数据工程指南:初学者入门
别人经常问我,如何成为一名优秀的数据工程师?
你会在这份指南中找到答案。
如果你正在寻找人工智能算法或类似的学习资料,这些内容不适合你。
如何使用这份指南:这本书是你的起点,而不是训练!我想帮助您确定要研究的主题,并在此过程中成为一名出色的数据工程师。
我会介绍数据科学平台每个关键领域的工具(连接、缓冲区、处理框架、存储、可视化),选择一些你感兴趣的工具,研究并使用它们。
原文来源于Github开源项目《The Data Engineering Cookback》
作者:Andreas Kretz
感兴趣可以查看:Data Engineering Cookbook
数据工程师 vs 数据科学家
数据工程师
数据工程师负责搭建数据平台,然后数据科学家利用数据构建模型。
数据平台通常有5种使用方式:
- 提取并存储大量数据
- 数据科学家利用数据创建机器学习模型
- 数据科学家在生产环境部署模型
- 向员工和客户提供可视化产品
- 大多数时候人们会从搭建传统的系统架构开始,涉及到SQL数据库、web服务器、SAP和其它“标准”系统。
但要创建大数据平台,工程师必须是一名专业人士,负责检查、设置和维护大数据技术,例如:Hadoop、Spark、HBase、Cassandra、MongoDB、Kafka、Redis等等。他们还需要知道如何在云计算平台部署系统,比如在AWS、GCP或者Azure。
数据科学家
数据科学家与其他科学家不同。
数据科学家不穿白大褂,也不在充满科幻色彩的高科技实验室工作,他们和你我一样在办公室工作。
不同之处在于他们精通数学,他们使用线性代数和多元微积分从现有数据中创造新的见解。
这一见解究竟如何?
下面是一个例子:
许多工业产品需要在装运前进行测试。
通常这样的测试需要很长时间,因为要测试的东西有数百种,所有这些都是为了确保你的产品没有损坏。
如果一个测试在十步后失败了,早点知道岂不更好?若能够预见到这一点,就可以跳过后续的所有测试,直接开始修复产品或扔掉它。
这正是数据科学家可以帮助你的地方,这个领域被称为预测分析,选择的技术是机器学习。
机器可以学习?
是的,机器学习的工作原理是:向算法提供测量数据,它生成一个模型,该模型代表了数据中隐藏的模式。向模型展示新数据,模型将告诉你预测结果。毫无疑问机器学习可以用于预测机器故障,当然整个过程并不是那么简单。
训练和应用模型并不是那么困难,数据科学家将用大量时间用于数据预处理。
为了训练算法,你需要有用的数据。如果使用低质量的数据进行训练,生成的模型将非常不可靠。
一个不可靠的预测机器故障的模型会告诉你机器已经损坏,即便它能正常工作,更糟糕的是,它有可能将有故障的机器错分类为正常运行。
模型输出很抽象,有时候还需要对输出进行转化,才能得到你想要的结果。
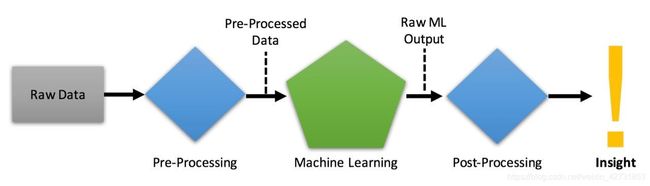
机器学习工作流
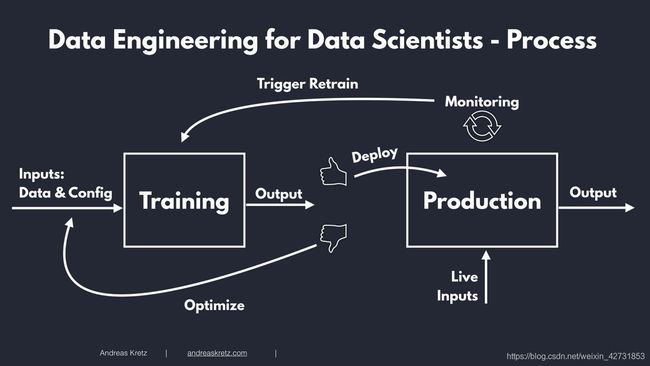
数据科学家和数据工程师,如何协同工作?
