R-CNN, 相比于原版 Faster R-CNN, 在最高层特征图进行 Proposal提取, 其改进点在于将低层两组特征图进行降采样与高层特征图上采样后联结形成新的超特征图用于 Proposal提取. 另外,作者采用了 54个不同比例的锚框, 而不是原始的9个锚框. A CNN-based defect inspection method for catenary split pins in high-speed railway.
2020年, Tao等[48]设计了一个两阶段的Faster R-CNN网络用于无人机电力巡检中绝缘子缺陷定位, 第 1阶段用于自然场景下的绝缘子区域定位; 第 2阶段实现绝缘子区域中的缺陷定位.Detection of power line insulator defects using aerial images analyzed with convolutional neural networks.
Xue等[49]基于改进的 Faster R-CNN实现盾构隧道中衬砌缺陷的检测, 其 Backbone采用改进的 Inception全卷积网络得到特征图, 同时增加两个锚框比例, 使用位置敏感 ROIpooling替代传统的 ROI Pooling, 所提出模型在单幅图像 48 ms的测试时间速度下, 实现了检测精度超过 95%. A fast detection method via region-based fully convolutional neural networks for shield tunnel lining defects.
Ding等[50]提出了一种针对 PCB表面缺陷检测网络 (TDD (Ting defect detection)-Net), 该方法通过使用 K均值聚类设计合理的锚框大小; 其次引入多尺度金字塔网络 (Feature pyramid networks, FPN)到 Faster R-CNN中, 加强了来自底层结构信息的融合, 使得网络适应微小的缺陷检测. 最后, 考虑到小数据集和样本不平衡的特点, 在训练阶段采用了在线困难样本挖掘 (Online hard example mining, OHEM)技术. 该方法在 PCB缺陷数据集上达到了 98.90%的 mAP. TDD-net: A tiny defect detection network for printed circuit boards.
He等[51]提出了基于 Faster R-CNN的带钢表面缺陷检测网络, 该网络的改进在于将 Backbone中多级特征图组合为一个多尺度特征图. 在缺陷检测数据集 NEU-DET上, 提出的方法在采用ResNet-50的 Backbone下实现了 82.3%的 mAP.An end-to-end steel surface defect detection approach via fusing multiple hierarchical features.
其他利用FasterRCNN网络架构场景:隧道[52]、液晶面板偏振片表面[53]、热成像绝缘子缺陷[54]、铝型材表面[55]-Surface defect classification and detection on extruded aluminum profiles using convolutional neural networks. 和轮胎轮毂[56]等缺陷检测领域.
3.4.2.2 单阶段的缺陷检测网络架构
单阶段检测网络分为 SSD和 YOLO两种, 两者都是利用整幅图作为网络的输入, 直接在输出层回归边界框 (Bounding box)的位置及其所属的类别.
SSD的特点在于引入了特征金字塔检测方式,从不同尺度的特征图中预测目标位置与类别. 它使用 6个不同特征图检测不同尺度的目标, 一般底层特征图用于预测小目标, 高层特征图预测大目标.
Chen等[25]采用改进的 SSD网络进行接触网支撑装置上的紧固件缺陷区域定位, 其主要改进部分在于采用不同层的特征图进行目标检测.Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network.
Li等[57]提出了一种基于 MobileNet-SSD的灌装生产线容器密封表面缺陷检测方法, 通过 MobileNet优化了 SSD的 Backbone结构, 以简化检测模型参数. Research on a surface defect detection algorithm based on MobileNet-SSD.
Liu等[58]同样采用基于 MobileNet-SSD网络来定位高铁接触网支撑组部件, 相比于原始 SSD网络, 其改进点在于: 1) 采用 MobileNet 为 Backbone; 2) 只使用4个不同的特征图来加速目标检测. 在测试的数据集上, 其目标达到 25 帧/s的检测速度和 94.3%的mAP. A high-precision positioning approach for catenary support components with multiscale difference.
