基于tensorflow2+textCNN的中文垃圾邮件分类
目录
一、邮件数据集
二、文本分类
三、Text-CNN
四、搭建Text-CNN模型
五、实验结果
一、邮件数据集
本文进行文本分类任务的中文邮件数据来源于由国际文本检索会议提供一个公开的垃圾邮件语料库,点我下载。分为英文数据集(trec06p)和中文数据集(trec06c),其中所含的邮件均来源于真实邮件,并且还保留了邮件的原有格式(包括发送方、接收方、时间日期等等)和邮件中文内容。第二个链接即是中文文本的邮件数据集,点击链接即可下载。下载的压缩文件夹中,一个文件代表一封邮件,通过标签“spam”、“ham”进行区别是否垃圾邮件。“spam”表示是垃圾邮件,有4万多条。“ham”表示是正常邮件,有2万多条。
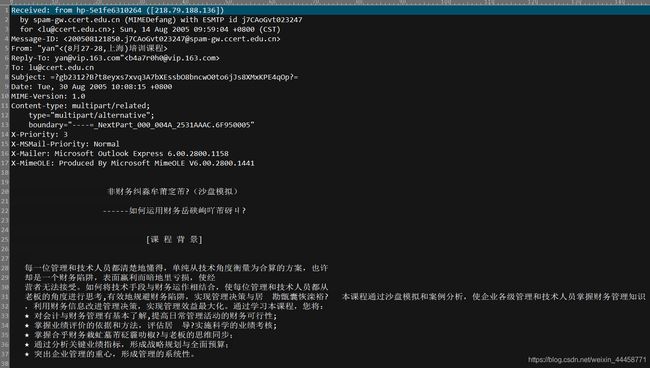 垃圾邮件示例
垃圾邮件示例
 正常邮件示例
正常邮件示例
可以看到,垃圾邮件的内容一般是广告、推销类的有害信息,那么如何从这一大堆邮件中自动识别出垃圾邮件呢?
这实际上是一个文本分类任务,即将邮件文本分为垃圾邮件和正常邮件,简单地二分类。
二、文本分类
在互联网时代下,网络上积累了各式各样海量的数据及信息,不仅包括文本,还有声音、图像等等。文本的种类也是各式各样,可以是新闻、报告、邮件、电子书、网页内容等等,关于如何有效管理这些信息并快速实现情感分析或是文本分类等技术,这些年来出现了很多算法模型,实现效果也越来越佳。文本分类技术一直是自然语言处理领域中研究的热点之一,其应用领域非常广泛,例如本文要做的对垃圾邮件的判定,可以自动将邮件进行二分类,识别出垃圾营销的邮件。
文本自动分类技术相关的研究始于上世纪50年代末,那时候的文本分类主要是基于知识工程,用人工定义相应规则的方法来对文本进行分类,举个简单的例子:从一本笔记上分类出语数英各科的笔记内容,基于生活经验可以试着这样判断:带有公式的内容是数学知识,而用带有字母书写的是英语的内容,其余的就是语文知识了。
显然这种方法十分耗费时间和精力,并且需要对文本涉及领域有一定的了解,可迁移性较差,准确率也很低。分类的质量严重依赖于人工所制定的规则的好与坏,而知识工程最大的缺陷之处在于:不能简单移植到其他领域,所以完全没有推广价值。例如,一个针对教育领域构建的分类系统,如果要将它移植用在银行、保险等领域,其中对教育领域制定的规则就完全不能适应新的领域,需要推翻并重新制定规则。
到了上世纪90年代,当统计学习、机器学习方法不断发展,文本分类问题有了新的解决思路,即人工特征工程与浅层分类相结合,所以此问题就拆分为特征工程和分类器两个部分。首先通过在已经分类好的数据集上进行训练,从而建立判别规则或是分类器,即可对计算机没有“见过”的文本内容也就是测试集自动分类,最终得到输入样本的类别。其分类准确度比得上专家手工分类,且其学习不需要人工干预,有很好的可迁移性和稳定性,在这之后被广泛应用。但是这些方法仍然有着不可忽视的缺陷:需要人工进行功能设计,十分耗时。
对于较为传统的文本分类方法,其文本表示通常采用词袋模型或是向量空间模型。词袋模型是指,使每个词独立存在,没有与其他词之间的联系,所以会丢失部分语义信息。而且一旦词库量庞大,很可能会导致维度爆炸。向量空间模型利用特征项来降维,使词向量变得稠密,词与词之间联系相对紧密。
而自2010年以来,文本分类模型已逐渐从浅层学习模型变为深层学习模型,CNN、RNN、注意力机制被应用在文本分类中。与上世纪普遍流行的浅层学习模型相比,这些深层学习模型要更加便捷,无需人工设定规则和功能。
 文本分类一般流程
文本分类一般流程
与英文相比,中文的文本分类存在不同之处:
(1)、由于语言的差异,分词的思路不一样。中文文本分类需要从文本中切分出词汇,而英文通过空格和标点即可区分词汇。中文文本分类一般使用分词工具jieba,而英文分词常用NTLK,即Natural Language Toolkit,是自然语言处理工具包。
(2)、停用词不一样。停用词是文本中一些普遍使用的词语,对文档分析作用不大,在文档分析之前需要将这些词去掉。对中文文本来说,类似“他”、“是”、“之一”、“的”这样的词汇都会被去除,而英文需要消除“an”、“in”、“the”等。可以用分词工具提供的停用词,也可以自己构建一个停用词库并导入到程序中。
(3)、对于英文文本还需要多一步词根还原的操作。如writed和writing都应该还原成write。而中文词汇不需要进行此类操作。
不过中英文文本分类任务大致上的流程是一样的,一般是文本预处理、特征提取、构建分类模型并训练、评估模型等步骤。
文本预处理:大多数情况下,在文本内容中存在很多对分类任务无用甚至会妨碍的东西,例如特殊字符、停用词等。就要依次来对文本内容进行清洗,刨除不需要的部分。
特征提取:在分好词之后,不同的词汇对分类任务的贡献也不一样,例如,一看到“发票”、“五折”、“借贷”就能够判断大概率是垃圾营销内容,而看到“联系”、“发布”等词汇则无法做出判断。那么如何衡量不同词汇对分类任务的贡献程度呢?比如可以通过单词出现的次数,次数越多就表示越重要,但对于“你好”、“回信”这类常用词依然无法做出判断。所以合适的方法是计算词语的TF-IDF 值,词语的TF-IDF值可以描述一个词语对文档的重要性,TF-IDF值越大,则表示该词汇越重要。
建模:在提取特征之后,就可以按一定比例将数据划分为训练集、测试集,并使用训练集来对分类器进行训练。
评估:可以利用准确率、召回率等一些指标来衡量分类器的好坏与否。
三、Text-CNN
目前基于深度学习的文本分类模型已经成为了主流,例如CNN、RNN等深度学习网络以及它们的变体。从2014年Kim提出了Text-CNN模型起,深度学习在文本分类任务之中得到了广泛的关注和应用。CNN在这之前较多被用于图像处理领域,并取得了很好的效果。因为CNN能够很好地捕捉局部相关性,并且使用相同的滤波器,权值共享使CNN较于全连接神经网络很大程度地减少了参数。Text-CNN与传统的CNN网络相比较,在网络结构上没有任何变化,并且由于使用一维卷积即可,较于CNN网络甚至更简单了。
