ACL2016最佳论文:用于口语对话系统策略优化的在线自动奖励学习
用于口语对话系统策略优化的在线自动奖励学习
联合编译:陈圳,章敏,高斐
摘要
计算正确奖励函数的能力对于通过加强学习优化对话系统十分的关键。在现实世界的应用中,使用明确的用户反馈作为奖励信号往往是不可靠的,并且收集反馈花费也十分地高。但这一问题可以有所减轻,如果能提前知道用户的意图或是数据能预先训练任务离线的任务成功预测器。在实践中这两种都不太适合现实中的大多数应用。在这里我们提出了一个在线学习框架,通过带有高斯过程模式的主动学习,对话策略能按照奖励模式共同进行训练。高斯过程开发了一系列连续的空间对话表示,但都是在无监督的情况下使用递归神经网络编码和解码器完成的。试验结果表明所提出的框架能大量减少数据注释的花费以及减轻在对话策略学习中嘈杂使用者的反馈。
1. 介绍
口语对话系统(SDS)允许使用自然语言进行人机互动。他们大致可以分为两种类型:以闲聊为主的系统,其主要目标是与使用者进行交谈并提供合理的,符合上下文语境的回答;以任务为主的系统是主要任务是帮助使用者实现特定的目标(例如,发现酒店,电影或是公交时间表)。后者通常是根据设计本体结构(或是数据库),来决定系统可以谈论的领域。教会系统在以任务为主的SDS中如何正确地回答是一项重要的工作。这种对话管理往往是手动指定对话流程,这也直接决定了对话的质量。最近,对话管理能自动优化解决加强学习(RL)的问题。在这一框架中,系统学会由尝试或是错误过程所导致的潜在延迟学习目标,但这一般是由奖励函数决定的。

图1:以任务为主的对话实例,以及其提前规定的任务和结果评价。
在以任务为主的对话系统中,一个典型的方法就是决定奖励机制是运用一个小回合的惩罚机制来鼓励剪短对话,并在每一个成功互动后给予正面奖励。图1是任务型对话的实例,是专门为付费用户设置的对话系统。当用户启动完成特定任务,对话是否成功是由用户的主观反应的,或是基于特定任务是否完成的客观标准决定的。然而,在现实情况中使用者的目标一般不能提前得知,这也使得反馈评价方法变得不显示。
而且,目标的评级是不灵活,且从图1可以看出如果使用者并未严格按照任务流程,失败的几率十分的大。这样的结果是目标和主体的不匹配导致的。但是,仅仅依靠主观排序也是大有问题的,因为人群来源的主体经常会给出不准确的反应,而且人类也不愿意为给出反馈而扩展互动,导致学习不稳定。为过滤掉错误的用户反馈,Gasic等人使用仅仅使用主体和客体相等的对话。然而,在大多数现实任务中,这是低效,不可行的,因为使用者的目标通常是未知的并且难以推测。
基于以上所述,建议从离线模拟对话中学习神经网络目标估计。这将免去在线策略学习时进行目标检查的需要,使用obj=subj的检查能让其策略如同训练过一般的有效。但是,用户模拟器仅仅只能提供一个近似真实用户的数据,开发使用者模拟器是一个昂贵的过程。
为解决上述问题,本文描述了一种在线主动学习方法,在此过程中用户会被要求提供反馈,无论对话成功与否。但仅仅只有在反馈有效时,主动学习才会限制反馈的要求,而且噪声模式也被引入解释用户的错误反馈。高斯过程分类(GPC)模式利用鲁棒模式对嘈杂用户的反馈进行建模。因为GPC是在固定长度的观察空间运行的,但是其对话长度是可以变化的,一个以递归神经网络(RNN)为基础的嵌入函数时用于提供固定长度的对话表示。在本质上,所提出的方法学习对话策略和在线反馈模拟器,并直接适用于现实世界的应用。
