MobileOne: 移动端仅需1ms的高性能骨干
开源地址:
GitHub - shoutOutYangJie/MobileOne: An Improved One millisecond Mobile Backbone
tensorrt代码:
onnx转tensorrt学习笔记_AI视觉网奇的博客-CSDN博客_onnx转tensorrt
测试代码:
1060显卡上,224*224,cpu上10ms,gpu上3ms。
最新测试,cpu需要80ms,gpu需要12ms。cpu i5 12600kf。
https://github.com/shoutOutYangJie/MobileOne/blob/main/mobileone.py
比skipnet快,泛化能力也比skipnet高。
轻量级网络skipnet_AI视觉网奇的博客-CSDN博客_skip网络
import time
import torch.nn as nn
import numpy as np
import torch
import copy
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class DepthWiseConv(nn.Module):
def __init__(self, inc, kernel_size, stride=1):
super().__init__()
padding = 1
if kernel_size == 1:
padding = 0
# self.conv = nn.Sequential(
# nn.Conv2d(inc, inc, kernel_size, stride, padding, groups=inc, bias=False,),
# nn.BatchNorm2d(inc),
# )
self.conv = conv_bn(inc, inc, kernel_size, stride, padding, inc)
def forward(self, x):
return self.conv(x)
class PointWiseConv(nn.Module):
def __init__(self, inc, outc):
super().__init__()
# self.conv = nn.Sequential(
# nn.Conv2d(inc, outc, 1, 1, 0, bias=False),
# nn.BatchNorm2d(outc),
# )
self.conv = conv_bn(inc, outc, 1, 1, 0)
def forward(self, x):
return self.conv(x)
class MobileOneBlock(nn.Module):
def __init__(self, in_channels, out_channels, k, stride=1, dilation=1, padding_mode='zeros', deploy=False,
use_se=False):
super(MobileOneBlock, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
kernel_size = 3
padding = 1
assert kernel_size == 3
assert padding == 1
self.k = k
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
...
else:
self.se = nn.Identity()
if deploy:
self.dw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=in_channels,
bias=True, padding_mode=padding_mode)
self.pw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,
bias=True)
else:
# self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
# self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
# self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
# print('RepVGG Block, identity = ', self.rbr_identity)
self.dw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'dw_3x3_{k_idx}', DepthWiseConv(in_channels, 3, stride=stride))
self.dw_1x1 = DepthWiseConv(in_channels, 1, stride=stride)
self.pw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'pw_1x1_{k_idx}', PointWiseConv(in_channels, out_channels))
def forward(self, inputs):
if self.deploy:
x = self.dw_reparam(inputs)
x = self.nonlinearity(x)
x = self.pw_reparam(x)
x = self.nonlinearity(x)
return x
if self.dw_bn_layer is None:
id_out = 0
else:
id_out = self.dw_bn_layer(inputs)
x_conv_3x3 = []
for k_idx in range(self.k):
x = getattr(self, f'dw_3x3_{k_idx}')(inputs)
# print(x.shape)
x_conv_3x3.append(x)
x_conv_1x1 = self.dw_1x1(inputs)
# print(x_conv_1x1.shape, x_conv_3x3[0].shape)
# print(x_conv_1x1.shape)
# print(id_out)
x = id_out + x_conv_1x1 + sum(x_conv_3x3)
x = self.nonlinearity(self.se(x))
# 1x1 conv
if self.pw_bn_layer is None:
id_out = 0
else:
id_out = self.pw_bn_layer(x)
x_conv_1x1 = []
for k_idx in range(self.k):
x_conv_1x1.append(getattr(self, f'pw_1x1_{k_idx}')(x))
x = id_out + sum(x_conv_1x1)
x = self.nonlinearity(x)
return x
# Optional. This improves the accuracy and facilitates quantization.
# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.
# 2. Use like this.
# loss = criterion(....)
# for every RepVGGBlock blk:
# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()
# optimizer.zero_grad()
# loss.backward()
def get_custom_L2(self):
# K3 = self.rbr_dense.conv.weight
# K1 = self.rbr_1x1.conv.weight
# t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
# t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
# l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.
# eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.
# l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.
# return l2_loss_eq_kernel + l2_loss_circle
...