下图展现了2个Channel的Text-CNN文本分类过程:
 以一个实例句子为例的两通道模型结构
以一个实例句子为例的两通道模型结构
从图中可以看出,Text-CNN分为四层:input layer输入层,convolutional layer卷积层,max-pooling layer池化层和最后输出的softmax layer。
与传统CNN相比,该模型做了一些小改变。由于Text-CNN处理的是文本数据而非图像数据,所以输入层使用word embedding来做文本表示,生成的是二维矩阵,第一个维度是句子的分词数量,第二个维度是词的向量表征即Word Embedding维数。在图像处理中,CNN使用的卷积核是二维的,但是Text-CNN的输入是词矩阵,比如说5000个词,每个词用64维的词向量表示,那么就得到5000×64的矩阵。而卷积核只在一个维度上滑动,而另一个维度与词向量的维度一致,即都是64,可以这样理解:每一次卷积核进行卷积的区域都是一个完整的词,令得词作为文本的最小粒度来进行分类工作,不会将词的一部分来进行卷积。
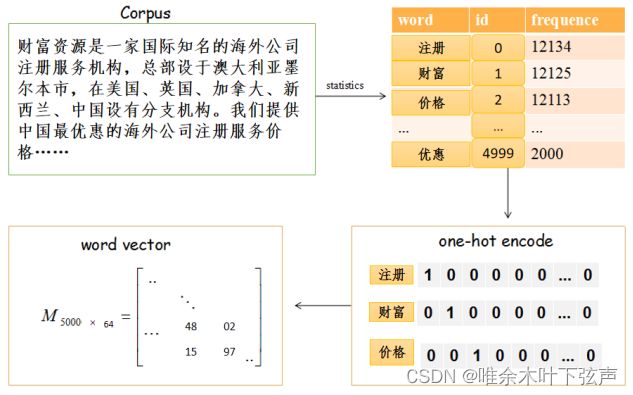 词嵌入(One-hot方式)
词嵌入(One-hot方式)
在卷积层对输入层的文本数据进行“提取特征”,可以自主选择卷积核的尺寸和数量。卷积核可以视作滑动的窗口,其尺寸大小就是每次卷积处理的词的数量,通常选择3、4、5,步长通常为1。在语言模型上可以理解为N-gram,即语义正常或者说像我们人说的话的n个词相互之间依赖出现的条件概率就越大。
池化层是对卷积层中提取的特征数据进行过滤,一般在卷积层之后都会接一个池化层。它主要有两个作用:一个是降维,例如池化区域尺寸为4,则特征向量的维数经过池化后会缩小4倍。另一个是可以将任意长度的输入数据和任意尺寸的卷积核映射成同一个维度的输出,就可以便于softmax层对其进行分类。而池化方式有max-pooling和average-pooling,大多数分类算法模型都是使用max-pooling比较多,虽然二者都对数据作下采样,但是max-pooling能够更好地选取突出特征,提供非线性。而average-pooling更注重于对整体的特征信息进行一层下采样,在降低纬度的同时,使信息完整地传递到下一层。
虽然Pooling层对整体的精度提升的效果帮助并不大,但是可以有效地减少整个网络的参数的数量,因为池化层不需要参数。其次,可以控制过拟合、提高网络模型的性能,所以池化层通常被连接在卷积层之后,尤为重要。
最后的softmax层将经过若干层卷积、池化处理的特征数据进行分类,其输出表示着各个类别的概率分布。
四、搭建Text-CNN模型
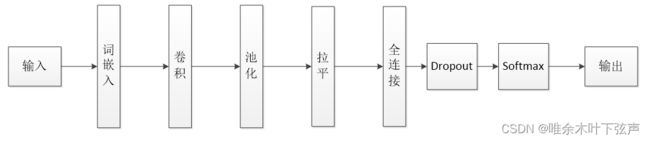 搭建模型
搭建模型
上图是Text-CNN模型结构。该模型先将文本数据输入到Embedding层,提取特征,降维映射成词向量。随后,经过一维卷积和最大池化操作,再将其输出结果“压平”,即把多维的输入一维化。随后输出到全连接层,并经过Dropout层,防止模型过拟合,最后通过softmax层进行分类输出标签值。
解压数据集压缩包:
!tar xvf ../input/hamspam/trec06c.tgz代码:
#导入程序运行必需的库
from sklearn.model_selection import train_test_split
import pickle
from collections import Counter
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras import layers,optimizers
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix, accuracy_score
import numpy as np
import pandas as pd
from sklearn.metrics import precision_recall_fscore_support
import time
import matplotlib.pyplot as plt
import re
import os
#-------------------数据预处理----------------------
# 根据路径打开文件 并提取每个邮件中的文本
def getMailTest(mailPath):
mail = open(mailPath, "r", encoding="gb2312", errors='ignore')
mailTextList = [text for text in mail]
# 去除邮件头
XindexList = [mailTextList.index(i) for i in mailTextList if re.match("[a-zA-Z0-9]", i)]
textBegin = max(XindexList) + 1
text = ''.join(mailTextList[textBegin:])
# 去空格分隔符及一些特殊字符
text = re.sub('\s+','',re.sub("\u3000","", re.sub("\n", "",text)))
return text
# 通过index文件获取所有文件路径及标签值
def getPaths_Labels():
