【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
论文地址:
VLP:A Survey on Vision-Language Pre-training
A Survey of Vision-Language Pre-Trained Models
相关博客:
【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
一、简介
过去几年里,预训练模型在计算机视觉 (CV) \text{(CV)} (CV)和自然语言处理 (NLP) \text{(NLP)} (NLP)等单模态领域中取得了巨大的成功。大量的研究也表明其有助于下游的单模态任务。研究人员逐步尝试使用预训练模型来解决多模态问题。本文结合2篇综述文章,介绍了多模态预训练模型的最新进展。
二、特征抽取
1. 图像特征抽取
1.1 基于目标检测的区域特征
许多先前的 VLP \text{VLP} VLP工作利用预训练目标检测器来抽取视觉特征。最常使用的目标检测模型是具有bottom-up attention的Faster R-CNN。该模型被用来确定目标属于某个具体的类别,并使用bounding boxes来定位它们。通过使用Faster R-CNN, VLP \text{VLP} VLP模型能够获得一个图像中k个被选择区域的区域特征嵌入 V = [ o 1 , o 2 , . . . , o k ] V=[o_1,o_2,...,o_k] V=[o1,o2,...,ok]。每个区域特征 o i o_i oi都是一个具有bounding box的2048维Region-of-Interest(RoI)。其中bounding box由区域的左下角和右上角坐标来定义。 VLP \text{VLP} VLP使用bounding boxes构造一个5维向量,然后将这个向量嵌入成高维向量表示(2048维),称为visual geometry embedding。基于目标检测的区域特征是通过具有visual geometry embedding的目标检测区域嵌入获得的。虽然基于目标检测的特征带来了显著的改善,但是抽取区域特征十分的耗费时间。为了缓解这个问题,在预训练时目标检测器参数通常会被固定,这也限制了 VLP \text{VLP} VLP模型的能力。
1.2 基于CNN的网格特征
VLP \text{VLP} VLP模型会利用卷积神经网络来获得网格特征。一方面, VLP \text{VLP} VLP模型能够直接使用网格特征来端到端训练 CNNs \text{CNNs} CNNs。另一方面, VLP \text{VLP} VLP模型可以先使用一个可学习的视觉字典来离散化网格特征,然后将其输入至跨模态模块中。
1.3 基于ViT的Patch特征
受 ViT \text{ViT} ViT启发, VLP \text{VLP} VLP模型将图像 I i ∈ R H × W × C I_i\in\mathbb{R}^{H\times W\times C} Ii∈RH×W×C重塑为一个扁平的2D patches序列 I p ∈ R N × ( P 2 ⋅ C ) I_p\in \mathbb{R}^{N\times (P^2\cdot C)} Ip∈RN×(P2⋅C),其中 ( H , W ) (H,W) (H,W)是原始图像的分辨率, C C C是channels的数量, ( P , P ) (P,P) (P,P)是每个图像patch的分辨率,并且 N = H W / P 2 N=HW/P^2 N=HW/P2是最终的patches数量,其也作为输入 Transformer \text{Transformer} Transformer的有效输入序列长度。一个输入图像 I i I_i Ii被编码为嵌入序列: { v c l s , v 1 , … , v N } \{v_{cls},v_1,\dots,v_N\} {vcls,v1,…,vN},其中 v c l s v_{cls} vcls是[CLS]的嵌入向量。
2. 视频特征抽取
一段视频被表示为 M M M个帧。 VLP \text{VLP} VLP使用上面提及的方法来抽取帧的特征。两个最常被使用的特征是基于 CNN \text{CNN} CNN的网格特征和基于 ViT \text{ViT} ViT的patches特征。对于基于 CNN \text{CNN} CNN的网格特征, VLP \text{VLP} VLP模型首先会使用在 ImageNet \text{ImageNet} ImageNet上预训练的 ResNet \text{ResNet} ResNet和在 Kinetics \text{Kinetics} Kinetics上预训练的 SlowFast \text{SlowFast} SlowFast来为每个视频帧抽取2D和3D视觉特征。这些特征被拼接至视觉特征并输入至全链接层来将其投影至相同的低维向量空间,用于作为token embeddings。对于基于 ViT \text{ViT} ViT的patches特征,一段视频 V i ∈ R M × H × W × C V_i\in\mathbb{R}^{M\times H\times W\times C} Vi∈RM×H×W×C由 M M M个分辨率为 H × W H\times W H×W的帧组成,若 M = 1 M=1 M=1则是图像。遵循 ViT \text{ViT} ViT和 Timesformer \text{Timesformer} Timesformer的协议,输入视频片段被划分为 M × N M\times N M×N非覆盖尺寸为 P × P P\times P P×P时空patches,其中 N = H W / P 2 N=HW/P^2 N=HW/P2。