具体得看数据科学的过程,例如数据是如何生成的,训练模型需要哪些特征,预测目标是什么等等。
机器学习的过程通常从训练阶段开始,在这个阶段,你基本上是训练算法以获得正确的输出。
在学习阶段,要选择输入参数,即模型的配置和输入数据。
你要做的是训练算法。在训练过程中,算法修改训练参数,它还会修改使用的数据,然后您就可以得到一个输出。
一旦得到了输出结果,就要开始评估,例如输出是否正常,与预期相比相差多少?
如果评估结果不符合要求,就要回归到训练阶段,对模型进行几百次,几千次,几十万次的再训练。当然,所有这些都是自动完成的。
当你对模型的预测能力感到满意,就可以将模型投入生产环境。
在生产环境中,模型不再使用训练阶段的数据,而是要使用实时数据。
它实时评估输入数据并输出实时结果。
从研究过渡到生产,部署完毕后下一步呢?
你要做的就是监控输出,如果结果继续符合预期且令人满意,就没有问题!如果模型的输出发生了变化,并且它的运行时间超出了预期,则意味着要停止这个模型。你需要重新训练模型直到可以再次投入生产为止。
这就是机器学习的整个过程。
机器学习模型与数据

仔细分析发现,有两个非常重要的地方需要数据。
在训练阶段有两种类型的数据:1. 训练模型的数据集(特征/目标变量);2. 模型配置:超参数。
在生产阶段要获得实时数据,这些数据可以从不同的途径获得,例如App,物联网设备,日志等等。
数据目录也很重要,它解释了哪些特征可用,以及如何标记不同的数据集。
现在,工程部分来了,数据工程师负责提供机器学习过程所需要的一切数据。
首先要想办法存储模型的超参数,在生产阶段需要使用。
关于训练数据,涉及到几个关键问题:
从哪里获取数据?谁拥有它?原始数据是怎么样的?你是否会修改数据?依据是什么?
训练阶段和生产环境都需要以某种方式访问数据。
在生产环境中,你需要访问实时数据。
首先,数据工程师需要构建平台。
然后数据工程师需要构建数据管道(data pipelines),包括如何获取数据,如何存储数据,如何令其他人访问数据等等。如果数据需要清洗和预处理,也必须这么做。
一旦数据和系统可用,就到数据科学家登场了。
总之,数据工程是数据科学项目中至关重要的部分。
我的数据科学平台蓝图
我创建了一个简单和模块化的大数据平台蓝图,这是基于我在这个领域多年研究和实践得到的经验总结。
我相信它会对你非常有用。
因为,与其他蓝图不同的是,它不专注于技术。
按照我的蓝图,你可以创建一个完全符合你需求的大数据平台。
它将使帮助你完美地处理大数据,并允许你做数据驱动的商业决策。
蓝图包含5个关键部分:连接(Connection)、缓冲(Buffer)、处理框架(Processing Frameworks)、存储(Storage)和可视化(Visualization)。

将平台拆分成一个具有松散耦合接口的模块化平台。
为什么一个模块化的平台如此重要?