Zhang等[59]采用最新 YOLOv3版本应用于桥梁表面缺陷定位, 相比于原始 YOLOv3网络, 引入了预训练权重、批再规范化 (Batch renormalization)和 Focal loss, 进一步提高了缺陷检测率。Concrete bridge surface damage detection using a single-stage detector。
总结:追求精度使用二阶段网络,追求速度使用单阶段网络;
3.4.3 分割网络
分割网络介绍:分割网络将表面缺陷检测任务转化为缺陷与正常区域的语义分割甚至实例分割问题, 它不但能精细分割出缺陷区域, 而且可以获取缺陷的位置、类别以及相应的几何属性 (包括长度、宽度、面积、轮廓、中心等)。
按照分割功能的区别分为:全卷积神经网络,Mask RCNN方法。
3.4.3.1 FCN方法
FCN方法介绍:
FCN 是图像语义分割的基础, 目前几乎所有的语义分割模型都是基于 FCN. FCN首先利用卷积操作对输入图像进行特征提取和编码, 然后再通过反卷积操作或上采样将特征图逐渐恢复到输入图像尺寸大小。
依据 FCN网络结构的差异, 其缺陷分割方法可以进一步细分为常规 FCN、Unet [ 6 2 ]和
SegNet[63]三种方法.
常规FCN方法
案例分析:
Wang等[64]提出一种基于 FCN的轮胎 X射线图像缺陷分割方法, 相比于原始 FCN方法, 该方法通过融合多尺度采样层的特征图来细化分割轮胎图像中的缺陷。Tire defect detection using fully convolutional network.
Yu等[65]提出了一个基于 FCN的两阶段表面缺陷分割模型, 第 1阶段采用一个轻量级的 FCN快速获取粗略缺陷区域, 然后, 第 1阶段的输出作为第2阶段 FCN的输入用于细化缺陷分割结果, 该方法在公共数据集 DAGM2007上取得了 95.9934%的×平均像素准确率。Fully convolutional networks for surface defect inspection in industrial environment.
Dung等[66]采用基于 VGG16编码器的 FCN网络对混凝土表面裂缝进行分割, 其平均像素准确率达到 90%。
Unet方法
Unet不仅是一种经典的 FCN结构, 同时也是典型的编码器—解码器 (Encoder-decoder)结构. 它的特点在于引入了跳层连接, 将编码阶段的特征图与解码阶段的特征图进行融合, 有利于分割细节的恢复。
案例分析:
Huang等[67]提出了一个 MCuePush Unet的模型用于磁瓦表面缺陷的显著性检测. 其 Unet网络的输入为 MCue模块生成三通道图像, 包括一个显著性图像和两个原始图像。Surface defect saliency of magnetic tile.
Li等[68]提出了一种基于改进 Unet网络的混凝土结构表面缺陷分割方法. 在编码器采用 Dense Block模块, 同时跳层连接没有采用原始的 Concat操作, 而是逐像素求和. 该方法
在包含 2 750幅图像 (504 376像素) 4种缺陷的混凝土结构数据库上取得了 91.59%的平均像素准确率和 84.53%的平均交并比 (Intersection over union, IoU)。Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network.
SegNet方法
它也是一种经典的编码器—解码器结构. 其特点在于解码器中的上采样操作利用了编码器中最大池化操作的索引。
它也是一种经典的编码器—解码器结构. 其特点在于解码器中的上采样操作利用了编码器中最大池化操作的索引。
Roberts等 [ 7 1 ]设计了一种基于SegNet的网络, 用于扫描隧道显微镜成像下材料晶体缺陷的语义分割. 在少量高质量的钢缺陷图像上三种缺陷的像素分类正确率为: 位错为 91.60±1.77%, 沉淀物为 93.39±1.00%, 空隙为 98.85±0.56%。 Deep learning for semantic segmentation of defects in advanced STEM images of steels.
