spark筑基篇-00-Spark集群环境搭建
- 说明
- 1 效果图
- 2 实验环境
- 3 配置ssh免登陆
- 集群搭建
- 1 配置环境变量
- 2 配置hadoop
- 21 core-sitexml
- 22 hdfs-sitexm
- 23 mapred-sitexml
- 24 yarn-sitexml
- 25 hadoop环境变量
- 26 slaves
- 27 复制到其他节点
- 28 验证
- 3 配置spark
- 31 spark环境变量
- 32 spark-envsh
- 33 slaves
- 34 spark-defaultsconf
- 35 复制到其他节点
- 验证
- 执行HelloWorld
1 说明
1.1 效果图
实现1个Master两个Worker的伪集群环境搭建。

1.2 实验环境
| item | desc |
|---|---|
| OS | CentOS release 6.7 (Final) |
| java | jdk-8u101-linux-x64.tar.gz |
| scala | scala-2.11.8.tgz |
| hadoop | hadoop-2.6.5.tar.gz |
| spark | spark-2.0.1-bin-hadoop2.6.tgz |
确保三台主机上的域名解析配置如下:
[root@h1 /]# cat /etc/hosts
127.0.0.1 localhost.localdomain localhost
192.168.161.128 h1
192.168.161.129 h2
192.168.161.130 h3
::1 localhost6.localdomain6 localhost61.3 配置ssh免登陆
配置好h1到h2,h3的ssh免登陆。
至于如何配置ssh免登陆可以参考本人的另一篇文章:ssh/OpenSSH
2 集群搭建
2.1 配置环境变量
这个没啥好说的了。以下是本人的配置:
# java
export JAVA_HOME=/soft/jdk1.8.0_101
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$PATH:$JAVA_HOME/bin
# scala
export SCALA_HOME=/soft/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin2.2 配置hadoop
# 下载
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
# 解压
tar -zxvf hadoop-2.6.5.tar.gz
# 可选(本人喜欢将软件统一安装的根目录的soft目录下)
mv hadoop-2.6.5 /soft/2.2.1 core-site.xml
vim /soft/hadoop-2.6.5/etc/hadoop/core-site.xml内容如下:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://h1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/soft/hadoop-2.6.5/tmpvalue>
property>
<property>
<name>hadoop.native.libname>
<value>truevalue>
property>
configuration>2.2.2 hdfs-site.xm
vim /soft/hadoop-2.6.5/etc/hadoop/hdfs-site.xml内容如下:
<configuration>
<property>
<name>sdf.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>h1:50090value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/soft/hadoop-2.6.5/dfs/datavalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///soft/hadoop-2.6.5/dfs/namesecondaryvalue>
property>
configuration>2.2.3 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml内容如下:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>2.2.4 yarn-site.xml
vim /soft/hadoop-2.6.5/etc/hadoop/yarn-site.xml内容如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>h1value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>2.2.5 hadoop环境变量
export HADOOP_HOME=/soft/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/bin2.2.6 slaves
vim /soft/hadoop-2.6.5/etc/hadoop/slaves内容如下:
h1
h2
h32.2.7 复制到其他节点
# 先格式化HDFS
/soft/hadoop-2.6.5/bin/hdfs namenode -format
# 复制到主机 h2
scp -r /soft/hadoop-2.6.5/ root@h2:/soft
# 复制到主机 h3
scp -r /soft/hadoop-2.6.5/ root@h3:/soft
# 同时别忘了其他机器上的环境变量2.2.8 验证
# 启动hdfs----在h1上操作即可
/soft/hadoop-2.6.5/sbin/start-all.sh# 看到正常启动之后分别在h1,h2,h3上查看java进程快照
