深度学习(三十七)——CenterNet, Anchor-Free, NN Quantization
CenterNet
CenterNet是中科院、牛津、Huawei Noah’s Ark Lab的一个联合团队的作品。(2019.4)
论文:
《CenterNet: Keypoint Triplets for Object Detection》
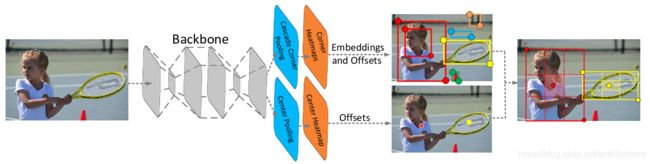
上图是CenterNet的网络结构图。
正如之前提到的,框对于物体来说不是一个最好的表示。同理,Corner也不是什么特别好的表示:绝大多数情况下,Corner同样是远离物体的。
也正是由于Corner和物体的关联度不大,CornerNet才发明了corner pooling操作,用以提取Corner。
但是即使这样,由于没有anchor的限制,使得任意两个角点都可以组成一个目标框,这就对判断两个角点是否属于同一物体的算法要求很高,一但准确度差一点,就会产生很多错误目标框。
有鉴于此,CenterNet除了Corner之外,还添加了Center的预测分支,也就是上图中的center pooling+center heatmap。这主要基于以下假设:如果目标框是准确的,那么在其中心区域能够检测到目标中心点的概率就会很高,反之亦然。
因此,首先利用左上和右下两个角点生成初始目标框,对每个预测框定义一个中心区域,然后判断每个目标框的中心区域是否含有中心点,若有则保留该目标框,若无则删除该目标框。
为了和CornerNet做比较,CenterNet同样使用了Hourglass Network作为骨干网络。并针对中心点和角点的提取,提出了Center pooling和Cascade corner pooling操作。这里不再赘述。
参考:
https://mp.weixin.qq.com/s/wWqdjsJ6U86lML0rSohz4A
CenterNet:将目标视为点
https://zhuanlan.zhihu.com/p/62789701
中科院牛津华为诺亚提出CenterNet,one-stage detector可达47AP,已开源!
https://mp.weixin.qq.com/s/CEcN5Aljvs7AyOLPRFjUaw
真Anchor Free目标检测----CenterNet详解
Anchor-Free
在前面的章节,我们已经简要的分析了Anchor Free和Anchor Base模型的差异,并介绍了两个Anchor-Free的模型——CornerNet和CenterNet。
这里对其他比较重要的Anchor-Free模型做一个简单介绍。
ExtremeNet
ExtremeNet是UT Austin的Xingyi Zhou的作品。(2019.1)
论文:
《Bottom-up Object Detection by Grouping Extreme and Center Points》
代码:
https://github.com/xingyizhou/ExtremeNet
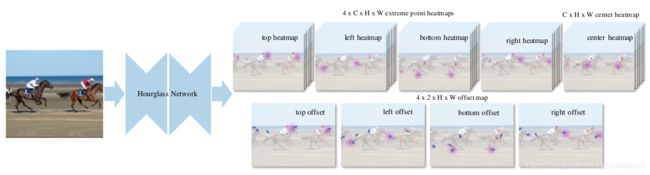
上图是ExtremeNet的网络结构图。它预测是关键点就不光是角点和中心点了,事实上它预测了9个点。具体的方法和CenterNet类似,也是heatmap抽取关键点。
显然,这类关键点算法是受到人脸/姿态关键点算法的启发,因此它们采用Hourglass Network作为骨干网络也就顺理成章了,后者正是比较经典的关键点算法模型之一。
FoveaBox
论文:
《FoveaBox: Beyond Anchor-based Object Detector》
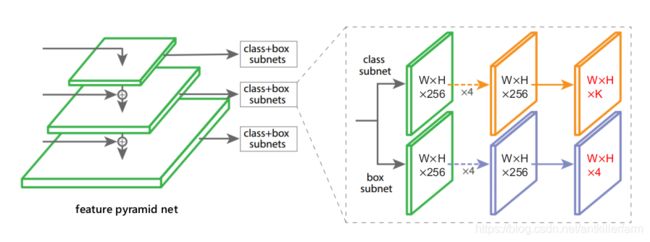
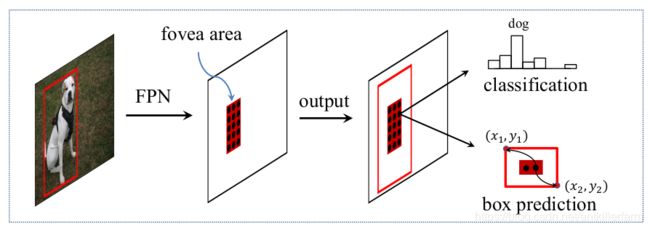
上两图是FoveaBox的网络结构图。
它的主要思路是:直接学习目标存在的概率和目标框的坐标位置,其中包括预测类别相关的语义图和生成类别无关的候选目标框。
事实上这和YOLOv1的思路是一致的。但FoveaBox比YOLOv1精度高,主要在于FPN提供了多尺度的信息,而YOLOv1只有单尺度的信息。
此外,Focal loss也是Anchor-Free模型的常用手段。
总结
Anchor-Free模型主要是为了解决Two-stage模型运算速度较慢的问题而提出的,因此它们绝大多数都是One-stage模型。从目前的效果来看,某些Anchor-Free模型其精度已经接近Two-stage模型,但运算速度相比YOLOv3等传统One-stage模型,仍有较大差距,尚无太大的实用优势(可以使用,但优势不大)。
其他比较知名的Anchor-Free模型还有:
- FCOS
《FCOS: Fully Convolutional One-Stage Object Detection》
- FSAF
《Feature Selective Anchor-Free Module》
- DenseBox