Zou等[72]在 SegNet的编码器—解码器体系结构上构建 DeepCrack网络, 用于地面裂纹检测.在该模型中, 将分层卷积阶段学习的多尺度深度卷积特征融合在一起, 以捕获精细的裂纹结构. Deep-Crack在三个具有挑战性的数据集上获得了平均87%以上的 F值.
目前, 基于深度学习的分割网络还在不断地提出, 例如, LinkNet[73]、DeepLabv3[74]、PSPNet[75]等.很多最新模型中的模块, 例如空洞卷积[76−77]和金字塔 Pooling[78]也被添加到 FCN框架中, 广泛应用于各种场景的缺陷分割。
GAN在缺陷检测领域的应用:
GAN:由生成器和判别器模型构成. 在结合 GAN的缺陷分割方法中, 生成器往往直接采用 FCN网络, 判别器通过分类模型来区分生成器的结果和 Groundtruth,通过生成器和判别器的不断博弈, 让生成器的输出结果逐渐接近 Groundtruth. 结合 GAN的分割方法已经用于在手机盖板玻璃信号孔缺陷分割[80]和道路裂纹缺陷分割[81]中.
3.4.3.2 Mask-RCNN方法
Mask R-CNN是目前最常用的图像实例分割方法之一, 可以看作是一种基于检测和分割网络相结合的多任务学习方法. 当多个同类型缺陷存在粘连或重叠时, 实例分割能将单个缺陷进行分离并进一步统计缺陷数目, 然而语义分割往往将多个同类型缺陷当作整体进行处理. 目前大部分文献都是直接将 Mask R-CNN框架应用于缺陷分割, 例如路面缺陷分割[82]、工业制造缺陷[83]、螺栓紧固件缺陷[84]和皮革表面缺陷[85]。
相比分类和检测网络方法, 分割方法在缺陷信息获取上有其优势. 但与检测网络一样, 需要大量的标注数据, 其标注信息是逐像素, 因此往往需花费大量的标注精力和成本.
3.5 度量学习
度量学习是使用深度学习直接学习输入的相似性度量. 在缺陷分类任务中, 往往采用孪生网络(Siamese network)进行度量学习. 不同于表征学习输入单幅图像转化为分类任务, 孪生网络的输入通常为两幅或多幅成对图像, 通过网络学习出输入图片的相似度, 判断其是否属于同一类. 孪生网络损失函数的核心思想是让相似的输入距离尽可能小,不同类别的输入距离尽可能大。
孪生网络的实现:一般原始孪生网络的输入是两幅成对的图像,网络的 “连体”是通过共享权值来实现的。
Kim等[86]设计了一个基于 CNN结构的孪生网络对钢表面缺陷图像进行分类, 首先将两幅图像输入到共享权值的 CNN中完成特征提取, 然后利用基于相似度函数的对比损失计算两个特征之间的差异程度. 在NEU钢表面缺陷数据集[51]上, 该方法只通过 5幅和 10幅少量样本图像进行网络学习, 在 9种缺陷类别上网络的分类准确度分别为 85.1%和 86.5%。Classification of steel surface defect using convolutional neural network with few images.
