YOLOv3源码解析3-网络结构YOLOV3()
YOLOv3源码解析1-代码整体结构
YOLOv3源码解析2-数据预处理Dataset()
YOLOv3源码解析3-网络结构YOLOV3()
YOLOv3源码解析4-计算损失compute_loss()
YOLOv3源码解析5-损失函数
理论部分参照大神的文章学习:
简书:关于YOLOv3的一些细节
github:源代码作者YOLOV3
知乎:【YOLO】yolo v1到yolo v3
知乎:目标检测|YOLO原理与实现
知乎:YOLO v3深入理解
CSDN:yolo系列之yolo v3【深度解析】
解析的代码地址:
github:tensorflow-yolov3
本文解析YOLOV3()建立网络结构部分:

这部分代码看着很庞大,其实是很多结构的重复。
在train.py中的第52行调用了YOLOV3()
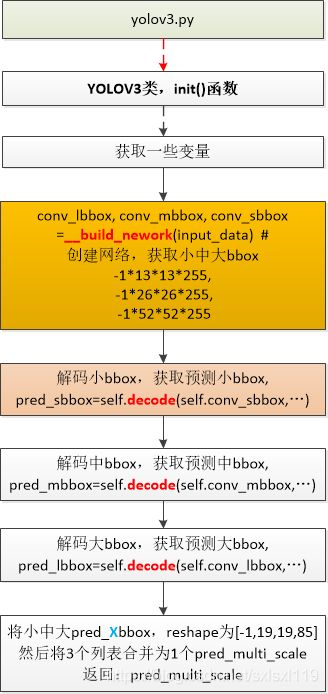
self.model = YOLOV3(self.input_data, self.trainable)然后进入yolov3.py代码,执行YOLOV3类的__init__函数,同样先是获取相关参数,然后先后调用了__build_nework(input_data) 函数来创建网络,并获取卷积后的大中小特征图;再调用decode()函数解码。
我觉得这玩意没啥好说的,就是各种卷积激活卷积激活,激活卷积,卷积卷积激活...
YOLOV3()初始部分
结构图:
对应源码:
class YOLOV3(object):
"""Implement tensorflow yolov3 here 在这里实现tensorflow yolov3"""
def __init__(self, input_data, trainable):
# 获取相关变量
self.trainable = trainable # 是否训练
self.classes = utils.read_class_names(cfg.YOLO.CLASSES) # 读取类别名称
self.num_class = len(self.classes) # 类别数量
self.strides = np.array(cfg.YOLO.STRIDES) # 下采样倍率 小中大
self.anchors = utils.get_anchors(cfg.YOLO.ANCHORS) # 获取anchor
self.anchor_per_scale = cfg.YOLO.ANCHOR_PER_SCALE # 每个框anchor数量
self.iou_loss_thresh = cfg.YOLO.IOU_LOSS_THRESH # 交并比 loss阈值
self.upsample_method = cfg.YOLO.UPSAMPLE_METHOD # 上采样方法
try:
self.conv_lbbox, self.conv_mbbox, self.conv_sbbox = self.__build_nework(input_data) # 创建网络
except:
raise NotImplementedError("Can not build up yolov3 network!")
with tf.variable_scope('pred_sbbox'):
self.pred_sbbox = self.decode(self.conv_sbbox, self.anchors[0], self.strides[0]) # strides[0]=8
with tf.variable_scope('pred_mbbox'):
self.pred_mbbox = self.decode(self.conv_mbbox, self.anchors[1], self.strides[1]) # strides[1]=16
with tf.variable_scope('pred_lbbox'):
self.pred_lbbox = self.decode(self.conv_lbbox, self.anchors[2], self.strides[2]) # strides[2]=32
"""
with tf.variable_scope('pred_multi_scale'):
self.pred_multi_scale = tf.concat([tf.reshape(self.pred_sbbox, [-1, 85]),
tf.reshape(self.pred_mbbox, [-1, 85]),
tf.reshape(self.pred_lbbox, [-1, 85])], axis=0, name='concat')
"""
# hand-coded the dimensions: if 608, use 19; if 416, use 13
with tf.variable_scope('pred_multi_scale'):
self.pred_multi_scale = tf.concat([tf.reshape(self.pred_sbbox, [-1, 19, 19, 85]),
tf.reshape(self.pred_mbbox, [-1, 19, 19, 85]),
tf.reshape(self.pred_lbbox, [-1, 19, 19, 85])], axis=0, name='concat')
__build_nework(input_data) 函数
结构图:
对应源码:
# 构建网络结构
def __build_nework(self, input_data):
route_1, route_2, input_data = backbone.darknet53(input_data, self.trainable)
# input_data is -1*13*13*1024
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv52')
input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv53')
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv54')
input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv55')
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv56')
conv_lobj_branch = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, name='conv_lobj_branch')
# -1*13*13*[3*(self.num_class + 5)]
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(self.num_class + 5)),
trainable=self.trainable, name='conv_lbbox', activate=False, bn=False)
# -1*13*13*512 --> -1*13*13*256
input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv57')
# upsampling input data (1/32) to match route_2 (1/16), -1*26*26*512
# -1*13*13*256 --> -1*26*26*256
input_data = common.upsample(input_data, name='upsample0', method=self.upsample_method)
with tf.variable_scope('route_1'):
# route_2 is -1*26*26*512, 最终input_data is -1*26*26*768
input_data = tf.concat([input_data, route_2], axis=-1)
input_data = common.convolutional(input_data, (1, 1, 768, 256), self.trainable, 'conv58')
