QT的正则表达式
Regexps由表达式(expressions)、量词(quantifiers)和断言(assertions)组成。
最简单的一个表达式就是一个字符,例如x和5。而一组字符可以使用方括号括起来,例如[ABC]将会匹配一个A或者一个B或者一个C,这个也可以简写为[A-C],这样我们要匹配所有的英文大写字母,就可以使用[A-Z]。
一个量词指定了必须要匹配的表达式出现的次数。例如,x{1,1}意味着必须匹配且只能匹配一个字符x,而x{1,5}意味着匹配一列字符x,其中至少要包含一个字符x,但是最多包含5个字符x。
现在假设我们要使用一个regexp来匹配0到99之间的整数。因为至少要有一个数字,所以我们使用表达式 [0-9]{1,1} 开始,它匹配一个单一的数字一次。要匹配0-99,我们可以想到将表达式最多出现的次数设置为2,即 [0-9]{1,2} 。
现在这个regexp已经可以满足我们假设的需要了,不过,它也会匹配出现在字符串中间的整数。如果想匹配的整数是整个字符串,那么就需要使用断言“^”和“$”,
当 ^ 在regexp中作为第一个字符时,意味着这个regexp必须从字符串的开始进行匹配;
当 $ 在regexp中作为最后一个字符时,意味着regexp必须匹配到字符串的结尾。
所以,最终的regexp为 ^[0-9]{1,2}$ 。 一般可以使用一些特殊的符号来表示一些常见的字符组和量词。
例如,[0-9] 可以使用 \d 来替代。而对于只出现一次的量词 {1,1} ,可以使用表达式本身代替,例如x{1,1}等价于x 。所以要匹配0-99,就可以写为 ^\d{1,2}$ 或者 ^\d\d{0,1}$ 。而 {0,1} 表示字符是可选的,就是只出现一次或者不出现,它可以使用 ?来代替,这样regexp就可以写为 ^\d\d?$ ,它意味着从字符串的开始,匹配一个数字,紧接着是0个或1个数字,再后面就是字符串的结尾。
现在我们写一个regexp来匹配单词“mail”或者“letter”其中的一个,但是不要匹配那些包含这些单词的单词,比如“email”和“letterbox”。要匹配“mail”,regexp可以写成m{1,1}a{1,1}i{1,1}l{1,1} ,因为 {1,1} 可以省略,所以又可以简写成mail 。下面就可以使用竖线“|”来包含另外一个单词,这里“|”表示“或”的意思。为了避免regexp匹配多余的单词,必须让它从单词的边界进行匹配。
首先,将regexp用括号括起来,即 (mail|letter) 。括号将表达式组合在一起,可以在一个更复杂的regexp中作为一个组件来使用,这样也可以方便我们来检测到底是哪一个单词被匹配了。为了强制匹配的开始和结束都在单词的边界上,要将regexp包含在 \b 单词边界断言中,即 \b(mail|letter)\b 。这个 \b 断言在regexp中匹配一个位置,而不是一个字符,一个单词的边界是任何的非单词字符,如一个空格,新行,或者一个字符串的开始或者结束。
如果想使用一个单词,例如“Mail”,替换一个字符串中的字符M,但是当字符M的后面是“ail”的话就不再替换。这样我们可以使用 (?!E) 断言,例如这里regexp应该写成 M(?!Mail) 。
如果想统计“Eric”和“Eirik”在字符串中出现的次数,可以使用 \b(Eric|Eirik)\b 或者 \bEi?ri[ck]\b 。这里需要使用单词边界断言‘\b’来避免匹配那些包含了这些名字的单词。
示例:
QRegExp rx("^\\d\\d?$"); // 两个字符都必须为数字,第二个字符可以没有
qDebug() << rx.indexIn("a1"); // 结果为-1,不是数字开头
qDebug() << rx.indexIn("5"); // 结果为0
qDebug() << rx.indexIn("5b"); // 结果为-1,第二个字符不是数字
qDebug() << rx.indexIn("12"); // 结果为0
qDebug() << rx.indexIn(“123”); // 结果为-1,超过了两个字符
rx.setPattern("\\b(mail|letter)\\b"); // 匹配mail或者letter单词
qDebug() << rx.indexIn("emailletter"); // 结果为-1,mail不是一个单词
