YOLOv5应用轻量级通用上采样算子CARAFE
《CARAFE: Content-Aware ReAssembly of FEatures》
CARAFE源码地址:https: //github.com/open-mmlab/mmdetection.
在之前的博文中我介绍过多种常规的上采样方式,比如最近邻 / 双线性 / 双立方 / 三线性 / 转置卷积等方式,其应用场景和特点各有不同,详细请看我这篇博文
今天来给大家介绍一个2019年ICCV上提出的一个轻量级通用上采样算子CARAFE

上图是CARAFE 的整体框架。 CARAFE 由两个关键组件组成,即内核预测模块和内容感知重组模块。在该图中,大小为 C × H × W C × H × W C×H×W的特征图被上采样了 σ ( = 2 ) σ(= 2) σ(=2)倍。
CARAFE 作为内容感知内核的重组运算符。它由两个步骤组成。第一步是根据每个目标位置的内容预测一个重组核,第二步是用预测的核对特征进行重组。给定大小为 C × H × W C × H × W C×H×W 的特征图 X X X 和上采样率 σ σ σ(假设 σ σ σ 是整数),CARAFE 将生成大小为 C × σ H × σ W C × σH × σW C×σH×σW 的新特征图 X ′ X' X′。对于输出 X ′ X' X′ 的任意目标位置 l ′ = ( i ′ , j ′ ) l' = (i', j') l′=(i′,j′),在输入 X X X 处都有对应的源位置 l = ( i , j ) l = (i, j) l=(i,j),其中 i = [ i ′ / σ ] i = [i'/σ] i=[i′/σ] , j = [ j ′ / σ ] j = [j'/ σ] j=[j′/σ]。这里我们将 N ( X l , k ) N (X_l, k) N(Xl,k) 表示为以位置 l 为中心的 X X X 的 k × k k × k k×k 子区域,即 X l X_l Xl 的邻居。在第一步中,核预测模块 ψ ψ ψ 根据 X l X_l Xl 的邻居预测每个位置 l ′ l' l′ 的位置核 W l ′ W_{l'} Wl′,如方程式所示。
(1)重组步骤公式化为方程式。
(2)其中 φ φ φ 是内容感知重组模块,将 X l X_l Xl的邻居与内核 W l ′ W_{l'} Wl′进行重组:
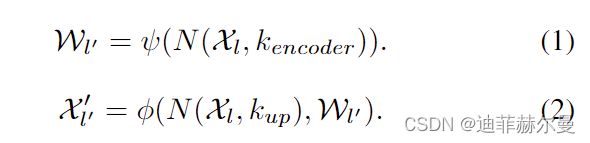
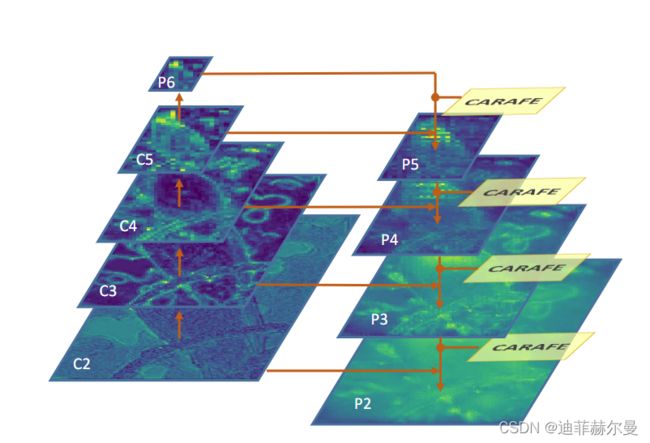
带有 CARAFE 的 FPN 架构。 CARAFE 在自上而下的路径中将特征图上采样 2 倍。通过无缝替换最近邻插值将其集成到 FPN 中。
![]()
YOLOv5更换CARAFE方式:
第一步;将如下代码添加到common.py中
import torch.nn.functional as F
class CARAFE(nn.Module):
#CARAFE: Content-Aware ReAssembly of FEatures https://arxiv.org/pdf/1905.02188.pdf
def __init__(self, c1, c2, kernel_size=3, up_factor=2):
super(CARAFE, self).__init__()
self.kernel_size = kernel_size
self.up_factor = up_factor
self.down = nn.Conv2d(c1, c1 // 4, 1)
self.encoder = nn.Conv2d(c1 // 4, self.up_factor ** 2 * self.kernel_size ** 2,
self.kernel_size, 1, self.kernel_size // 2)
self.out = nn.Conv2d(c1, c2, 1)
def forward(self, x):
N, C, H, W = x.size()
# N,C,H,W -> N,C,delta*H,delta*W
# kernel prediction module
kernel_tensor = self.down(x) # (N, Cm, H, W)
kernel_tensor = self.encoder(kernel_tensor) # (N, S^2 * Kup^2, H, W)
kernel_tensor = F.pixel_shuffle(kernel_tensor, self.up_factor) # (N, S^2 * Kup^2, H, W)->(N, Kup^2, S*H, S*W)