Wu等[87]提出了一种基于孪生网络的相似度度量方法来分类纽扣缺陷. 网络设计了新的损失函数用于自动特征提取和样本的相似性度量, 所提出的方法在包括凹痕、裂纹、污点、孔洞、凹凸不平等多种缺陷的纽扣数据集上进行了评估, 达到的分类精度为98%。
Liu等[88]基于改进的孪生网络对大型紧固件缺陷进行同时定位和缺陷分类. 其孪生网络后接两个分支: 第 1个分支利用对比损失来实现紧固件定位; 第 2个分支采用 softmax损失对紧固件缺陷进行分类. 在测试的数据集上, 紧固件定位的平均检测率达到 99.36%, 紧固件分类的平均检测率达到92.69%。
Tang等[90]提出了一个基于深度学习模型的 PCB缺陷检测模型, 模型的前端将无缺陷的正常样本和有缺陷的图像对输入到孪生网络后进行特征差分, 将差分结果采用群组金字塔合并模块进行缺陷定位. 在DeepPCB数据集上, 该方法以 62 帧/s达到 98.6%的 mAP。
Liu等[91]将孪生网络输出的特征图与其他子网络输出的结果进行特征融合来提高缺陷目标的显著性。
度量学习目前的发展现状:
度量学习可以近似看作为学习样本在特征空间进行聚类; 表征学习可以近似看作为学习样本在特征空间的分界面. 相比于表征学习, 度量学习的方法应用在表面缺陷定位中不太多, 目前大部分都是应用在缺陷分类任务中. 在缺陷定位方面, 输入孪生网络的图像对需要具有统一的内容形式, 要求比较严格, 现阶段还无法适应复杂的工业环境。
3.6 正常样本学习
目前, 最常用于表面缺陷检测的无监督学习模型是基于正常样本学习的方法. 由于只需要正常无缺陷样本进行网络训练, 该方法也常称为 One-class learning. 正常样本学习的网络只接受正常 (无缺陷)样本进行训练, 使得其具备强大的正常样本分布的重建和判别能力. 因此, 当网络输入的样本存在缺陷时, 往往会产生与正常样本不同的结果. 相比于有监督学习模型, 它能够检测到偏离预期的模式或没有见过的模式, 这些模式都可以称为缺陷或者异常。
分为:基于图像空间和基于特征空间两种。
常采用的模型:GAN和AE自编码器;
3.6.1 基于图像空间的方法
基于图像空间的方法是在图像空间上对缺陷进行检测. 因此, 该方法不仅能实现图像级别的分类和识别, 也可以获取到缺陷的具体位置. 该方法常用的手段主要有以下两种.
3.6.1.1 利用网络实现样本重建与补全
原理解释:其原理类似去噪编码器, 当输入任意样本图像到网络中, 都可以得到其重建后对应的正常 (无缺陷)样本, 因此,网络可以看作具备自动修复或者补全缺陷区域的能力. 用输入图像分别减去这些重建或修复图像可以获得残差图像, 这些残差图像也称为重建误差. 它能作为判断待检测样本是否异常的指标. 当重建误差过大时, 可以认为输入图像存在缺陷, 差异过大的区域即为缺陷区域. 当重建误差很小时, 即认为输入图像是正常样本.
案例分析:
Mei等[92]通过使用卷积自编码器网络在不同的高斯金字塔等级上重建图像子
块, 并合成来自这些不同分辨率通道的重建结果,其网络的重建误差采用均方误差 (mean-square error, MSE)损失. 该方法在多个数据集上取得了相比传统图像处理方法好的效果。
Haselmann等[93]设计了一个基于全卷积的自动编码器网络, 基于正样本图像补全和重建的误差实现装饰性塑料零件表面缺陷检测。
Kang等[94]设计了一个深度去噪编码器,基于其重建误差来检测绝缘子图像中的缺陷, 其重建损失采用 L2损失。
Youkachen等[95]使用卷积自动编码器 (Convolutional autoencoder, CAE)用于图像重建, 通过锐化处理重建误差获取最终的热轧带钢表面缺陷分割结果, 其重建误差采用 MSE。
Zhao等[96]利用 GAN和 CAE实现表面缺陷图像的重建, 该方法将输入图像和重建图像输入到 LBP算法处理后再做差。
Bergmann等[97]首次将传统图像处理中的结构相似度 (Structural similarity,SSIM)指标作为重建损失, 引入到基于自动编码器的图像重建中, 实验结果表明相比于传统 L2损失, SSIM损失能大幅提高表面缺陷检测的效果。
Yang等[98]提出了一种基于无监督多尺度特征聚类的全卷积自动编码器 (Multi-scale feature-clustering-based fully convolutional autoencoder, MS-FCAE)方法,该方法利用处于不同比例等级的多个 FCAE子网来重建若干纹理背景图像. 为了最大程度地提高效率和编码特征图的判别能力, 每个 FCAE子网采用全卷积神经网络和特征聚类方法, 所提出的 MS-FCAE方法在多个纹理表面检测数据集上进行了评估, 缺陷检测精度达到 92.0%.