本文余下内容安排如下。下一部分介绍相关工作。所提出的框架会在第3部分介绍。这包括策略学习算法,对话镶嵌函数的创造和按照用户排序的主动反馈模式。第4部分介绍所建议方法在英国剑桥餐馆信息背景下其评价结果。我们首先对对话镶嵌空间进行深入分析。当它与真实用户进行对话策略训练时,结果就会被呈现出来。最后,结论在第5部分。
2. 相关工作
自90年代以来,对话评估一直是一个活跃的研究领域,提出了PARADISE框架,在此框架任务完成的线性函数和各种各样的对话特征,例如对话时长,都会别=被用于推测用户满意度。这一测评方法会被用作学习对话策略的反馈函数。然而,需要指出的是,当与真实用户进行互动时,任务很少完成,关于模式理论准确性的问题也以提出。
在给定的注释对话语料库中,一些方法已经用于对话反馈模式的学习中。Yang等人使用协同过滤来推断使用者的偏好。奖励塑性的使用也进行了研究,为加速对话策略学习丰富反馈函数。同时,Ultes和Minker表明专家使用者的满意度和对话成功与否之间相关性很强。然而,所有这些方法假设可靠对话注释是可用的,例如专家排序,但是在实践中却是十分难得。减轻注释错误影响的一个有效方法是对相同数据进行多次排名,一些方法已经发展到用不确定的模式指导注释过程。当需要注释时,主动学习在决定时是相当有用的。在使用贝叶斯优化方法时,它经常被使用。在此基础上,Daniel等人利用pool-based主动学习方法用于机器人应用。他们要求使用者基于目前所收集的信息实例进行反馈,并显示出了这个方法的有效性。
不是明确地规定奖励函数,逆RL(IRL)旨在从良好的行为示范中恢复潜在的奖励,接着学习能最大限度回收奖励的策略。IRL是在SDS中第一次进行引进,在此过程中奖励是从人对人对话中推断出来的,并在语料库中模仿所观察到的行为。IRL也在Wizard-of-Oz设置中进行过研究;Rojas Barahona和Cerisara基于不同嘈杂等级的演讲理解输出,人类专家会充当对话管理者选择每一个系统。然而,这一方法十分的昂贵,并且没有理由假设一个人的表现最佳,尤其是在一个高噪音环境。
因为人类在给予相关评价方面比给予绝对评价方面表现更好,另一个相关研究主要集中在RL偏好的的方法。在Sugiyama等人的研究中,使用者会被要求在不同的对话中进行排序。但是,这一过程也十分的昂贵,并且没有良好的现实应用。
3. 提出的框架
所提出的框架在图2中有所描述。主要分为三个部分:对话策略,对话镶嵌函数和对于使用者反馈的主动奖励机制。当每一个对话结束时, 会从中提取一套水平化特征ft,并将其镶嵌入镶嵌函数σ得出维度固定的对话表示d,这一表示会作为奖励模式R的输入空间。这种奖励是仿照作为高斯的过程,每一个输入点对任务成功进行了评价,同时也对其不确定性进行了评估。基于这种不确定性,R会决定是否有必要询问用户的反馈。然后返回加强的信号来更新对话策略,其策略是通过GP-SARSA算法计算出来的。GP-SARSA同样也会运用高斯过程提供了一个在线实例有效性加强学习,利用最少数量的实例进行稀疏函数的评价推进。每一个对话的质量是由累积奖励决定的,每一个对话会产生一个负奖励(-1),最后奖励是0或是20是由奖励模式对任务完成度进行的评价决定的。
注意到关键是学习奖励模式的噪音鲁棒性,当使用者是监督者和会话策略能同时在线。主动学习并不是框架的重要组成部分,但是却能在实践中降低监督机制对于使用者的影响。提前训练镶嵌函数的使用时所提议方法的一个组成部分,并且是在语料库中进行离线训练而不是手动进行设计。