《DenseBox: Unifying Landmark Localization and Object Detection》
参考
https://zhuanlan.zhihu.com/p/63024247
锚框:Anchor box综述
https://mp.weixin.qq.com/s/dYV446meJXtCQVFrLzWV8A
目标检测中Anchor的认识及理解
https://mp.weixin.qq.com/s/WAx3Zazx9Pq7Lb3vKa510w
目标检测最新方向:推翻固有设置,不再一成不变Anchor
https://zhuanlan.zhihu.com/p/64563186
Anchor free深度学习的目标检测方法
https://mp.weixin.qq.com/s/DoN-vha1H-2lHhbFOaVS8w
FoveaBox:目标检测新纪元,无Anchor时代来临!
https://zhuanlan.zhihu.com/p/62198865
最新的Anchor-Free目标检测模型FCOS,现已开源!
https://mp.weixin.qq.com/s/N93TrVnUuvAgfcoHXevTHw
FCOS: 最新的one-stage逐像素目标检测算法
https://mp.weixin.qq.com/s/04h80ubIxjJbT9BxQy5FSw
目标检测:Anchor-Free时代
https://zhuanlan.zhihu.com/p/66156431
从Densebox到Dubox:更快、性能更优、更易部署的anchor-free目标检测
https://zhuanlan.zhihu.com/p/63273342
聊聊Anchor的"前世今生"(上)
https://zhuanlan.zhihu.com/p/68291859
聊聊Anchor的"前世今生"(下)
https://zhuanlan.zhihu.com/p/62372897
物体检测的轮回:anchor-based与anchor-free
https://mp.weixin.qq.com/s/m_PvEbq2QbTXNmj_gObKmQ
Anchor-free目标检测之ExtremeNet
NN Quantization
概述
NN的量化计算是近来NN计算优化的方向之一。相比于传统的浮点计算,整数计算无疑速度更快,而NN由于自身特性,对单点计算的精确度要求不高,且损失的精度还可以通过retrain的方式恢复大部分,因此通常的科学计算的硬件(没错就是指的GPU)并不太适合NN运算,尤其是NN Inference。
传统的GPU并不适合NN运算,因此Nvidia也好,还是其他GPU厂商也好,通常都在GPU中又集成了NN加速的硬件,因此虽然商品名还是叫做GPU,但是工作原理已经有别于传统的GPU了。
这方面的文章以Xilinx的白皮书较为经典:
https://china.xilinx.com/support/documentation/white_papers/c_wp486-deep-learning-int8.pdf
利用Xilinx器件的INT8优化开展深度学习
Distiller
https://nervanasystems.github.io/distiller/index.html
Intel AI Lab推出的Distiller是一个关于模型压缩、量化的工具包。这里是它的文档,总结了业界主要使用的各种方法。
参考:
https://mp.weixin.qq.com/s/A5ka8evElmcuHdowof7kww
Intel发布神经网络压缩库Distiller:快速利用前沿算法压缩PyTorch模型
Conservative vs. Aggressive
Quantization主要分为两大类:
1.“Conservative” Quantization。这里主要指不低于INT8精度的量化。
实践表明,由于NN训练时采用的凸优化算法,其最终结果一般仅是局部最优。因此,即便是两次训练(数据集、模型完全相同,样本训练顺序、参数初始值随机)之间的差异,通常也远大于FP64的精度。所以,一般而言,FP32对于模型训练已经完全够用了。
FP16相对于FP32,通常会有不到1%的精度损失。即使是不re-train的INT8,通常也只有3%~15%的精度损失。因此这类量化被归为"Conservative" Quantization。其特点是完全采用FP32的参数进行量化,或者在此基础上进行re-train。
1.“Aggressive” Quantization。这里指的是INT4或更低精度的量化。
这种量化由于过于激进,re-train也没啥大用,因此必须从头训练。而且由于INT4表达能力有限,模型结构也要进行一定的修改,比如增加每一层的filter的数量。
INT量化
论文:
《On the efficient representation and execution of deep acoustic models》
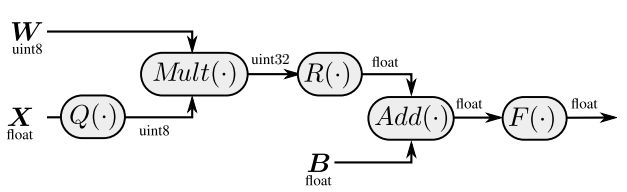
