Pytorch-YOLOv3-DAGM2007缺陷检测
前言
最近一直在研究深度学习去实现缺陷检测,在CSDN中看到了大神的博客《tiny YOLO v3做缺陷检测实战》,他用的是TensorFlow+Keras框架。
https://blog.csdn.net/qq_27871973/article/details/85009026
当我照着做的时候,TensorFlow死活报各种Error。经历了各种升级降级包库,删了又装,装了又删的折磨后,决定转战pytorch。因为大神说YOLO v3做DAGM的数据集效果很好,所以我还是想用YOLO v3模型。搜了一下与该模型的相关的帖子《Pytorch实现YOLOv3训练自己的数据集》,这个帖子做的是红细胞检测。
https://blog.csdn.net/public669/article/details/98020800
我换成了缺陷检测的数据集。与《tiny YOLO v3做缺陷检测实战》只检测了3类缺陷相比,我把10类缺陷都做了。并且参考了一些文章,不用手动一个一个做数据集。
注:本文内所有的代码和数据集都可以下载
https://download.csdn.net/download/cheweng4363/12587683
1、数据下载
用的是德国DAGM 2007的数据集
官方网址:https://hci.iwr.uni-heidelberg.de/node/3616
网盘下载:链接:https://pan.baidu.com/s/1CHrH1tZ-B6kvi8U7--isaw 提取码:47jo
2、图像标注
《DAGM2007数据集转换成VOC格式》
参考大神的博客https://blog.csdn.net/weixin_40520963/article/details/105128122
3、下载tiny-yolo v3工程
https://github.com/ultralytics/yolov3
首先从上述链接上将pytorch框架clone下来,
4、数据准备
将数据集Annotations、JPEGImages复制到YOLOV3工程目录下的data文件下;同时新建两个文件夹,分别命名为ImageSets和labels,最后我们将JPEGImages文件夹复制粘贴一下,并将文件夹重命名为images
在工程的根目录下新建两个文件makeTxt.py和voc_label.py
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ["Class1", "Class2", "Class3", "Class4", "Class5", "Class6", "Class7", "Class8", "Class9", "Class10"] # 类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()分别运行makeTxt.py和voc_label.py
运行makeTxt.py后ImagesSets后面会出现四个文件,主要存储图片名称,如下图:

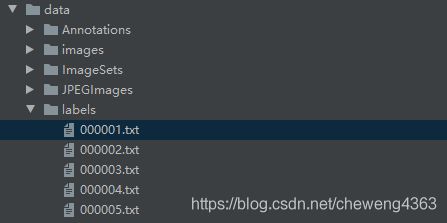
运行voc_label.py后labels后,如下图所示:
接着还要配置两个文件
在data文件下新建defect.data,配置内容如下:
classes=10
train=data/train.txt
valid=data/test.txt
names=data/defect.names
backup=backup/
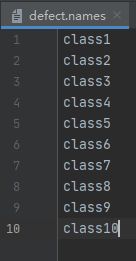
eval=coco再在data文件下新建defect.names,配置内容如下
5、获取网络参数
获取网络参数yolov3-tiny.weights,下载链接https://pjreddie.com/media/files/yolov3-tiny.weights,下载后导入weights文件夹下;同样还需要下载yolov3-tiny.conv.15,下载导入weights文件夹下,下载链接如下:https://pan.baidu.com/s/1nv1cErZeb6s0A5UOhOmZcA 提取码:t7vp
6、训练
在pycharm的terminal运行
python train.py --data data/defect.data --cfg cfg/yolov3-tiny.cfg --epochs 10 --weights weights/yolov3-tiny.weights --device 0 --batch-size 8根据自己电脑配置情况改device和batch-size

正确率0.456,召回率0.807
7、预测
把测试集图片放到samples文件夹里面
在pycharm的terminal运行
python detect.py --cfg cfg/yolov3-tiny.cfg --names data/defect.names --weights weights/best.pt --device 0测试结果在output文件夹里面
欢迎留言交流....