3.1 未受监督的对话镶嵌模式
为对对话长度不一样的用户反馈进行建模,镶嵌函数会将每一个函数进行固定空间维度定位。嵌入函数的使用在最近单词表示中获得了关注,并且提高了一些自然语言处理过程的表现。在机器翻译(MT)中也有成功地运用,它使用RNN解码和编码器对长短不一样的短语进行固定长度向量定位。与MT相似的是,对话镶嵌使得长短不一的话语能在固定长度向量上进行定位。尽管镶嵌在此处的运用是为GPC任务成功分类器创造维度固定的输出空间,但是值得指出的是这会潜在促进依赖分类和聚集的任务种类增加。
模式结构的嵌入函数如图2左边所示,片段水平ft是从对话中提取出来的,并作为输入特征进行编码。在我们所提出的模式中,解码器是双向长短期记忆网络(BLSTM)。LSTM是递归神经网络(RNN)的一个递归单元,是在解决和减轻梯度消失问题中引进的方法。两个方向的输入数据BLSTM解码器都将其序列信息考虑了进去,计算正向隐藏序列h1:T和反向隐藏序列hT:1,同时迭代所有的输入特征ft,t=1,...T:
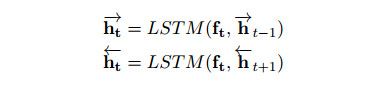
其中LSTM表示激活函数。然后对话表示d作为所有隐藏序列的平均值计算:
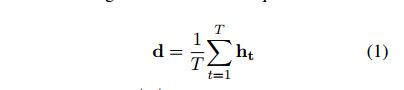
其中ht=[ht;ht]是两个双向隐藏序列的结合。
给定的对话表示d由编码器输出,解码器是向前的LSTM(每一次调整t产生调整序列f1:T时,将d作为输入)。
编码器-解码器的训练目标是最小化预测f`1:T和输出f1:T(同样作为输入)之间的均方误差:
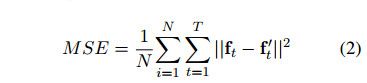
其中N是训练对话的数量,||·||2表示l2-norm。由于所有用于解码器和编码器中的函数是不一样的,随机梯度下降(SGD)可用于训练模型。
基于LSTM无监督嵌入函数产生的对话表示,随后被用于评论3.2节中介绍的奖励模型。
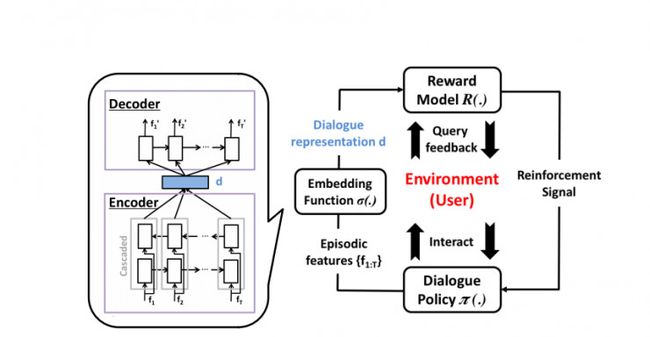
图:2:系统框架示意图。三大主要的系统组件:对话策略,对话嵌入创作,和基于用户反馈的奖励模型,如§3所描述。
3.2.主动奖励学习
高斯过程是一个可用于回归或分类的贝叶斯非参数模型。它特别有吸引力,因为它可以从一个小的观测值(利用一个内核函数定义的相关性)学习,它提供了评估的不确定性。
在口语对话系统的语境中,它已被成功用于RL策略优化和IRL奖励函数回归。
在这里,我们提出了和如高斯过程(GP)一样成功的建模对话。这涉及评估p(y|d,D)的概率(任务成功给出了当前对话表示d和包含以前分类对话的pool D)。我们将这伪装成一个分级问题,其中评估是二进制的评论y ∈ {−1, 1}——决定成功或失败。评论y是从有着成功概率p(y=1|d,D)的伯努利分布(Bernoulli distribution)中描绘出的。概率涉及一个潜在函数f(d|D):Rdim(d)→R,它由概率函数p(y=1|d,D)=Ø(f(d|D))映射到一个单元区间,其中Ø表示标准高斯分布的累积密度函数。
潜在函数在前面给定了一个GP:f(d)~gP(m(d),k(d,d’)),其中m(·)是平均函数,k(·,·)是协方差函数(kernel)。这使用了固定平方指数内核KSE。为了计算用户评估中的“噪音”,它还结合了一个白噪音核kWN:
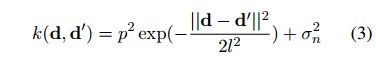
其中第一项为kSE,而第二项为kWN。
超参数p,l,σn可以使用基于梯度的方法最大化边缘似然进行充分优化。由于Ø(·)不是高斯分布,得到的后验概率p(y=1|d,D)难以分析。因此,并不是用近似方法,我们使用了期望传播(EP)。查询用户的反馈是昂贵的,并且可能会对用户体验产生负面影响。这种影响可以通过使用主动学习信息(通过GP模型的不确定性评估)方式减少。这确保了只有当模型不确定其目前的预测时,寻求用户反馈。对于目前的应用程序,需要一个联机(stream-based)版本的主动学习。
图3说明了1维度的例子。给定标记数据D,后验平均值μ*和在当前对话表示d*潜在的值f(d*)的后验方差σ2*可以被计算。然后一个阈值区间[ 1−λ,λ]设置在预测成功概率p()y*=1|d*,D)=Ø(μ*/根号1+σ2*)在,以决定对话是否一个被标记。决策边界隐式地考虑后验均值以及方差。
当在建议的框架部署这个奖励模型时,前面用于f有着0平均(zero-mean)的GP被初始化,且D={}。在对话策略π 完成与用户的片段后,使用对话嵌入函数σ,将生成的对话圈转化为对话表示d=σ(f1:T)。给定d,预测均值和f(d|D)的分差就被确定了,且奖励模型基于在Ø(f(d|D))的阈值λ决定是否需要寻求用户反馈。如果模型是不确定的,那么在当前片段d的用户反馈,用于更新GP模型,并产生增强信号来训练策略π;否则奖励模型的预测成功评估直接用于更新策略。每一次对话后都会进行该过程。

图片3:提出的GP主动奖励学习模型的1维度实例。
4.实验结果
目标应用程序是一个基于电话的口语对话系统,用于为剑桥(英国)地区提供餐厅信息。主要由150个场馆组成,每个有6个插槽(属性),其中3可由由系统使用来约束搜索(食物类型,范围和价格范围),剩余的3是信息性质(电话号码、地址和邮编)一旦需要的数据库实体已被发现便可使用。
SDS共享的核心组件和所有实验一样,包含一个基于HMM的识别器,一个混淆的语义网络(CNET)输入解码器,一个BUDS信念状态跟踪器(使用动态贝叶斯网络产生对话状态),和一个基于自然语言的模板——将系统语义行动描述成自然语言响应用户。
所有的策略都使用GP-SARSA算法进行训练,且RL策略的总结行动空间包括20个行动。给予每个对话的奖励设置成20×1success-N,其中N是对话匝数,并且1是对话成功的指标函数,它是由不同的方法决定如下所述。这些奖励构成了用于策略学习的加强策略。
4.1 对话表示
LSTM解码和编码模式在3.1部分有描述,它主要是用来对每一句对话生成一个镶嵌d。每一个对话都包含了使用者的话语和系统的回答,大小为74的特征向量被提取了出来。这个向量包括解码器决定的用户意图,由本体决定的利益观念分布,一个热门的系统回答编码,由最大化匝数所决定的匝数数量(这里是30)。这一特征向量是作为LSTM编码解码模式的输入和目标,其训练目标是减少MSE的重建函数的损失。
该模式使用了Theano 图书馆语料库进行试验。这一语料库包括8565,1199,650名真实用户在剑桥餐厅的对话,分别用于训练,检测和测试。这一语料库通过Amazon Mechanical Turk(AMT)服务进行收集,其受雇主体是通过对话系统进行交流。在反向传播中SGD的每一个对话都用于训练模式。为防止过度拟合,基于验证数据会进行早期阻止。
