Pytorch深度学习入门笔记1(Pycharm版)
Pytorch深度学习入门笔记1(Pycharm版,环境安装的坑,配置项目)
文章目录
- Pytorch深度学习入门笔记1(Pycharm版,环境安装的坑,配置项目)
-
-
- 环境需求与环境配置
-
- 需要的环境
- 环境配置和一些要注意的点
- Pytorch的初步认识
- dir()函数和help()函数
- 数据载入
-
- 常见的数据组成形式
- Dataset初步认识
-
- getitem
- 结语
- 结语
-
环境需求与环境配置
需要的环境
Pycharm(Pro) 版本不要太老,近两三年的就行
Anaconda3+Python(version = 3.9) 关于anaconda的安装有很多保姆级别的教程(教程传送门:https://blog.csdn.net/qq_45344586/article/details/124028689),或者自行搜索均可
Pytorch
CUDA11+
CUDNN
环境配置和一些要注意的点
进入Pytorch官网下载页面(传送门:https://pytorch.org/get-started/locally/),复制Run this Command中的指令到Pycharm终端或者系统的cmd里面即可开始下载(并不是像传统网站一样采用点击下载的方式);
如果电脑有GPU的建议安装CUDA+CuDNN,查看方法:任务管理器–性能,具体如下图:

关于CUDA+CuDNN的安装,网上也有写的很好很详细的教程,大体步骤跟着教程走就行(教程传送门:https://blog.csdn.net/dreamerzc/article/details/120599278),在这里说一些关于新版本pytorch要注意的坑:
-
网上很多教程都是教你安装CUDA10.2左右的版本的,如果是Windows系统下,新版Pytorch已经不支持GPU CUDA10版本了,因此我们需要下载CUDA11+的版本,否则等你辛辛苦苦下完CUDA10.2结果进pytorch网站的时候会发现这个:

-
CUDA的大版本都是在该版本内向下兼容的,比如你下了CUDA11.7,那么你Pytorch安装的时候尽管放心选择适配11.6版本的;但是如果你下载了CUDA11.3,Pytorch你就不要安装适配11.6版本的了,安装适配小于等于11.3的pytorch版本;
-
安装CUDA的时候注意跟着教程查看你的显卡跟你要下载的CUDA适配与否,这点很重要,不然可能会出大问题!!
-
建议在输入下载指令之前新建一个conda环境(指令:conda create -n 环境名称 python=3.x),以免出现一些pytorch附带的包版本冲突的问题;
如果电脑没有英伟达系列的GPU或者想用CPU来跑Pytorch的话,直接在Pytorch官网选择下载CPU版本即可(或者上网搜索pytorch清华镜像),CUDA+CUDNN就不用下载安装了;
Pytorch的初步认识
dir()函数和help()函数
这两个函数可以帮助你在使用Pytorch的过程中了解各个模块和每个模块的函数的用法和注意事项,属于是官方正规用法,非常方便;
用法:
-
打开pycharm的控制台(console),导入torch包(注意不是import pytorch而是import torch)之后输入dir(torch),可以看见pytorch内部的很多模块:

-
针对每个torch的模块,还可以使用dir函数再进行细分,就像文件夹中包含文件夹一样(以torch.sum为例):