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
# kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
# kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
# kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
# return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
dw_kernel_3x3 = []
dw_bias_3x3 = []
for k_idx in range(self.k):
k3, b3 = self._fuse_bn_tensor(getattr(self, f"dw_3x3_{k_idx}").conv)
# print(k3.shape, b3.shape)
dw_kernel_3x3.append(k3)
dw_bias_3x3.append(b3)
dw_kernel_1x1, dw_bias_1x1 = self._fuse_bn_tensor(self.dw_1x1.conv)
dw_kernel_id, dw_bias_id = self._fuse_bn_tensor(self.dw_bn_layer, self.in_channels)
dw_kernel = sum(dw_kernel_3x3) + self._pad_1x1_to_3x3_tensor(dw_kernel_1x1) + dw_kernel_id
dw_bias = sum(dw_bias_3x3) + dw_bias_1x1 + dw_bias_id
# pw
pw_kernel = []
pw_bias = []
for k_idx in range(self.k):
k1, b1 = self._fuse_bn_tensor(getattr(self, f"pw_1x1_{k_idx}").conv)
# print(k1.shape)
pw_kernel.append(k1)
pw_bias.append(b1)
pw_kernel_id, pw_bias_id = self._fuse_bn_tensor(self.pw_bn_layer, 1)
pw_kernel_1x1 = sum(pw_kernel) + pw_kernel_id
pw_bias_1x1 = sum(pw_bias) + pw_bias_id
return dw_kernel, dw_bias, pw_kernel_1x1, pw_bias_1x1
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch, groups=None):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
bias = branch.conv.bias
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
# if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // groups # self.groups
if groups == 1:
ks = 1
else:
ks = 3
kernel_value = np.zeros((self.in_channels, input_dim, ks, ks), dtype=np.float32)
for i in range(self.in_channels):
if ks == 1:
kernel_value[i, i % input_dim, 0, 0] = 1
else:
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
dw_kernel, dw_bias, pw_kernel, pw_bias = self.get_equivalent_kernel_bias()
self.dw_reparam = nn.Conv2d(in_channels=self.pw_1x1_0.conv.conv.in_channels,
out_channels=self.pw_1x1_0.conv.conv.in_channels, kernel_size=self.dw_3x3_0.conv.conv.kernel_size,
stride=self.dw_3x3_0.conv.conv.stride, padding=self.dw_3x3_0.conv.conv.padding,
groups=self.dw_3x3_0.conv.conv.in_channels, bias=True, )
self.pw_reparam = nn.Conv2d(in_channels=self.pw_1x1_0.conv.conv.in_channels,
out_channels=self.pw_1x1_0.conv.conv.out_channels, kernel_size=1, stride=1, bias=True)