targets = open("./trec06c/full/index", "r", encoding="gb2312", errors='ignore')
targetList = [t for t in targets]
newTargetList = [target.split() for target in targetList if len(target.split()) == 2]
pathList = [path[1].replace('..', './trec06c') for path in newTargetList]
label_list = [label[0] for label in newTargetList]
return pathList, label_list
# 获取所有文本
def getAllText(pathList):
content_list = [getMailTest(filePath) for filePath in pathList]
return content_list
# 0 为垃圾邮件 1 为正常邮件
def transform_label(label_list):
i = 0
list = []
for x in label_list:
f=(lambda x:0 if x == "spam" else 1)
list.append(f(x))
i=i+1
return list
#-------------------文本分类----------------------
class TextClassification():
#为超参数赋值
def config(self):
self.vocab_size = 5000 #词库大小
self.seq_length = 600 #允许句子最大长度
self.embedding_dim = 64 #词向量维度
self.num_filters = 32 #卷积核数目
self.kernel_size = 5 #卷积核尺寸
self.hidden_dim = 32 #全连接层神经元
self.dropout_keep_prob = 0.5 #dropout保留比例
self.learning_rate = 1e-3 #学习率
self.batch_size = 128 # 每批训练大小
self.num_iteration = 5000 #迭代次数
self.print_per_batch = self.num_iteration / 100 #每迭代5000/100=50次打印一次
def __init__(self,content_list,label_list):
self.config()
train_X, test_X, train_y, test_y = train_test_split(content_list, label_list)
self.train_content_list = train_X
self.train_label_list = train_y
self.test_content_list = test_X
self.test_label_list = test_y
self.content_list = self.train_content_list + self.test_content_list
self.autoGetNumClasses()
def autoGetNumClasses(self):
label_list = self.train_label_list + self.test_label_list
self.num_classes = np.unique(label_list).shape[0]
#对字符串中的字符做统计计数,返回出现次数排名前vocabulary_size,即前5000
def getVocabularyList(self, content_list, vocabulary_size):
allContent_str = ''.join(content_list)
counter = Counter(allContent_str)
vocabulary_list = [k[0] for k in counter.most_common(vocabulary_size)]
return ['PAD'] + vocabulary_list
def prepareData(self):
vocabulary_list = self.getVocabularyList(self.content_list, self.vocab_size-1)
if len(vocabulary_list) < self.vocab_size:
self.vocab_size = len(vocabulary_list)
contentLength_list = [len(k) for k in self.train_content_list]
if max(contentLength_list) < self.seq_length:
self.seq_length = max(contentLength_list)
self.word2id_dict = dict([(b, a) for a, b in enumerate(vocabulary_list)])
self.labelEncoder = LabelEncoder()
self.labelEncoder.fit(self.train_label_list)
#文本内容转换为id
def content2idList(self, content):
return [self.word2id_dict[word] for word in content if word in self.word2id_dict]