-
我们再来看看help函数,输入help(sum):
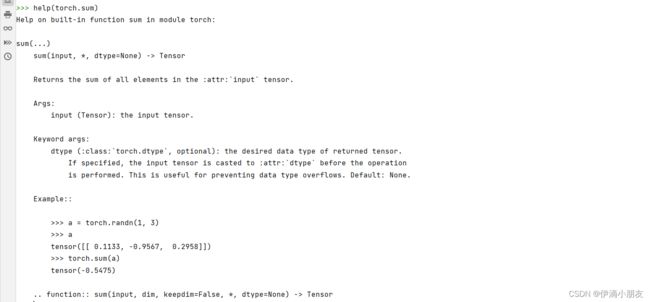
可以看到这里有非常详细的使用方法和样例。在python的学习中(不仅仅是pytorch),我们都可以使用这两个函数来帮助我们理解各个包、库、函数的用法,而不用去百度了;
数据载入
常见的数据组成形式
一般来说训练的数据都有数据本身和标签这两个要素;
- 第一种,label比较简单,比如只包含分类信息,那么可以直接以label来命名数据;
- 第二种,如果遇到一些NLP或者图像处理的数据,label可能会比较复杂,不方便直接命名,这时候可能是数据在一个文件夹中,label另存一个文件夹,每个label文件名跟数据的文件名对应
Dataset初步认识
现学现用,直接拿help函数来查看dataset的功能信息(觉得太过于复杂了不要紧,可以直接跳过这段代码往下看):
help(torch.utils.data.Dataset)
Help on class Dataset in module torch.utils.data.dataset:
class Dataset(typing.Generic)
| An abstract class representing a :class:`Dataset`.
|
| All datasets that represent a map from keys to data samples should subclass
| it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
| data sample for a given key. Subclasses could also optionally overwrite
| :meth:`__len__`, which is expected to return the size of the dataset by many
| :class:`~torch.utils.data.Sampler` implementations and the default options
| of :class:`~torch.utils.data.DataLoader`.
|
| .. note::
| :class:`~torch.utils.data.DataLoader` by default constructs a index
| sampler that yields integral indices. To make it work with a map-style
| dataset with non-integral indices/keys, a custom sampler must be provided.
|
| Method resolution order:
| Dataset
| typing.Generic
| builtins.object
|
| Methods defined here:
|
| __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]'
|
| __getitem__(self, index) -> +T_co
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __orig_bases__ = (typing.Generic[+T_co],)
|
| __parameters__ = (+T_co,)
|
| ----------------------------------------------------------------------
| Class methods inherited from typing.Generic:
|
| __class_getitem__(params) from builtins.type
|
| __init_subclass__(*args, **kwargs) from builtins.type
| This method is called when a class is subclassed.
|
| The default implementation does nothing. It may be
| overridden to extend subclasses.
这里面涉及到很多内置函数的用法,之后我会出一期专门的文章来详解这些函数方法,在这里我们首先介绍三个最常用的函数。
我们在创建数据集的时候,需要先针对dataset来建一个类,假设叫Mydataset;
三个常用函数(需要面向对象编程的基础):
- init初始化函数:初始化类,创建实例的时候就会运行这个函数,一般用来定义一些“全局”的变量等,类似CPP里面的构造函数;
- getitem函数:获取数据的信息(地址等),默认形式为def getitem(self, item),一般改成def getitem(self, idx);
- len函数:获取数据长度之类的信息;
getitem
这里需要提一下,getitem函数如果需要获取数据文件地址(比如图片地址),需要使用python的os操作系统库来将文件地址变成一个列表:
import os //使用os
dir_path = "文件夹路径,可以相对可以绝对,windows系统下需要注意斜线转义"
img_path_list = os.listdir(dir_path) //将文件夹中的所有图片变成列表
演示一下:
-
把一个图片(数据)文件夹拷贝至项目中
-
右键点击这个图片文件夹,选择复制路径,绝对、相对均可(一个简化操作的tip,省的跑去文件资源管理器那里复制);
-
在python控制台中输入代码(注意文件路径要么加双杠,要么在引号前加一个r,防止转义):[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

有了这个文件名数组,我们就可以通过数组index来轻松访问各个数据文件了,而getitem函数的第二个参数改成idx也是为了方便index访问才这样改的,养成良好的习惯最重要~
结语
本文主要记录了一下pytorch的环境安装和数据载入的一个大致过程,下篇文章会详细的将一个数据载入实例代码和讲解;
组,我们就可以通过数组index来轻松访问各个数据文件了,而getitem函数的第二个参数改成idx也是为了方便index访问才这样改的,养成良好的习惯最重要~
结语
本文主要记录了一下pytorch的环境安装和数据载入的一个大致过程,下篇文章会详细的将一个数据载入实例代码和讲解;
本文比较偏向萌新向,同时我也处在pytorch学习的过程中,如有疏漏,欢迎各位大佬补充指正~