self.dw_reparam.weight.data = dw_kernel
self.dw_reparam.bias.data = dw_bias
self.pw_reparam.weight.data = pw_kernel
self.pw_reparam.bias.data = pw_bias
for para in self.parameters():
para.detach_()
self.__delattr__('dw_1x1')
for k_idx in range(self.k):
self.__delattr__(f'dw_3x3_{k_idx}')
self.__delattr__(f'pw_1x1_{k_idx}')
if hasattr(self, 'dw_bn_layer'):
self.__delattr__('dw_bn_layer')
if hasattr(self, 'pw_bn_layer'):
self.__delattr__('pw_bn_layer')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class MobileOneNet(nn.Module):
def __init__(self, blocks, ks, channels, strides, width_muls, num_classes, deploy=False):
super().__init__()
self.stage_num = len(blocks)
# self.stage0 = MobileOneBlock(3, int(channels[0] * width_muls[0]), ks[0], stride=strides[0], deploy=deploy)
self.stage0 = nn.Sequential(nn.Conv2d(4, int(channels[0] * width_muls[0]), 3, 2, 1, bias=False),
nn.BatchNorm2d(int(channels[0] * width_muls[0])), nn.ReLU(), )
in_channels = int(channels[0] * width_muls[0])
for idx, block_num in enumerate(blocks[1:]):
idx += 1
module = []
out_channels = int(channels[idx] * width_muls[idx])
for b_idx in range(block_num):
stride = strides[idx] if b_idx == 0 else 1
block = MobileOneBlock(in_channels, out_channels, ks[idx], stride, deploy=deploy)
in_channels = out_channels
module.append(block)
setattr(self, f"stage{idx}", nn.Sequential(*module))
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Sequential(nn.Linear(out_channels, num_classes, ), )
def forward(self, x):
# for s_idx in range(self.stage_num):
# x = getattr(self, f'stage{s_idx}')(x)
x0 = self.stage0(x)
# print(x0[0,:,0,0])
# return x0
x1 = self.stage1(x0)
x2 = self.stage2(x1)
x3 = self.stage3(x2)
x4 = self.stage4(x3)
x5 = self.stage5(x4)
x = self.avg_pool(x5)
x = torch.flatten(x, start_dim=1) # b, c
x = self.fc1(x)
return x
def make_mobileone_s0(num_classes,deploy=False):
blocks = [1, 2, 8, 5, 5, 1]
strides = [2, 2, 2, 2, 1, 2]
ks = [4, 4, 4, 4, 4, 4] if deploy is False else [1, 1, 1, 1, 1, 1]
width_muls = [0.75, 0.75, 1, 1, 1, 2] # 261 M flops
channels = [64, 64, 128, 256, 256, 512, 512]
model = MobileOneNet(blocks, ks, channels, strides, width_muls, num_classes, deploy)
return model
def repvgg_model_convert(model: torch.nn.Module, do_copy=True, input=None, output=None):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
