TextCNN 模型完全解读及 Keras 实现

1、初识TextCNN
最近在做寿命预测问题的研究中,拿到的数据为一维的数据,传统的数据预处理方法主要有PCA、LDA、LLE等,考虑到应用CNN进行特征的提取,从而提高预测的精度。但之前了解到的CNN多应用于图像处理,其输入数据为二维或者多维的数据,因此进一步了解学习应用于文本分类的TextCNN。下一篇文章会通过期刊论文来介绍几篇CNN的具体应用实例,主要介绍模型的网络结构。
TextCNN模型是Yoon Kim在2014年 《Convolutional Neural Networks for Sentence Classification》中提出的,利用卷积神经网络(CNN)来对处理文本分类问题(NLP)。该算法利用多个不同大小的kernel来提取句子中的关键信息,从而能更加高效的提取重要特征,实现较好的分类效果。
2、TextCNN结构
该模型的结构如下图:(下图引用于原文)

TextCNN的详细过程见下:(以一句话为例)
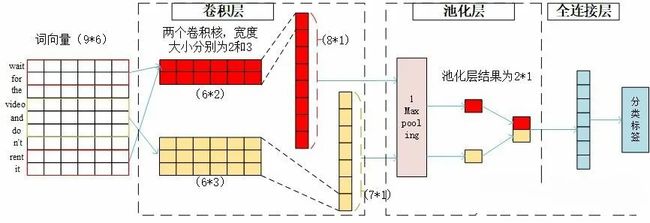
(1)输入:自然语言输入为一句话,例如:wait for the video and don't rent it.
(2)数据预处理:首先将一句话拆分为多个词,例如将该句话分为9个词语,分别为:wait, for, the, video, and, do, n't rent, it,接着将词语转换为数字,代表该词在词典中的词索引。
(3)嵌入层:通过word2vec或者GLOV 等embedding 方式将每个词成映射到一个低维空间中,本质上是特征提取器,在指定维度中编码语义特征。例如用长度为6的一维向量来表示每个词语(即词向量的维度为6),wait可以表示为[1,0,0,0,0,0,0],以此类推,这句话就可以用9*6的二维向量表示。
(4)卷积层:与图像处理的卷积核不同的是,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。TextCNN卷积核的宽度和词向量的维度一致,高度可以自行设置。以将卷积核的大小设置为[2,3]为例,由于设置了2个卷积核,所以将会得到两个向量,得到的向量大小分别为T1:81和T2:71,向量大小计算过程分别为(9-2-1)=8,(9-3-1)=7,即(词的长度-卷积核大小-1)。
(5)池化层:通过不同高度的卷积核卷积之后,输出的向量维度不同,采用1-Max-pooling将每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征。池化完成后还需要将每个值拼接起来,得到池化层最终的特征向量,因此该句话的池化结果就为2*1。
(6)平坦层和全连接层:与CNN模型一样,先对输出池化层输出进行平坦化,再输入全连接层。为了防止过拟合,在输出层之前加上dropout防止过拟合,输出结果就为预测的文本种类。
3、模型实现
(1)数据预处理:TextCNN进行文本分类,原始数据为语句和对应的标签,数据预处理的流程为先将各句子进行分词,接着将每个词转换为正整数用来代表词的编号,最后利用多删少补的原则将每句话设置为等长的词语,得到测试集和训练集的数据。
import pandas as pd
import numpy as np
import jieba
import keras
from keras.layers.merge import concatenate
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers.embeddings import Embedding
from keras.layers import Conv1D, MaxPooling1D, Flatten, Dropout, Dense, Input
from keras.models import Model
from sklearn.model_selection import train_test_split
from sklearn import metrics
#数据预处理
def data_process(path, max_len=50): #path为句子的存储路径,max_len为句子的固定长度
dataset = pd.read_csv(path, sep='\t', names=[ 'text', 'label']).astype(str)
cw = lambda x: list(jieba.cut(x)) # 定义分词函数
dataset['words'] = dataset['text'].apply(cw) # 将句子进行分词
tokenizer = Tokenizer() # 创建一个Tokenizer对象,将一个词转换为正整数
tokenizer.fit_on_texts(dataset['words']) #将词编号,词频越大,编号越小
vocab = tokenizer.word_index # 得到每个词的编号
x_train, x_test, y_train, y_test = train_test_split(dataset['words'], dataset['label'], test_size=0.1) #划分数据集
x_train_word_ids = tokenizer.texts_to_sequences(x_train) #将测试集列表中每个词转换为数字
x_test_word_ids = tokenizer.texts_to_sequences(x_test) #将训练集列表中每个词转换为数字
x_train_padded_seqs = pad_sequences(x_train_word_ids, maxlen=max_len) # 将每个句子设置为等长,每句默认为50
x_test_padded_seqs = pad_sequences(x_test_word_ids, maxlen=max_len) #将超过固定值的部分截掉,不足的在最前面用0填充
return x_train_padded_seqs,y_train,x_test_padded_seqs,y_test,vocab
(2)网络结构的搭建:TextCNN网络结构主要有嵌入层-卷积层-池化层-dropout-全连接层,将网络的基础操作(损失函数、模型训练、准确率的定义)和网络结构的搭建结合到一个函数中,该部分代码参考:https://github.com/Asia-Lee
# 构建TextCNN模型
def TextCNN_model_1(x_train, y_train, x_test, y_test):
main_input = Input(shape=(50,), dtype='float64')
# 嵌入层(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 卷积层和池化层,设置卷积核大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat) #在池化层到全连接层之前可以加上dropout防止过拟合
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train, one_hot_labels, batch_size=800, epochs=2)
result = model.predict(x_test) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
y_predict = list(map(str, result_labels))
print('准确率', metrics.accuracy_score(y_test, y_predict))
(3)主函数:查看测试精度
if __name__ == '__main__':
path = 'data_train.csv'
x_train, y_train, x_test, y_test, vocab = data_process(path)
TextCNN_model_1(x_train, y_train, x_test, y_test)
4、模型总结
TextCNN处理NLP,输入为一整句话,所以卷积核的宽度与词向量的维度一致,这样用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文。
TextCNN的结构优化有两个方向,一个是词向量的构造,另一个是网络参数和超参数调优。
TextCNN和CNN的最大不同在于输入数据的维度,图像是二维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征抽取;自然语言是一维数据, 虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义。
参考文献:
《Convolutional Neural Networks for Sentence Classification》:
https://arxiv.org/abs/1408.5882
Keras中文文档:
https://keras.io/zh/layers/embeddings/
代码参考:
https://github.com/Asia-Lee
作者:xianyang94,zhihu.com/people/xianyang94

推荐阅读:
用 Python 进行系统聚类分析
用 Python 对数据进行相关性分析
用 Python 的两种方法进行方差分析
如何在 matplotlib 中加注释和内嵌图
如何用一行代码让 gevent 爬虫提速 100%
▼点击成为社区会员 喜欢就点个在看吧