input_data = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, 'conv59')
input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv60')
input_data = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, 'conv61')
input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv62')
conv_mobj_branch = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, name='conv_mobj_branch' )
# -1*26*26*[3*(self.num_class + 5)]
conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(self.num_class + 5)),
trainable=self.trainable, name='conv_mbbox', activate=False, bn=False)
input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv63')
# -1*26*26*128 --> -1*52*52*128
input_data = common.upsample(input_data, name='upsample1', method=self.upsample_method)
with tf.variable_scope('route_2'):
# route_1, -1*52*52*256, 最终input_data is -1*52*52*384
input_data = tf.concat([input_data, route_1], axis=-1)
input_data = common.convolutional(input_data, (1, 1, 384, 128), self.trainable, 'conv64')
input_data = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, 'conv65')
input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv66')
input_data = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, 'conv67')
input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv68')
conv_sobj_branch = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, name='conv_sobj_branch')
# -1*52*52*[3*(self.num_class + 5)]
conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(self.num_class + 5)),
trainable=self.trainable, name='conv_sbbox', activate=False, bn=False)
# dimensions are: -1*13*13*255, -1*26*26*255, -1*52*52*255
return conv_lbbox, conv_mbbox, conv_sbbox其中的darknet53()(backbone.py文件中):
结构图:
源码:
def darknet53(input_data, trainable):
with tf.variable_scope('darknet'):
input_data = common.convolutional(input_data, filters_shape=(3, 3, 3, 32), trainable=trainable, name='conv0')
input_data = common.convolutional(input_data, filters_shape=(3, 3, 32, 64),
trainable=trainable, name='conv1', downsample=True)
for i in range(1):
input_data = common.residual_block(input_data, 64, 32, 64, trainable=trainable, name='residual%d' %(i+0))
input_data = common.convolutional(input_data, filters_shape=(3, 3, 64, 128),
trainable=trainable, name='conv4', downsample=True)
for i in range(2):
input_data = common.residual_block(input_data, 128, 64, 128, trainable=trainable, name='residual%d' %(i+1))
input_data = common.convolutional(input_data, filters_shape=(3, 3, 128, 256),
trainable=trainable, name='conv9', downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 256, 128, 256, trainable=trainable, name='residual%d' %(i+3))
route_1 = input_data
input_data = common.convolutional(input_data, filters_shape=(3, 3, 256, 512),
trainable=trainable, name='conv26', downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 512, 256, 512, trainable=trainable, name='residual%d' %(i+11))
route_2 = input_data
input_data = common.convolutional(input_data, filters_shape=(3, 3, 512, 1024),
trainable=trainable, name='conv43', downsample=True)
for i in range(4):
input_data = common.residual_block(input_data, 1024, 512, 1024, trainable=trainable, name='residual%d' %(i+19))
# route_1, -1*52*52*256
# route_2, -1*26*26*512
# input_data -1*13*13*1024
return route_1, route_2, input_data其中的两个反复出现的单元convolutional()和residual_block()
-
convolutional()
结构图:
源码:
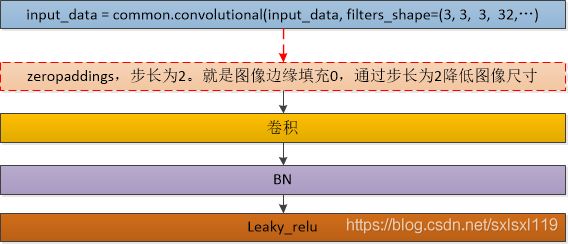
# 基本单元:zeropaddings(为true时)+卷积+BN+leaky_relu
def convolutional(input_data, filters_shape, trainable, name, downsample=False, activate=True, bn=True):
with tf.variable_scope(name):
if downsample: # 下采样
pad_h, pad_w = (filters_shape[0] - 2) // 2 + 1, (filters_shape[1] - 2) // 2 + 1
