pytorch源码解析系列-yolov4最核心技巧代码详解(1)-网络结构
yoloV4
关于YOLOV1-3自行参考百度,本文只用代码展现YOLOV4中核心部分实现方式
1. CBM CBL
以下代码部分参考源码
内容,图片参考了江大白的知乎

conv+batch+mish(Leaky relu)
效果:就是leakly relu的效果,防止梯度为0
结果:backbone用了mish,准确率提高了0.3%-0.9%
class Conv_Bn_Activation(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, activation, bn=True, bias=False):
super().__init__()
pad = (kernel_size - 1) // 2
self.conv = nn.ModuleList()
if bias:##启用bias
self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad))
else:
self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad, bias=False))
if bn:#启用bn
self.conv.append(nn.BatchNorm2d(out_channels))
if activation == "mish":#启用mish激活
self.conv.append(nn.Mish())
elif activation == "leaky":#启用Leaky relu激活
self.conv.append(nn.LeakyReLU(0.1, inplace=False))
def forward(self, x):
for l in self.conv:
x = l(x)
return x
2. Res unit
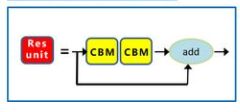
残差模块
效果:帮助构建深层网络,防止梯度消失、爆炸
class ResBlock(nn.Module):
#ch:入参出参的通道数
#nblocks:残差块数量
#shortcut:是否使用shortcut操作
def __init__(self, ch, nblocks=1, shortcut=True):
super().__init__()
self.shortcut = shortcut
self.module_list = nn.ModuleList()
for i in range(nblocks):
resblock_one = nn.ModuleList()
## 重点在这里 残差块加了两个cbm
resblock_one.append(Conv_Bn_Activation(ch, ch, 1, 1, 'mish'))
resblock_one.append(Conv_Bn_Activation(ch, ch, 3, 1, 'mish'))
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
h = x
for res in module:
h = res(h)
#shortcut操作,相当于引一条小路(h) 直接通到残差块结束部分(+)
x = x + h if self.shortcut else h
return x
3 CSPX
效果:轻量化的同时保持准确性,降低计算瓶颈,降低计算成本
个人理解,讲白了就是原来全部都丢残差网络,就是现在只丢一部分,减少梯度重复,能保持准确性,降低计算

cross stage partial ,效果就如同名字一样,后面X代表残差块数量(就是上面的一个resblock)
看代码就知道原理了,下面的代码就是传说中的cspdarknet53
class Yolov4(nn.Module):
def __init__(self, yolov4conv137weight=None, n_classes=80, inference=False):
super().__init__()
output_ch = (4 + 1 + n_classes) * 3
# backbone
self.down1 = DownSample1() #cbm+csp1
self.down2 = DownSample2() #(ch=64, nblocks=2)
self.down3 = DownSample3() #(ch=128, nblocks=8)
self.down4 = DownSample4() #(ch=256, nblocks=8)
self.down5 = DownSample5() #(ch=512, nblocks=4)
可以看到5个downsample对应的就是图中5个csp
我以其中一个为例:

class DownSample5(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv_Bn_Activation(512, 1024, 3, 2, 'mish')
self.conv2 = Conv_Bn_Activation(1024, 512, 1, 1, 'mish')
self.conv3 = Conv_Bn_Activation(1024, 512, 1, 1, 'mish')
self.resblock = ResBlock(ch=512, nblocks=4)
self.conv4 = Conv_Bn_Activation(512, 512, 1, 1, 'mish')
self.conv5 = Conv_Bn_Activation(1024, 1024, 1, 1, 'mish')
def forward(self, input):
x1 = self.conv1(input)
#这边分两条路 一条走一个cbm 得出x2
x2 = self.conv2(x1)
#另一条路走cbm+res+cbm 得出x4
x3 = self.conv3(x1)
r = self.resblock(x3)
x4 = self.conv4(r)
# 两条路的结果concat一下 走下一个cbm
x4 = torch.cat([x4, x2], dim=1)
x5 = self.conv5(x4)
return x5
走过5个下采样 最后输入变化为
608->304->152->76->38->19
所以输出的是19*19,有兴趣可以自己计算一下
4.SPP
金字塔池化
效果:更有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征,处理输入结构不一问题
结果:提高了2.7% AP50
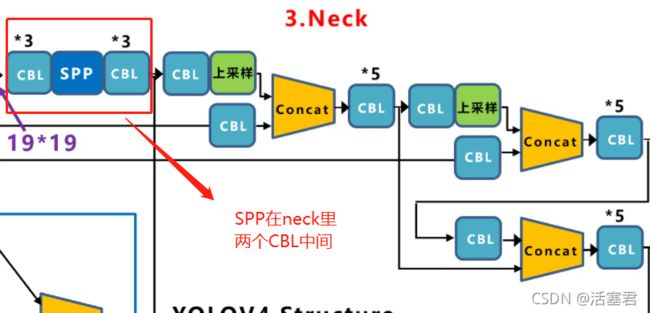
简单来说就是用3个核(还有一个自身1X1,所以是4个)大小不一样的maxpool分别整一个结果,然后把它们cat在一起。
具体看代码理解:
class Neck(nn.Module):
def __init__(self, inference=False):
super().__init__()
#neck网络前半部分 3个CBL 最后输出深度是**512 注意
self.conv1 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv2 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv3 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
# SPP 分别用了size 5 9 13 的maxpoll
# 为了防止你们忘了 给下计算公式 outsize = (原长+2*padding-kernel_size)/stride+1
# 所以这边等于是same padding,新版pytorch直接指定pdding = same就可以了
self.maxpool1 = nn.MaxPool2d(kernel_size=5, stride=1, padding=5 // 2)
self.maxpool2 = nn.MaxPool2d(kernel_size=9, stride=1, padding=9 // 2)
self.maxpool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13 // 2)
# R -1 -3 -5 -6
# neck网络后半部分
# 注意 这里因为有4个512** 因为有4个maxpoll 所以深度是2048
self.conv4 = Conv_Bn_Activation(2048, 512, 1, 1, 'leaky')
self.conv5 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv6 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv7 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
def forward(self, input, downsample4, downsample3, inference=False):
# SPP
m1 = self.maxpool1(x3)
m2 = self.maxpool2(x3)
m3 = self.maxpool3(x3)
# SPP的concat操作 这里是1 5 9 13 四个maxpoll的结果
spp = torch.cat([m3, m2, m1, x3], dim=1)
# SPP end
x4 = self.conv4(spp)
x5 = self.conv5(x4)
x6 = self.conv6(x5)
x7 = self.conv7(x6)
neck网络后半部分,主要是上采样,代码看看就好:
FPN + PAN
效果:提高特征提取能力
Feature Pyramid Network 金字塔网络
Path Aggregation Network 路径聚合网络
这一部分不说下原理的话 看代码可能不能理解,我就简单提一句,想理解更深可以去大白的知乎看
FPN:自顶向下,传达强语义特征