#文本内容列表content_list转换为特征矩阵X
def content2X(self, content_list):
idlist_list = [self.content2idList(content) for content in content_list]
X = keras.preprocessing.sequence.pad_sequences(idlist_list, self.seq_length)
return X
#文本标签列表label_list转换为预测目标值Y,
def label2Y(self, label_list):
y = self.labelEncoder.transform(label_list)
Y = keras.utils.to_categorical(y, self.num_classes)
return Y
#搭建卷积神经网络模型
def buildModel(self):
self.model = tf.keras.Sequential([
layers.Embedding(input_dim=self.vocab_size,output_dim=self.embedding_dim,input_length=self.seq_length),
layers.Conv1D(self.num_filters,self.kernel_size, padding='same', activation=tf.nn.relu, name="a2"),
layers.MaxPool1D(4, padding='same',name="a3"),
layers.Flatten(name="a4"),
layers.Dense(self.hidden_dim,name="a5",activation=tf.nn.relu),
layers.Dropout(rate=self.dropout_keep_prob,name="Dense_Dropout"),
layers.Dense(self.num_classes,activation=tf.nn.selu)])
#训练模型;模型总共迭代训练num_iteration次,即5000次
def trainModel(self):
self.prepareData()
self.buildModel()
trainloss_list = []
trainaccuracy_list = []
optimizer = optimizers.Adam(learning_rate=0.01)
train_X = self.content2X(self.train_content_list)
train_Y = self.label2Y(self.train_label_list)
startTime = time.time()
len_Y=len(train_Y)
for i in range(self.num_iteration):
selected_index = np.random.randint(0, len_Y, size=self.batch_size)
batch_X = tf.cast(train_X[selected_index],dtype=tf.float32)
batch_Y = tf.cast(train_Y[selected_index],dtype=tf.float32)
with tf.GradientTape() as gdt:
pred_proba = self.model(batch_X, training=True)
predictions = tf.argmax(pred_proba, axis=1)
y_true=tf.argmax(batch_Y, axis=1)
tloss_ = self.loss_function(batch_Y, pred_proba)
taccu_ = accuracy_score(y_true, predictions)
trainloss_list.append(tloss_)
trainaccuracy_list.append(taccu_)
#计算梯度值
grads = gdt.gradient(tloss_, self.model.trainable_variables)
#更新权值
optimizer.apply_gradients(zip(grads, self.model.trainable_variables))
if i % self.print_per_batch == 0:
used_time = time.time() - startTime
print('epochs %d ==>loss is : %.5f, accuracy is : %.4f, time: %.2f'%(i,tloss_, taccu_,used_time))
if tloss_ < self.learning_rate :
break
if i == self.num_iteration -1 :
used_time = time.time() - startTime
print('epochs %d ==>loss is : %.5f, accuracy is : %.4f, time: %.2f'%(i,tloss_, taccu_,used_time))
plt.figure(figsize=(26, 6))
plt.subplot(1,2,1)
plt.plot(trainloss_list)
plt.subplot(1,2,2)
plt.plot(trainaccuracy_list)
#定义损失函数
def loss_function(self,labels, pred_proba):