print('swith done. Checking....')
deploy_model = make_mobileone_s0(26,deploy=True)
deploy_model.eval()
deploy_model.load_state_dict(model.state_dict())
if input is not None:
o = deploy_model(x)
# print(o)
# print(output)
print((output - o).sum())
# if save_path is not None:
# torch.save(model.state_dict(), save_path)
return deploy_model
if __name__ == '__main__':
model = make_mobileone_s0(num_classes=4)#.cuda(0)
model.eval()
data = torch.rand(1, 4, 128, 128)#.cuda(0)
for i in range(10):
start = time.time()
out = model(data)
print('time', time.time() - start, out.size())
MobileOne(≈MobileNetV1+RepVGG+训练Trick)是由Apple公司提出的一种基于iPhone12优化的超轻量型架构,在ImageNet数据集上以<1ms的速度取得了75.9%的Top1精度。
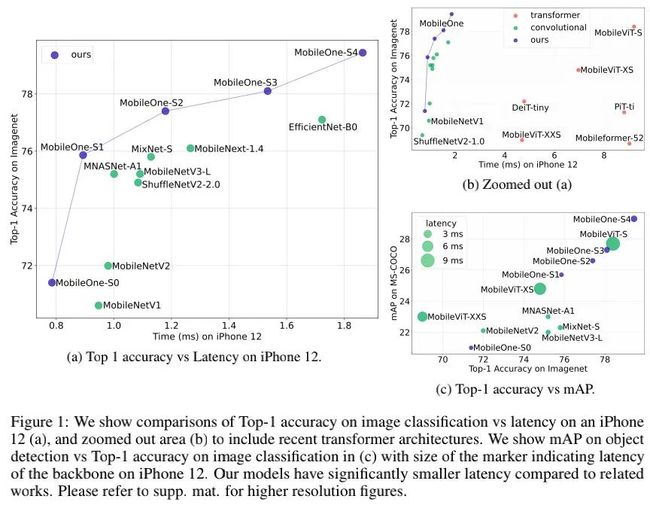
为更好的分析高效率网络的瓶颈所在,作者以iPhone12平台为基准,从不同维度进行了"瓶颈"分析,见上图。从中可以看到:
-
具有高参数量的模型也可以拥有低延迟,比如ShuffleNetV2;
-
具有高FLOPs的模型也可以拥有低延迟,比如MobileNetV1和ShuffleNetV2;
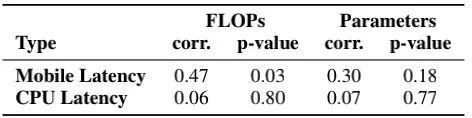
上表从SRCC角度进行了分析,可以看到:
-
在移动端,延迟与FLOPs和参数量的相关性较弱;
-
在PC-CPU端,该相关性进一步弱化。
具体方案
基于上述洞察,作者从先两个主要效率"瓶颈"维度上进行了对比,然后对性能"瓶颈"进行了分析并提出相应方案。
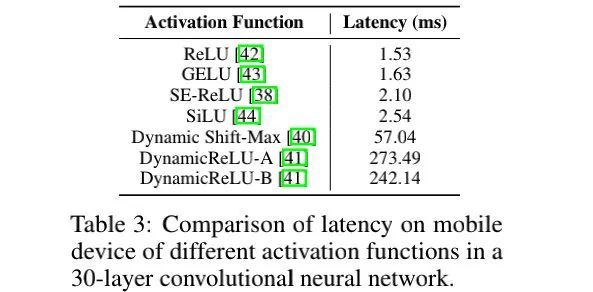
-
Activation Functions:上表对比了不同激活函数对于延迟的影响,可以看到:尽管具有相同的架构,但不同激活函数导致的延迟差异极大。本文默认选择ReLU激活函数。
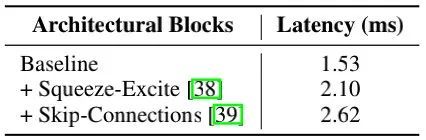
-
Architectural Block:上表对影响延迟的两个主要因素(访存消耗与计算并行度)进行了分析,见上表,可以看到:当采用单分支结构时,模型具有更快的速度。此外,为改善效率,作者在大模型配置方面有限的实用了SE模块。

基于上述分析,MobileOne的核心模块基于MobileNetV1而设计,同时吸收了重参数思想,得到上图所示的结构。注:这里的重参数机制还存在一个超参k用于控制重参数分支的数量(实验表明:对于小模型来说,该变种收益更大)。
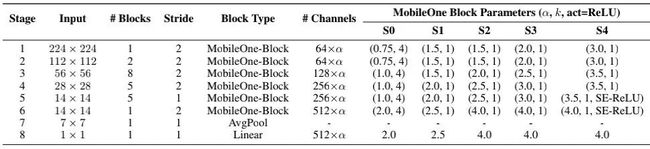
在Model Scaling方面类似MobileNetV2,上表给出了MobileOne不同配置的参数信息。

在训练优化方面,小模型需要更少的正则,因此作者提出了Annealing的正则调整机制(可带来0.5%指标提升);此外,作者还引入渐进式学习机制(可带来0.4%指标提升);最后,作者还采用EMA机制,最终MobileOne-S2模型达到了77.4%的指标。
实验结果

上表给出了ImageNet数据集上不同轻量型方案的性能与效率对比,可以看到:
-
哪怕最轻量的Transformer也需要至少4ms,而MobileOne-S4仅需1.86ms即可达到79.4%的精度;
-
相比EfficientNet-B0,MobileOne-S3不仅具有指标高1%,同时具有更快的推理速度;
-
相比其他方案,在PC-CPU端,MobileOne仍具有非常明显的优势。

上表为MS-COCO检测、VOC分割以及ADE20K分割任务上的性能对比,很明显:
-
在MC-COCO任务上,MobileOne-S4比MNASNet指标高27.8%,比MobileViT高6.1%;
-
在VOC分割任务上,所提方案比MobileViT高1.3%,比MobileNetV2高5.8%;
-
在ADE20K任务上,所提最佳方案比MobileNetV2高12%,而MobileOne-S1仍比MobileNetV2高2.9%。

在文章最后,作者俏皮的提了一句:"Although, our models are state-of-the art within the regime of efficient architectures, the accuracy lags large models ConvNeXt and Swin Transformer"。笔者想说的是:看上图。