如果平台是非模块化的,你最终会得到一些固定的或难以修改的东西,这意味着你无法根据不断变化的需求调整平台。
由于模块化,你可以根据项目需求选择工具,还可以在必要的时候更换工具。
现在,让我们详细谈谈每个关键领域。
连接
首先需要从数据源提取数据,供后期使用。数据源可以是物联网设备,推文,服务器日志等等。
一般情况下,我们把实时数据先推送到临时存储器中。
临时存储允许其他阶段简单和快速地访问数据。
一个很好的解决方案是使用消息队列系统,如apache kafka、RabbitMQ或AWS Kinesis,有时候也会使用redis等轻量级应用。
临时存储最好要遵循发布/订阅模式(publish/subscribe)。通过这种方式,数据存储和消费都变得非常简单。
缓冲器
在缓存数据阶段,使用发布/订阅系统,比如apachekafka、Redis,或者其他云工具,比如Google pub/sub或AWS Kinesis。
把信息放在一个或多个队列里。
缓冲区背后的思想是为传入的数据建立一个中间系统。
它的工作原理是,从数据源获取数据,发布到消息队列中,数据“缓存”在这里直到被其它程序消费。
如果没有缓冲区,直接将数据写入存储库可能会遇到问题,因为总会遇到一些数据峰值,导致系统宕机。
比如说,现在是午休时间,你的App的使用量突然大增,产生了更多的数据,以至于超过了系统的存储处理能力。
有了缓冲区,你就可以缓冲传入的数据。存储和分析过程取出尽可能多的数据,不会对整个系统构成太大的性能压力。
缓冲区对于构建数据管道也非常有用。
例如你可以从kafka先取出数据,进行预处理再放回kafka,然后通过另一个程序将清洗后的数据取出并放入数据库。
处理框架
分析阶段是进行实际分析的地方,有两种方式:批处理(batch processing)和流处理(stream processing)。
流数据(streaming data)是实时产生的数据,系统可以从缓冲区提取数据,分析并快速产生结果。这种方式称为流处理。
有时候需要从存储库批量提取数据,分析并产生结果,这种方式称为批处理。
不管是批处理还是流处理,分析过程都不是一个单向的过程,分析产生的结果也可以写入存储库。
常情况下,将数据写回存储库是有意义的,它允许你将以前的分析结果与原始数据相结合。当你把数据组合起来时,有可能得到更多深刻的见解。
有各种各样的分析工具,例如MapReduce,AWS Elastic MapReduce,Apache Spark和AWS lambda。
存储
你需要存储所有数据,这将为预测模型提供强大的数据基础。
大部分的数据看来似乎毫无用处,但保存这些数据很重要。扔掉数据是个大禁忌。
为什么不扔掉没用的东西呢?
虽然现在看来可能没什么用,但数据科学家可以处理数据,他们会找到分析数据的新方法,并产生有价值的见解。
什么样的系统可以用来存储大数据?
像hadoop hdfs、Hbase、amazon s3或DynamoDB这样的系统非常适合存储大数据。
可视化
展示数据与获取、存储和分析数据一样重要,数据可视化令用户能够做出数据驱动的决策。
你不太可能构建出令所有人满意的完美UI,在这种情况下,你应该让其他人根据自己的需求创建UI。
怎么做?通过创建API(应用程序接口),并允许其它开发人员访问数据。
无论是UI还是API,关键在于让用户有能力访问数据仓库的数据。
就业前景
对于一家公司来说,拥有训练有素的数据工程师和数据科学家非常重要。
把数据科学家想象成一个专业的赛车手,他们有天赋和技能。然而要赢得比赛,还必须有一个提供完美赛车的人,设计和制造赛车的正是数据工程师。
就像赛车手和赛车工程师一样,数据科学家和数据工程师需要密切合作,他们需要彻底了解不同的大数据工具。
这就是为什么很多企业都在寻找有Spark经验的人,Spark是数据工程师和数据科学家推动创新的共同点。
Spark为数据科学家提供了进行分析的工具,并帮助工程师将算法投入生产。毕竟,这两个因素决定了数据平台有多好、分析洞察力有多强以及整个系统进入生产环境的速度有多快。
你们的点赞和收藏是我们最大的创作动力,我们每天都会为大家带来数据科学和量化交易领域的精品内容。
蜂鸟数据:开源金融数据接口,一个API连接世界金融市场。
蜂鸟数据团队由业界顶尖的数据工程师,数据科学家和宽客组成,我们正努力构建一个开源的金融数据库,并提供API接口,目标是令金融数据开源化和平民化。
浏览并测试我们接口吧,目前覆盖股票,外汇,商品期货,数字货币和宏观经济领域,包括实时报价(tick)和历史数据(分钟),提供REST API和Websocket两种接入方式,能够满足金融分析师,量化交易和理财app的需求。
蜂鸟数据API接口文档
登录蜂鸟官网,注册免费获取API密钥