3.6.1.2 利用网路实现异常区域分类
这类网络通常采用 GAN的判别器. 该方法原理是训练生成对抗网络 GAN以生成类似于正常表面图像的伪图像,这意味着训练好的 GAN可以在潜在特征空间中很好地学习正常样本图像. 因此, GAN的判别器可以自然地用作分类器, 用于分类缺陷和正常样本.
案例分析:
Zhai等[99]采用多尺度融合策略融合 GAN鉴别器的三个卷积层的响应, 然后利用 Otsu方法在融合特征响应图上进一步分割出缺陷位置. 该方法与文献 [33]的原理类似, 但是利用了正常样本进行训练,且其网络模型是 GAN的判别器。
Hu等[100]提出了一种基于深度卷积生成对抗网络 (Deep convolutional GAN, DCGAN) 的自动检测织物缺陷的新型无监督方法. 该模型包括两个部分: 第 1部分利用模型中 GAN的判别器生成一个缺陷分布似然图, 其中每个像素值都表示该位置出现缺陷的概率;第 2部分通过引入编码器到标准 DCGAN, 实现重检测图像的重建. 当从原始图像中减去重建图像时,可以创建残差图以突出显示潜在的缺陷区域. 联合残差图和似然图以形成增强的融合图. 在融合图上采用阈值分割算法进一步获取准确的缺陷位置, 该方法在各种真实纺织物样品上进行了评估和验证。
3.6.2 基于特征空间的方法
解释:基于特征空间的方法是在特征空间中, 通过正常样本与缺陷样本特征分布之间的差异来进行缺陷检测. 特征之间的差异也称为异常分数, 当异常分数高于某个值时, 即可认为出现缺陷。
案例分析:
2017年,Schlegl等[101]最早提出了深度卷积生成对抗网络AnoGAN, 实现检测图像从图像空间到潜在空间的映射, 其异常分数由图像空间中的差异和 GAN网络中判别器最后一层特征图之间的差异来计算。
Lai等[102]基于上述映射方法, 在潜在空间中直接采用 Fréchet距离来实现缺陷与正常样本的区分, 在太阳能面板数据集上取得了 93.75%的分类正确率。
Soukup等[103]采用变分自编码器 (Variational auto-encoder, VAE)网络在潜在空间中实现缺陷检测。
Liu等 [ 1 0 4 ]设计了一个基于 GAN和单类分类器(One-class classifier)的表面缺陷分类模型, GAN中生成器 G采用编码解码器, 其编码得到隐空间的特征输入到 SVM分类器中进行缺陷分类, 提出的方法在钢材表面多缺陷数据集上获得的平均分类精度为 94%。
2019年, Schlegl等 [ 1 0 5 ]针对之前的AnoGAN工作提出了改进 f-AnoGAN, 其异常分数
由引入编码器模块实现的图像样本重建损失和GAN网络中判别器最后一层特征图之间的差异来计算。
Akcay等[106]提出了一种 GANomaly用于图像异常检测, 该模型的创新点在于引入了编码解码和再编码模块. 其异常分数由三个部分组成: 图像样本重建差异和 GAN网络中判别器最后一层特征图之间的差异, 以及编码器隐空间的特征与再编码后的特征之间的差异。
虽然文献 [101, 105−106]应用对象不是表面缺陷, 但是其方法完全适用于表面缺陷检测. 传统上认为基于特征空间的方法往往只能实现图像级别的分类或识别, 无法获取像素级别的缺陷位置, 实际上, 通过 AE和 GAN模块也能实现与图像空间检测方法类似的缺陷精确定位。
对于正常样本方法的评价:
综上, 目前基于正常样本学习方法常用于简单统一的纹理表面缺陷检测, 在复杂的工业检测环境下, 相比于监督学习的方法, 其检测效果还不太理想。