kernel_tensor = F.softmax(kernel_tensor, dim=1) # (N, Kup^2, S*H, S*W)
kernel_tensor = kernel_tensor.unfold(2, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W*S, S)
kernel_tensor = kernel_tensor.unfold(3, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W, S, S)
kernel_tensor = kernel_tensor.reshape(N, self.kernel_size ** 2, H, W, self.up_factor ** 2) # (N, Kup^2, H, W, S^2)
kernel_tensor = kernel_tensor.permute(0, 2, 3, 1, 4) # (N, H, W, Kup^2, S^2)
# content-aware reassembly module
# tensor.unfold: dim, size, step
x = F.pad(x, pad=(self.kernel_size // 2, self.kernel_size // 2,
self.kernel_size // 2, self.kernel_size // 2),
mode='constant', value=0) # (N, C, H+Kup//2+Kup//2, W+Kup//2+Kup//2)
x = x.unfold(2, self.kernel_size, step=1) # (N, C, H, W+Kup//2+Kup//2, Kup)
x = x.unfold(3, self.kernel_size, step=1) # (N, C, H, W, Kup, Kup)
x = x.reshape(N, C, H, W, -1) # (N, C, H, W, Kup^2)
x = x.permute(0, 2, 3, 1, 4) # (N, H, W, C, Kup^2)
out_tensor = torch.matmul(x, kernel_tensor) # (N, H, W, C, S^2)
out_tensor = out_tensor.reshape(N, H, W, -1)
out_tensor = out_tensor.permute(0, 3, 1, 2)
out_tensor = F.pixel_shuffle(out_tensor, self.up_factor)
out_tensor = self.out(out_tensor)
#print("up shape:",out_tensor.shape)
return out_tensor
第二步;把CARAFE写入yolo.py中
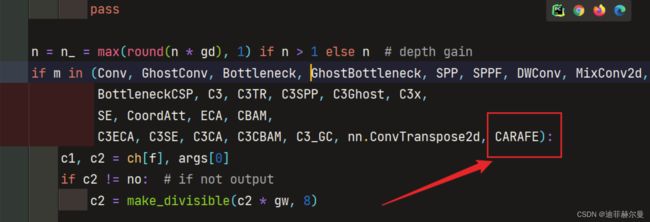
第三步;修改配置文件,以yolov5.yaml为例
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]],
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, CARAFE, [512,3,2]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, CARAFE, [256,3,2]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
本人更多Yolov5(v6.1)实战内容导航
1.手把手带你调参Yolo v5 (v6.1)(一)强烈推荐
2.手把手带你调参Yolo v5 (v6.1)(二)
3.如何快速使用自己的数据集训练Yolov5模型
4.手把手带你Yolov5 (v6.1)添加注意力机制(一)(并附上30多种顶会Attention原理图)
5.手把手带你Yolov5 (v6.1)添加注意力机制(二)(在C3模块中加入注意力机制)
6.Yolov5如何更换激活函数?
7.Yolov5 (v6.1)数据增强方式解析
8.Yolov5更换上采样方式( 最近邻 / 双线性 / 双立方 / 三线性 / 转置卷积)
9.Yolov5如何更换EIOU / alpha IOU / SIoU?
10.Yolov5更换主干网络之《旷视轻量化卷积神经网络ShuffleNetv2》
11.持续更新中
有问题欢迎大家指正,如果感觉有帮助的话请点赞支持下
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。