为将嵌入的嵌入的影响可视化,所有650个测试对话都会转变为嵌入函数,如图4,并且使用t-SNE减少二维嵌入功能。对于每一个对话样本来说,该形状暗示了对话成功与否,并且颜色还暗示了对话的长度(最长为30)。
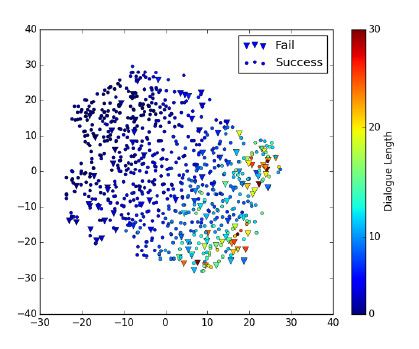
图4:剑桥餐厅内真实用户数据的无监督对话表示t-SNE可视化。标签是按照用户的主观评价进行排序。
从图中我们可以清楚地看到,从左上方(较短对话)到右下方(较长对话)的颜色梯度表示肯定的Subj标注。这表明在对话表征中,对话长度是其重要特征之一。同时也可以观察到,那些较长的失败对话(多余15轮)间隔距离不远,大多数居于右下方。另一方面,也有一些失败的对话是零散分布的。此外,成功的对话平均短于10轮,这一现象与以下观点一致:在经过良好训练的任务型系统中,用户并不能完全投入到较长的对话中。
这一清晰可见的结果表明了无监管式对话嵌入方式的潜在利用价值,由于经过改进的对话表征似乎与大多数成功的对话案例相关。根据GP奖励模型的目的,该LATM编码解码嵌入功能似乎有助于提取一种恰当的固定维度的对话表征。
4.2 对话策略学习
鉴于经过良好训练的对话嵌入功能,所提出的GP奖励模型将在该输入空间内运行。该系统在GPy图书馆得到实施(Hensman等,2012)。根据每一次新型可观察到的对话的成功可能性预测结果,不确定区域的阈值最初被设定为1,以鼓励用户询问注释,在第一组50次对话训练结束后,该阈值被将至0.85,随后便将该阈值设定为0.85。
最初,由于每一次新的对话都被增添入训练集合中,在Eqn中提到的用于定义核心结构的超参数得到优化,旨在将共轭梯度上边际可能性的负面结果将至最低。为避免出现过度拟合现象,经过训练第一组40次对话之后,将只针对每20次对话重新优化这些超参数。
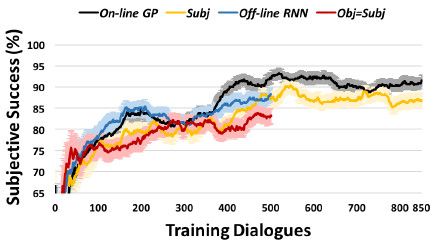
图5所示为在线策略优化过程中的学习曲线,该曲线表示主观成功为训练对话次数的函数。图中on-line GP,Subj, off-line RNN及Obj=Subj系统分别用黑色曲线,红色曲线,蓝色曲线和红色曲线表示。浅色区域表示一个标准差的时间间隔。
为了研究我们所提出的在线GP策略学习框架的性能,三种其他具有对比性系统的性能也都已经被检验。注意:手工系统未进入对比之列,由于其规模不能适用于更大的领域,且其对言语识别错误比较敏感。对于每一个系统,唯一存在的差异是用于计算奖励的方法的不同:
1. Obj=Subj系统利用对本任务的先前了解,仅仅使用训练对话的方式,在此过程中,用户对成功的主观评价与(Gasic等人,2013)的客观评价相一致。
2. Subj系统仅仅利用用户对成功的评价,直接优化策略,不论使用者的评价精准与否。
3. 线下RNN系统运用1K模拟数据和相匹配的Obj标签来训练RNN任务成功预测器(Su等,2015a)。
在运用Subj系统评估方法的过程中,为了只关注策略的性能,而非关注系统的其他方面,如所回复句子的流畅度,用户被要求回答一下问题:你已经找到所需要的所有信息了吗?,来预测对话成功与否。
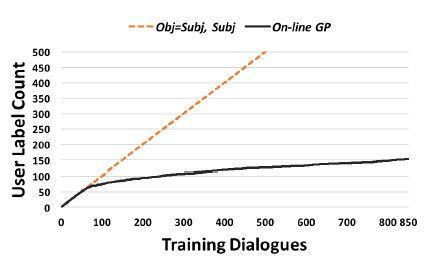
图6:在线策略优化过程中,每一个系统询问用户以获取反馈信息的次数是训练对话次数的函数。图中橙色线代表Obj=Subj,Subj系统,黑色曲线代表在线GP系统。