3.7 弱监督和半监督学习方法
使用较少,不采用。
3.8 关键问题
3.8.1 小样本
解决方法:
- 数据增强;
- 网络预训练和迁移学习:
2018年, Ren等[33]最早将迁移学习应用于表面缺陷检测, 其预训练模型采用 ImageNet预训练模型。
Yang等[123]、Zhang等[124]、Badmos等[125]和 Sun等 [ 1 2 6 ]-Surface defects detection
based on adaptive multiscale image collection and convolutional neural networks. 都采用迁移学习方法分别应用于液晶面板Mura缺陷、PCB板缺陷、锂电池电极缺陷和金属零件表面缺陷检测。
Kim等[127]在 DAGM缺陷数据集上对比了基于微调 (Fine-tuning)的迁移学习和从头开始训练网络的效果, 证明基于迁移学习方法的性能优于从头开始训练网络的性能。
- 合理的网络结构设计;
- 采用无监督与半监督模型方法;
3.8.2 实时性
基于深度学习的缺陷检测方法在工业应用中包括三个主要环节: 数据标注、模型训练与模型推断.在实际工业应用中的实时性更关注模型推断这一环节. 目前大多数缺陷检测方法都集中在分类或识别的准确性上, 而很少关注模型推断的效率。
作者的观点:有不少方法用于加速模型, 例如模型权重量化[128]和模型剪枝[129]等. 在文献 [130]的工作中, 提出了一种端到端的手机屏幕表面缺陷检测模型. 为了提高模型计
算过程的效率以满足实际的工业需求, 在建立低精度版本网络而又不损失准确性的前提下,对提出的模型中的权重执行权重量化, 其缺陷分析的效率提高了 16%. 在传统的基于图像处理的表面缺陷检测方法中, FPGA并行加速架构常用于加速图像处理算子. Pan等[131]将 FPGA加速傅里叶重构算子用于纹理表面缺陷分割, 其 FPGA并行加速架构比同类服务器 CPU快三倍, 从而将整个 8.5代 LCD面板的扫描检测时间缩短至 8.5 s. 文献 [132]开发了一种实时热轧扁钢双表面检测系统, 提出的算法在FPGA上并行实现, 其并行图像处理技术将轧制速度从 5 m/s提升为 20 m/s. 虽然现有深度学习模型使用 GPU作为通用计算单元, 但随着技术发展, 相信 FPGA会成为一个具有吸引力的替代方案。
3.8.3 和传统的基于图像处理的缺陷检测方法对比

3.9 缺陷检测数据集

3.10 总结与展望
需要解决的问题:
- 网络结构设计;
- 网络训练学习;(作者观点:如何利用类脑计算和仿人视觉认知模型来指导缺陷检测)
- 异域数据联邦学习:单个表面缺陷检测数据集往往都很少, 虽然小样本问题可以通过第 3节介绍的方法缓解相关问题, 但是实际上不同工业行业和领域中, 真实工业表面缺陷数据是非常多的, 一些缺陷种类也是共同的, 例如划痕广泛存在于金属、液晶屏幕、太阳能电池板、玻璃等等一系列材质表面. 同时, 人类也会将统一类型的缺陷进行标记, 并不会因为检测领域的不同而产生差异. 但是由于涉及隐私敏感, 不同检测领域之间数据并没有有效结合和利用. 如何利用不同工业领域的缺陷数据集来进行网络学习, 也是表面缺陷检测的一种重要研究方向. 因此, 基于异域数据的联邦学习将会成为一个趋势, 它能够打破不同应用场景之间的壁垒, 充分学习不同领域之间数据来提升网络性能。