loss = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=pred_proba)
return tf.reduce_mean(loss)
#定义准确率函数
def compute_accuracy(self,labels, pred_proba):
predictions = tf.argmax(pred_proba, axis=1)
return accuracy_score(labels, predictions)
#定义预测函数
def predict(self, content_list):
if type(content_list) == str:
content_list = [content_list]
batch_X = self.content2X(content_list)
predict_y = tf.nn.softmax(self.model(tf.cast(batch_X,dtype=tf.float32)))
predict_y=tf.argmax(predict_y, 1)
predict_label_list = self.labelEncoder.inverse_transform(predict_y)
return predict_label_list
#定义predictAll,分批预测
def predictAll(self):
predict_label_list = []
batch_size = 100
for i in range(0, len(self.test_content_list), batch_size):
content_list = self.test_content_list[i: i + batch_size]
predict_label = self.predict(content_list)
predict_label_list.extend(predict_label)
return predict_label_list
#打印混淆矩阵
def printConfusionMatrix(self):
predict_label_list = self.predictAll()
df = pd.DataFrame(confusion_matrix(self.test_label_list, predict_label_list),
columns=self.labelEncoder.classes_,
index=self.labelEncoder.classes_)
print('\n Confusion Matrix:')
print(df)
#打印评价指标
def printReportTable(self):
predict_label_list = self.predictAll()
reportTable = self.eval_model(self.test_label_list,
predict_label_list,
self.labelEncoder.classes_)
print('\n Report Table:')
print(reportTable)
def eval_model(self, y_true, y_pred, labels):
p, r, f1, s = precision_recall_fscore_support(y_true, y_pred)
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision': p,
u'Recall': r,
u'F1-score': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [tot_p],
u'Recall': [tot_r],
u'F1-score': [tot_f1],
u'Support': [tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1-score', 'Support']]
#run
pathList, label_list = getPaths_Labels()
content_list = getAllText(pathList)
label_list = transform_label(label_list)
model = TextClassification(content_list, label_list)
model.trainModel() #训练模型
model.printConfusionMatrix() #打印混淆矩阵
model.printReportTable() #打印评价指标五、实验结果
 使用GPU运行
使用GPU运行
| ham |
spam |
|
| ham |
5074 |
296 |
| spam |
51 |
10734 |
| Label |
Precision |
Recall |
F1-score |
Support |
| spam |
0.973164 |
0.995271 |
0.984094 |
10785 |
| ham |
0.990049 |
0.944879 |
0.966937 |
5370 |
| all |
0.978777 |
0.978521 |
0.978390 |
16155 |
 loss
loss
本次使用Text-CNN模型进行垃圾邮件分类,评估指标F1score为0.978左右,总体来说这个分类模型很优秀,分类准确率也在0.978左右。而且模型不算复杂,可以在很短的时间内完成训练,用CPU整个跑一遍差不多10分钟。我是在kaggle notebook用GPU跑的,总用时75s。
参考:
基于tensorflow+CNN的垃圾邮件文本分类 - 简书