通过对由AMT服务终端正选的用户在线发起500次对话,来训练以上四种系统。图5所示为训练过程中,主观成功预测的在线学习曲线。对于每一个系统,均采用含有150次对话的窗口计算动态平均值。在训练每一个系统的过程中,均对三种不同的策略进行训练,对所得结果取平均值,以降低用户所提供的反馈信息的嘈杂度。
如我们所见,经过将近500次对话训练后,以上四种系统的性能优于80%的主观成功预测器的性能。其中,相对于其他系统来讲,Obj=Subj系统的性能较差。这可能是由于使用者依然预测对话结果为成功,尽管客观预测结果显示为对话失败。类似于这种情况,该对话将被舍弃,不用于训练。因此,为了获取500次有用的对话,Obj=Subj系统要求使用700次对话,然而,所有其他的学习系统则是高效率地运用每一次对话。
为了能够在较长时间内研究学习行为,训练在线GP系统和Subj系统所需要的对话次数被扩展到850次。如图所示,对这两种学习系统的训练结果呈平缓上升趋势。
与Gasic等人(2011)所得结果相似,Subj系统也会受到使用者不可靠的反馈信息的影响。首先,在训练Obj=Subj系统的过程中,用户将所有的任务要求均抛诸脑后,特别是忘记请求获得所有需要的信息。其次,由于对所提供的反馈信息的关注不够,用户提供的反馈信息呈现出不一致的现象。从图5中,我们能够清楚地观察到,在线GP系统的性能一直以来都优于Subj系统,出现这种现象可能是由于嘈杂模型抵冲了用户反馈信息不一致所造成的影响。当然,不像人群来源主体,真正的用户可能会提供更为一致的反馈信息,但是,偶尔出现非一致现象是不可避免的,并且嘈杂模型能够提供所需要的反馈信息的强健性。
在线GP系统在减少系统对用户反馈信息需求次数(即标签成本)方面的优点可以从图6中看到。黑色曲线显示为,在训练在线GP系统的过程中所需要的主观学习查询的次数,所显示的结果是经过对三种策略求平均值得出的。该系统仅需要询问获得150为用户的反馈信息便可训练得到一种强健的奖励模型。另一方面,如橙色虚线所示,Obj=Subj系统和Subj系统在训练每一次对话的过程中,均需要用户的反馈信息。
当然,当在线训练该系统时,线下RNN系统根本不需要用户的反馈信息,由于该系统具有运用用户模拟器的优势。然而,在训练过程中,当第一组300次对话训练结束后,该系统的性能不及在线GP系统。
4.3对对话策略进行评估
为了对比各种学习系统的性能,表格1的第一部分为400至500次对话的平均值和标准差。在训练400次对话和500次对话的间隔时间段内,Subj系统,线下RNN系统及在线GP系统的训练结果相当,并未表现出统计学上的差异。表1同时也显示了Subj系统和在线GP系统从500次对话到850次对话连续进行训练的结果。表1中的数据也表明在线GP系统具有显著的优越性,可能是由于与Subj系统相比,该系统对于有误的用户信息更为敏感。
4.4对奖励模型进行评估
上述结果证实了我们提出的奖励模型对策略学习的有效性。在本部分,我们将进一步研究该模型在预测主观成功率方面的精准度。表2为对在线GP奖励模型在1至850次对话训练过程中所得结果的评估。
由于每训练850次对话便可学习3种奖励模型,总计需要训练2550次对话。在这些对话训练过程中,这些模型总计需要询问获得用户反馈信息454次,剩余2096次对话训练则用于学习,而这种学习方式依赖于奖励模型的预测结果。表中所示结果为2096次对话训练的平均值。
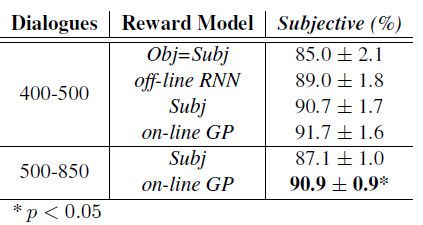