# h1
[root@h1 sbin]# jps
4225 SecondaryNameNode
4053 DataNode
3957 NameNode
4539 NodeManager
4574 Jps
4447 ResourceManager
# h2
[root@h2 soft]# jps
3499 Jps
3390 NodeManager
3231 DataNode
# h3
[root@h3 soft]# jps
3194 DataNode
3452 Jps
3342 NodeManager通过浏览器查看HDFS状态:http://h1:50070/dfshealth.html#tab-overview
tab-datanode标签可以看到如下内容:
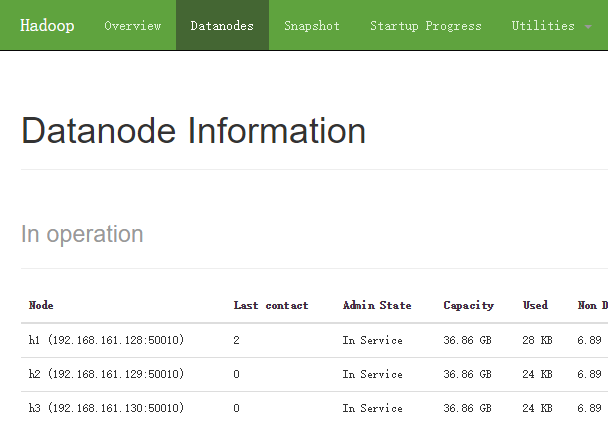
或者查看:http://h1:8088/cluster
2.3 配置spark
# 下载
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.6.tgz
# 解压
tar -zxvf spark-2.0.1-bin-hadoop2.6.tgz
# 可选(本人喜欢将软件统一安装的根目录的soft目录下)
mv spark-2.0.1-bin-hadoop2.6 /soft/2.3.1 spark环境变量
export SPARK_HOME=/soft/spark-2.0.1-bin-hadoop2.6/
export PATH=$PATH:$SPARK_HOME/bin2.3.2 spark-env.sh
cd /soft/spark-2.0.1-bin-hadoop2.6/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh在最后加入如下内容:
export JAVA_HOME=/soft/jdk1.8.0_101
export SCALA_HOME=/soft/scala-2.11.8
export HADOOP_HOME=/soft/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=h1
export SPARK_WORKER_MEMORY=512M
export SPARK_EXECUTOR_MEMORY=512M
export SPARK_DRIVER_MEMORY=512M
export SPARK_WORKER_CORES=12.3.3 slaves
cd /soft/spark-2.0.1-bin-hadoop2.6/conf
cp slaves.template slaves
vim slaves在最后加入如下内容:
h2
h32.3.4 spark-defaults.conf
cd /soft/spark-2.0.1-bin-hadoop2.6/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf在最后加入如下内容:
spark.executor.extraJavaOptions -XX:+PrintGCDetails -DKey=value -Dnumbers="one two three"
spark.eventLog.enabled true
spark.eventLog.dir hdfs://h1:9000/historyserverforSpark
spark.yarn.historyServer.address h1:18080
spark.history.fs.logDirectory hdfs://h1:9000/historyserverforSpark2.3.5 复制到其他节点
# 复制到h2
scp -r /soft/spark-2.0.1-bin-hadoop2.6/ root@h2:/soft
# 复制到h3
scp -r /soft/spark-2.0.1-bin-hadoop2.6/ root@h3:/soft
# 同时别忘了其他节点的环境变量验证
# 启动 - 在h1上操作即可
/soft/spark-2.0.1-bin-hadoop2.6/start-all.sh# h1
[root@h1 sbin]# jps
4435 SecondaryNameNode
4164 NameNode
4583 ResourceManager
4263 DataNode
4680 NodeManager
5020 Master
5084 Jps
# h2
[root@h2 soft]# jps
3284 DataNode
3543 Worker
3591 Jps
3384 NodeManager
# h3
[root@h3 soft]# jps
3280 DataNode
3538 Worker
3380 NodeManager
3588 Jps通过浏览器查看HDFS状态:http://h1:8080,可以看到如下内容:
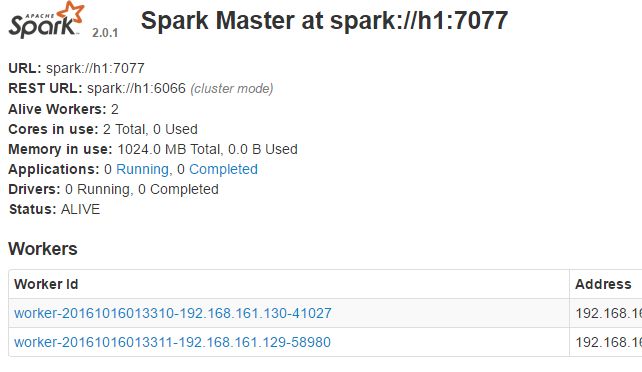
3 执行HelloWorld
此处的HelloWorld指的是Spark内置的例子中的一个用来计算PI的程序。
注意:
在执行该jar包前请先确保hadoop和Spark都已经启动。
另外,如果配置了日志服务,请先为其创建对应的日志目录再执行后续步骤:
hdfs dfs -mkdir /historyserverforSpark执行
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://h1:7077 \
--executor-memory 512m \
--total-executor-cores 10 \
/soft/spark-2.0.1-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.0.1.jar \
10结果
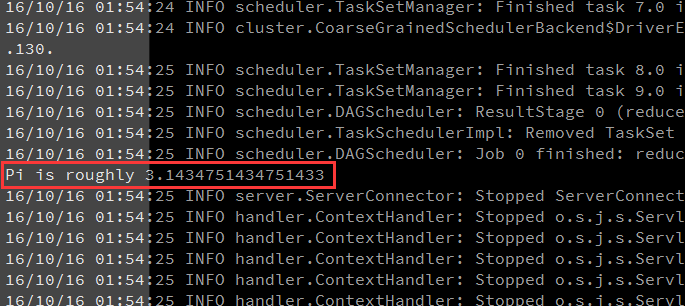
下一篇文章将分享在Eclipse中编写并执行SparkHello:spark筑基篇-01-Eclipse开发Spark HelloWorld