qDebug() << rx.indexIn("my mail"); // 返回3
qDebug() << rx.indexIn("my email letter"); // 返回9
rx.setPattern("M(?!ail)"); // 匹配字符M,其后面不能跟有ail字符
QString str1 = "this is M";
str1.replace(rx,"Mail"); // 使用"Mail"替换匹配到的字符
qDebug() << "str1: " << str1; // 结果为this is Mail
QString str2 = "my M,your Ms,his Mail";
str2.replace(rx,"Mail");
qDebug() << "str2: " << str2; // 结果为my Mail,your Mails,his Mail
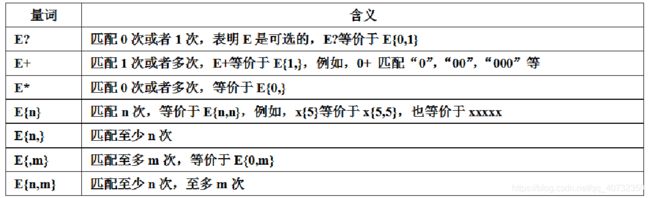
量词
默认的,一个表达式将自动量化为{1,1},就是说它应该出现一次。在下表中列出了量词的使用情况,其中E代表一个表达式,一个表达式可以是一个字符,或者一个字符集的缩写,或者在方括号中的一个字符集,或者在括号中的一个表达式。
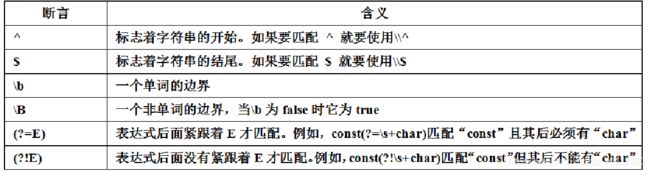
断言
断言在regexp中作出一些有关文本的声明,它们不匹配任何字符。正则表达式中的断言如下表所示,其中E代表一个表达式。
通配符
QRegExp类还支持通配符(Wildcard)匹配。很多命令shell(例如bash和cmd.exe)都支持文件通配符(file globbing),可以使用通配符来识别一组文件。QRegExp的setPatternSyntax()函数就是用来在regexp和通配符之间进行切换的。通配符匹配要比regexp简单很多,它只有四个特点,如下表所示。

文本捕获
在regexp中使用括号可以使一些元素组合在一起,这样既可以对它们进行量化,也可以捕获它们。例如,使用表达式 mail|letter 来匹配一个字符串,我们知道了有一个单词被匹配了,但是却不能知道具体是哪一个,使用括号就可以让我们捕获被匹配的那个单词,比如使用 (mail|letter) 来匹配字符串“I Sent you some email”,这样就可以使用cap()或者capturedTexts()函数来提取匹配的字符。
还可以在regexp中使用捕获到的文本,为了表示捕获到的文本,使用反向引用 \n ,其中n从1开始编号,比如 \1 就表示前面第一个捕获到的文本。例如,使用\b(\w+)\W+\1\b 在一个字符串中查询重复出现的单词,这意味着先匹配一个单词边界,随后是一个或者多个单词字符,随后是一个或者多个非单词字符,随后是与前面第一个括号中相同的文本,随后是单词边界。
如果使用括号仅仅是为了组合元素而不是为了捕获文本,那么可以使用非捕获语法,例如 (?:green|blue) 。非捕获括号由“(?:”开始,由“)”结束。使用非捕获括号比使用捕获括号更高效,因为regexp引擎只需做较少的工作。
实例:
QRegExp rx4("(\\d+)");
QString str4 = "Offsets: 12 14 99 231 7";
QStringList list;
int pos2 = 0;
while ((pos2 = rx4.indexIn(str4, pos2)) != -1)
{
list << rx4.cap(1); // 第一个捕获到的文本
pos2 += rx4.matchedLength(); // 上一个匹配的字符串的长度
}
qDebug() << list; // 结果12,14,99,231,7
QRegExp rxlen("(\\d+)(?:\\s*)(cm|inch)");
int pos3 = rxlen.indexIn("Length: 189cm");
if (pos3 > -1) {
QString value = rxlen.cap(1); // 结果为189
QString unit = rxlen.cap(2); // 结果为cm
QString string = rxlen.cap(0); // 结果为189cm
qDebug() << value << unit << string;
}