表1:不同在线策略学习阶段,对Obj=Subj系统,线下RNN系统,Subj系统及在线GP系统性能的主观评估结果。主观性:用户对对话成功与否的两分法预测。运用two-tailed学生t-test计算上述结果的统计学意义,其中p<0.05。
如我们可以观察到的,由于对话策略随着对话训练次数的增多而得到改善,对话成功标签与对话失败标签两者的比例呈现出不平衡的现象。由于该奖励模型更偏重使用肯定标签的数据,这将削弱使用者对失败对话预测的记忆。然而,其精确度也随之提高。另一方面,我们提出的奖励模型能够精确地预测对话的成功性。
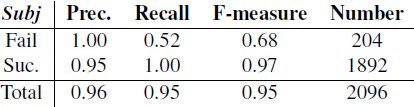
表2:关于Subj预测率的在线GP系统预测结果的统计学方面评估
4.5对话实例
与其他模型相比,在线GP奖励模型的主要优势在于其对用户反馈信息的嘈杂性的抵冲作用及对用户监管措施的有效利用。由于上述进行比较的四种系统仅在奖励模型的设计方面存在差异,其在线行为在很大程度上表现出相似性。
表3所列举的是用户与在线GP系统之间两个实例对话,旨在阐释该系统在不同的嘈杂条件下是如何运行的。表中也显示了用户的主观预测结果与由在线GP奖励模型生成的预测结果。标签‘n-th AS’与‘n-SEM’分别指代言语识别器和语义解码器所能产生的第n中做可能的假设。

表格3:在线用户与假定的在线GP系统之间的对话实例
5. 结论
在本文中,我们运用Gaussian过程分类法与一种基于神经网络的无监管式对话嵌入方法,提出了一种主动奖励学习模型,旨在实现口语对话系统中真正意义上的在线策略学习。该模型通过强健地模拟真实用户的反馈信息的内在嘈杂属性,能够达到稳定的策略优化效果,并且运用主动学习方法最大限度地减少对用户反馈信息的询问次数。我们发现,与其他state-of-the-art方法相比,所提出的模型能够有效地学习策略,而且具有更高的性能。该Bayesian模型的主要优势在于其不确定性评估结果能够使学习与噪音处理以一种自然的方式进行。这种无监管式对话嵌入功能在训练过程中不需要有标注的数据,却能够为奖励预测器提供一种经过压缩处理且有用的输入信息。整体上来讲,本文中研发的这些技术首次为真实世界中的对话系统提供了一种切实可行的在线学习方法,这种在线学习方法并不需要由人工标注的数据构成的大语料库,也不需要构建一个用户模拟器。
与我们之前的工作结果相一致,本文研究的奖励功能主要聚焦于任务的成功与否。这一奖励模型在商业应用方面可能会显得过于简单,在今后研究工作中,我们将会与人类交互专家一同识别并囊括对话品质的其他维度的信息,这些信息将满足更高水平的用户需求。
哈尔滨工业大学李衍杰副教授的点评:通过加强学习方法来优化对话管理策略是一种非常有效的方法,但精确的奖赏函数对于优化结果的好坏是十分关键的。这篇文章运用Gaussian过程分类法与一种基于神经网络的无监管式对话嵌入方法,提出了一种主动的奖赏函数学习模型,也就是当发现系统对用户的信息不确定时,通过主动询问的方式收集更多的信息来得到精确的奖赏函数,从而实现了口语对话系统中真正意义上的在线策略学习。该系统通过鲁棒地建模真实用户反馈中的内在噪声,能够实现稳定的策略优化,并且运用主动学习方法来最小化用户反馈询问的次数,有助于增强用户的体验感。与其他现有方法相比,该论文所提出的模型能够有效地学习对话策略,而且具有更高的性能。
本文作者:章敏
本文转自雷锋网禁止二次转载,原文链接