paddings = tf.constant([[0, 0], [pad_h, pad_h], [pad_w, pad_w], [0, 0]])
input_data = tf.pad(input_data, paddings, 'CONSTANT')
strides = (1, 2, 2, 1) # 不用pooling缩放图像
padding = 'VALID'
else:
strides = (1, 1, 1, 1)
padding = "SAME"
weight = tf.get_variable(name='weight', dtype=tf.float32, trainable=True,
shape=filters_shape, initializer=tf.random_normal_initializer(stddev=0.01))
conv = tf.nn.conv2d(input=input_data, filter=weight, strides=strides, padding=padding)
if bn:
conv = tf.layers.batch_normalization(conv, beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean_initializer=tf.zeros_initializer(),
moving_variance_initializer=tf.ones_initializer(), training=trainable)
else:
bias = tf.get_variable(name='bias', shape=filters_shape[-1], trainable=True,
dtype=tf.float32, initializer=tf.constant_initializer(0.0))
conv = tf.nn.bias_add(conv, bias)
if activate == True: conv = tf.nn.leaky_relu(conv, alpha=0.1)
return conv-
residual_block()
结构图:
源码:
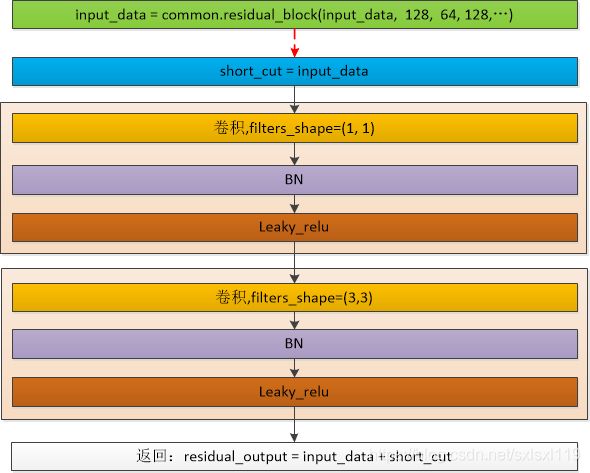
# 基本单元: 卷积+BN+leaky_relu + 卷积+BN+leaky_relu
def residual_block(input_data, input_channel, filter_num1, filter_num2, trainable, name):
short_cut = input_data
with tf.variable_scope(name):
input_data = convolutional(input_data, filters_shape=(1, 1, input_channel, filter_num1),
trainable=trainable, name='conv1')
input_data = convolutional(input_data, filters_shape=(3, 3, filter_num1, filter_num2),
trainable=trainable, name='conv2')
residual_output = input_data + short_cut
return residual_outputdecode()函数
结构图:
源码:
# 解码 1.3.1 边界框的预测
def decode(self, conv_output, anchors, stride):
"""
return tensor of shape [batch_size, output_size, output_size, anchor_per_scale, 5 + num_classes]
contains (x, y, w, h, score, probability)
"""
conv_shape = tf.shape(conv_output) # 获取
batch_size = conv_shape[0] #
output_size = conv_shape[1] # 13,26,52 dimensions are: -1*13*13*255, -1*26*26*255, -1*52*52*255
# number of anchors
anchor_per_scale = len(anchors) # 每个框anchor数量
# shape(batch_size, output_size, output_size, anchor_per_scale, 5 + self.num_class)
conv_output = tf.reshape(conv_output, (batch_size, output_size, output_size, anchor_per_scale, 5 + self.num_class))
conv_raw_dxdy = conv_output[:, :, :, :, 0:2] # 取 dx dy 中心位置的偏移量
conv_raw_dwdh = conv_output[:, :, :, :, 2:4] # 取 dw dh 预测框长宽的偏移量
conv_raw_conf = conv_output[:, :, :, :, 4:5] # 取 置信度
conv_raw_prob = conv_output[:, :, :, :, 5: ] # 取 预测概率
# tf.tile creates a new tensor by replicating input m time
# tf.tile通过复制输入的时间创建一个新的张量
# 好了,接下来需要画网格了。其中,output_size 等于 13、26 或者 52
y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size])
x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1])
xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1) # 数据合并
# 计算网格左上角的位置,相当于图中的Cx,Cy
xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, anchor_per_scale, 1])
xy_grid = tf.cast(xy_grid, tf.float32) # tf.cast()数据类型转换
# tf.sigmoid(dxdy) gives the relative position within a grid cell. Adding the position of the cell (xy_grid)
# multiplying stride scales the relative positions to the original image
# 根据上图公式计算预测框的中心位置
pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * stride # 乘上缩放的倍数映射到原图坐标,如 8、16 和 32 倍。
# tf.exp() scales the anchors larger or smaller or changes the shape
# 根据上图公式计算预测框的长和宽大小
pred_wh = (tf.exp(conv_raw_dwdh) * anchors) * stride # 预测的 w,h
# 合并边界框的位置和长宽信息
pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1) # 合并预测的x,y,w,h
pred_conf = tf.sigmoid(conv_raw_conf) # 计算预测框里object的置信度
pred_prob = tf.sigmoid(conv_raw_prob) # 计算预测框里object的类别概率
return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)这部分就是各种结构,没啥好说的,所以就是结构图和源码花式组合了[捂脸]