PAN:自底向上,传达强定位特征

这么做的原因是把不同检测层级的参数聚合,提高特征提取能力
知道原理,看代码就容易理解了:
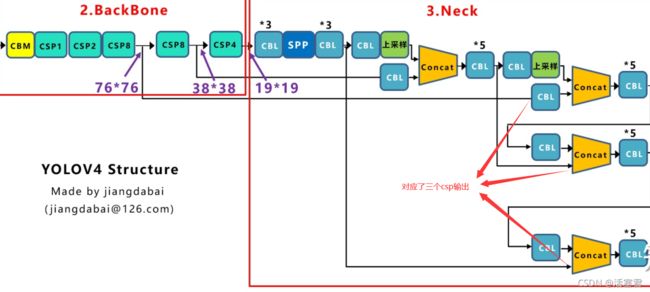
neck前半部分:FPN:
class Neck(nn.Module):
def __init__(self, inference=False):
super().__init__()
# 前面是SPP 省略
# 这里对应的就是图上第一个上采样
self.upsample1 = Upsample()
# R 85
self.conv8 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
# R -1 -3
self.conv9 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv10 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv11 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv12 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv13 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv14 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
# 这里对应的就是图上第二个上采样
self.upsample2 = Upsample()
# R 54
self.conv15 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
# R -1 -3
self.conv16 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
self.conv17 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
self.conv18 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
self.conv19 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
self.conv20 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
def forward(self, input, downsample4, downsample3, inference=False):
#前面是SPP 省略
# 第一个上采样
up = self.upsample1(x7, downsample4.size(), self.inference)
# downsample4就是之前csp层出来的 用于FPN的concat
x8 = self.conv8(downsample4)
# concat操作 金字塔上采样第一步
x8 = torch.cat([x8, up], dim=1)
#5 个cbl
x9 = self.conv9(x8)
x10 = self.conv10(x9)
x11 = self.conv11(x10)
x12 = self.conv12(x11)
x13 = self.conv13(x12)
x14 = self.conv14(x13)
# 后面和上面同理 第二个上采样
up = self.upsample2(x14, downsample3.size(), self.inference)
x15 = self.conv15(downsample3)
x15 = torch.cat([x15, up], dim=1)
x16 = self.conv16(x15)
x17 = self.conv17(x16)
x18 = self.conv18(x17)
x19 = self.conv19(x18)
x20 = self.conv20(x19)
return x20, x13, x6
顺带一提 上采样是:
class Upsample(nn.Module):
def __init__(self):
super(Upsample, self).__init__()
def forward(self, x, target_size, inference=False):
assert (x.data.dim() == 4)
if inference:
#下面代码 相当于nn.Upsample((target_size[2] // x.size(2),target_size[3] // x.size(3)),mode='nearest') 最邻插值
return x.view(x.size(0), x.size(1), x.size(2), 1, x.size(3), 1).\
expand(x.size(0), x.size(1), x.size(2), target_size[2] // x.size(2), x.size(3), target_size[3] // x.size(3)).\
contiguous().view(x.size(0), x.size(1), target_size[2], target_size[3])
else:
return F.interpolate(x, size=(target_size[2], target_size[3]), mode='nearest')
class Yolov4(nn.Module):
def __init__(self, yolov4conv137weight=None, n_classes=80, inference=False):
super().__init__()
# backbone
省略
# neck
self.neek = Neck(inference)
# yolov4conv137
# head
self.head = Yolov4Head(output_ch, n_classes, inference)
def forward(self, input):
d1 = self.down1(input)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
#**注意 这里的d5,d4,d3 对应csp的三个输出 看图
x20, x13, x6 = self.neek(d5, d4, d3)
#然后将3个输出传给head 看后面
output = self.head(x20, x13, x6)
return output
上面代码是第一步 取得之前csp的三个输出
再通过head
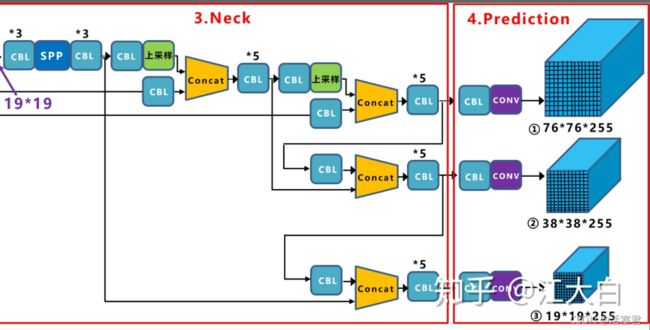
# 这边代码很长,基本上就是图片中的步骤,可以直接看西面step加深理解即可
class Yolov4Head(nn.Module):
def __init__(self, output_ch, n_classes, inference=False):
super().__init__()
self.inference = inference
self.conv1 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
self.conv2 = Conv_Bn_Activation(256, output_ch, 1, 1, 'linear', bn=False, bias=True)
self.yolo1 = YoloLayer(
anchor_mask=[0, 1, 2], num_classes=n_classes,
anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
num_anchors=9, stride=8)
# R -4
self.conv3 = Conv_Bn_Activation(128, 256, 3, 2, 'leaky')
# R -1 -16
self.conv4 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv5 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv6 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv7 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv8 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv9 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv10 = Conv_Bn_Activation(512, output_ch, 1, 1, 'linear', bn=False, bias=True)
self.yolo2 = YoloLayer(
anchor_mask=[3, 4, 5], num_classes=n_classes,
anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
num_anchors=9, stride=16)
# R -4
self.conv11 = Conv_Bn_Activation(256, 512, 3, 2, 'leaky')
# R -1 -37
self.conv12 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv13 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv14 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv15 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv16 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv17 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv18 = Conv_Bn_Activation(1024, output_ch, 1, 1, 'linear', bn=False, bias=True)
self.yolo3 = YoloLayer(
anchor_mask=[6, 7, 8], num_classes=n_classes,
anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
num_anchors=9, stride=32)
def forward(self, input1, input2, input3):
#input1 就是图片最上面的输出,经过一个CBL和Conv得到76*76的prediction:x2
x1 = self.conv1(input1)
x2 = self.conv2(x1)
# input1经过一个cbl加上input2 再经过5个CBL得到x8
# x8经过经过一个CBL和Conv得到38*38的prediction:x10 对应中间的输出
x3 = self.conv3(input1)
x3 = torch.cat([x3, input2], dim=1)
x4 = self.conv4(x3)
x5 = self.conv5(x4)
x6 = self.conv6(x5)
x7 = self.conv7(x6)
x8 = self.conv8(x7)
x9 = self.conv9(x8)
x10 = self.conv10(x9)
#后面一样 对应下面的输出 cbl5 +cbl+conv得到prection:x18
x11 = self.conv11(x8)
x11 = torch.cat([x11, input3], dim=1)
x12 = self.conv12(x11)
x13 = self.conv13(x12)
x14 = self.conv14(x13)
x15 = self.conv15(x14)
x16 = self.conv16(x15)
x17 = self.conv17(x16)
x18 = self.conv18(x17)
#使用predict 看下面
if self.inference:
y1 = self.yolo1(x2)
y2 = self.yolo2(x10)
y3 = self.yolo3(x18)
return get_region_boxes([y1, y2, y3])
else:
return [x2, x10, x18]
可以看到三个
第一个Yolo层是最大的特征图x2 :76x76,mask=0,1,2,对应最小的anchor box。
第二个Yolo层是中等的特征图x10 :38x38,mask=3,4,5,对应中等的anchor box。
第三个Yolo层是最小的特征图x18: 19x19,mask=6,7,8,对应最大的anchor box。
后语
基础网络就是上面这么多
但是yolov4还有很多技巧 我会在后面文章继续介绍的