一个浮点数包括底数和指数两部分。将两者分开,就得到了一般的INT量化。
量化的过程一般如下:
1.使用一批样本进行推断,记录下每个layer的数值范围。
2.根据该范围进行量化。
量化的方法又分为两种:
1)直接使用浮点数表示中的指数。也就是所谓的fractional length,相当于2的整数幂。
2)使用更一般的scale来表示。这种方式的精度较高,但运算量稍大。
量化误差过大,一般可用以下方法减小:
1.按照每个channel的数值范围,分别量化。
2.分析weight、bias,找到异常值,并消除之。这些异常值通常是由于死去的神经元所导致的误差无法更新造成的。
如何确定每个layer的数值范围,实际上也有多种方法:
1.取整批样本在该layer的数值范围的并集,也就是所有最大(小)值的极值。
2.取所有最大(小)值的平均值。
UINT量化
论文:
《Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference》

UINT量化使用bias将数据搬移到均值为0的区间。
这篇论文的另一个贡献在于:原先的INT8量化是针对已经训练好的模型。而现在还可以在训练的时候就进行量化——前向计算进行量化,而反向的误差修正不做量化。
bfloat16
bfloat16是Google针对AI领域的特殊情况提出的浮点格式。目前已有Intel的AI processors和Google的TPU,提供对该格式的原生支持。

上图比较了bfloat16和IEEE fp32/fp16的差异。可以看出bfloat16有如下特点:
1.bfloat16可以直接截取float32的前16位得到,所以在float32和bfloat16之间进行转换时非常容易。
2.bfloat16的Dynamic Range比float16大,不容易下溢。这点在training阶段更为重要,梯度一般都挺小的,一旦下溢变成0,就传递不了了。
3.bfloat16既可以用于训练又可以用于推断。Amazon也证明Deep Speech模型使用BFloat的训练和推断的效果都足够好。Uint8在大部分情况下不能用于训练,只能用于推断。
论文:
《Mixed Precision Training》
参考:
https://www.zhihu.com/question/275682777
如何评价Google在TensorFlow中引入的bfloat16数据类型?
https://zhuanlan.zhihu.com/p/56114254
PAI自动混合精度训练—TensorCore硬件加速单元在阿里PAI平台落地应用实践
Saturate Quantization
上述各种量化方法都是在保证数值表示范围的情况下,尽可能提高fl或者scale。这种方法也叫做Non-saturation Quantization。
NVIDIA在如下文章中提出了一种新方法:
http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
8-bit Inference with TensorRT
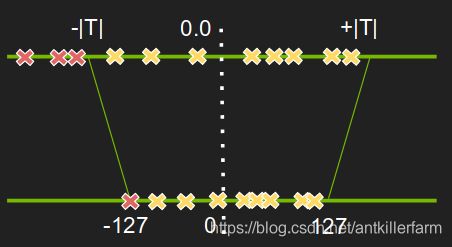
Saturate Quantization的做法是:将超出上限或下限的值,设置为上限值或下限值。
如何设置合理的Saturate threshold呢?
可以设置一组门限,然后计算每个门限的分布和原分布的相似度,即KL散度。然后选择最相似分布的门限即可。
量化技巧
1.设计模型时,需要对输入进行归一化,缩小输入值的值域范围,以减小量化带来的精度损失。
2.tensor中各分量的值域范围最好相近。这个的原理和第1条一致。比如YOLO的结果中,同时包含分类和bbox,而且分类的值域范围远大于bbox,导致量化效果不佳。
3.最好不要使用ReluN这样的激活函数,死的神经元太多。神经元一旦“死亡”,相应的权值就不再更新,而这些值往往不在正常范围内。
4.对于sigmoid、tanh这样的S形函数,其输入在 ∣ x ∣ > σ \mid x \mid > \sigma ∣x∣>σ范围的值,最终的结果都在sigmoid、tanh的上下限附近。因此,可以直接将这些x值量化为 σ \sigma σ。这里的 σ \sigma σ的取值,对于sigmoid来说是6,而对于tanh来说是3。
NN硬件的指标术语
MACC:multiply-accumulate,乘法累加。
FLOPS:Floating-point Operations Per Second,每秒所执行的浮点运算次数。
显然NN的INT8计算主要以MACC为单位。
gemmlowp
gemmlowp是Google提出的一个支持低精度数据的GEMM(General Matrix Multiply)库。
代码:
https://github.com/google/gemmlowp
论文
《Quantizing deep convolutional networks for efficient inference: A whitepaper》