3. 文本特征抽取
对于文本特征则遵循 BERT \text{BERT} BERT, VLP \text{VLP} VLP模型首先将输入句子分段为子词序列。然后在序列的开始和结束位置插入特定的token来生成输入文本序列。通过对词嵌入、文本位置嵌入和文本类型嵌入求和得到文本的输入表示。
三、特征表示
为了充分利用单模态预训练模型, VLP \text{VLP} VLP模型将视觉或者文本特征送入 Transformer \text{Transformer} Transformer编码器。具体来说, VLP \text{VLP} VLP模型利用随机初始化的 Transformer \text{Transformer} Transformer编码器来生成视觉或者文本表示。此外, VLP \text{VLP} VLP模型能够利用预训练的 Transformer \text{Transformer} Transformer来编码基于 ViT \text{ViT} ViT的patch特征。 VLP \text{VLP} VLP模型能够使用预训练的文本 Transformer \text{Transformer} Transformer来编码文本特征,例如 BERT \text{BERT} BERT。
四、视觉语言交互
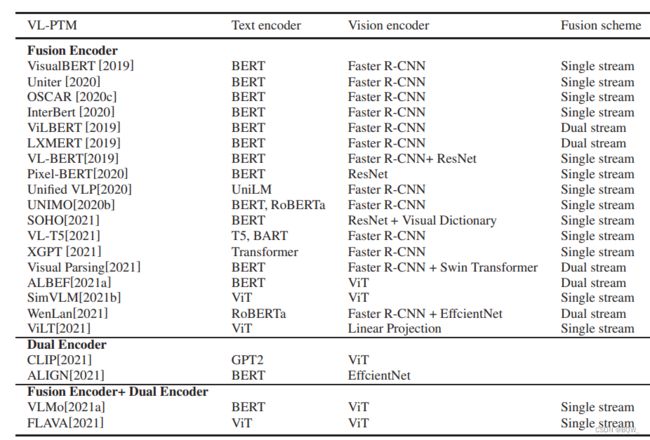
在将图像和文本编码至单模态嵌入中,下一步是要设计一个集成视觉和语言模态的编码器。基于不同的信息聚合方式,将编码器分类为fusion encoder、dual encoder以及两者的合并。
1. Fusion Encoder
fusion encoder将文本嵌入和图像特征作为输入,并使用一些融合方法来建模 V-L \text{V-L} V-L的交互。在经过自注意力和交叉注意力操作后,最后层的hidden states将会被当做是不同模态融合的表示。这里通常由两种方案来建模交叉模型的交互:single stream和dual stream。
1.1 Single-stream架构
single-stream会假设两个模态潜在的关系是简单的,其能够被一个单独的 Transformer \text{Transformer} Transformer编码器学习。因此,文本的特征和图像特征被拼接在一起,并添加特殊的embeddings来指示位置以及模态,并将其输入至基于 Transformer \text{Transformer} Transformer的编码器。
虽然不同的 V-L \text{V-L} V-L任务需要不同的输入形式,single-stream架构能够在统一的框架中处理它们,由于 Transformer \text{Transformer} Transformer注意力机制无序表示的本质。 VisualBERT \text{VisualBERT} VisualBERT和 V-L BERT \text{V-L BERT} V-L BERT使用segment embedding来指示不同模态的输入元素。相较于使用简单的image-text对, OSCAR \text{OSCAR} OSCAR从图像中添加了目标标签检测,并将image-text对表示为 ⟨ Word, Tag, Image ⟩ \langle \text{Word, Tag, Image} \rangle ⟨Word, Tag, Image⟩三元组来帮助fusion encoder更好的对齐不同的模态。由于single-stream架构直接在两个模态上执行自注意力机制,它们可能忽略了模态内的交互。因此,一些工作提出使用dual-stream架构来建模 V-L \text{V-L} V-L交互。
1.2 Dual-stream架构
不同于single-stream架构中的自注意力操作,dual-stream架构采用交叉注意力机制来建模 V-L \text{V-L} V-L交互,其中 query \text{query} query向量来自一个模态,而key和value向量来自另一个模态。一个交叉注意力层通常包含两个单向的交叉注意力子层:一个是从语言至视觉、另一个是从视觉到语言。它们负责两个模态间的信息抽取和语言对齐。
dual-stream架构假设模态内的交互和跨模态交互需要分离才能获得更好的多模态表示。 ViL-BERT \text{ViL-BERT} ViL-BERT使用两个 Transformers \text{Transformers} Transformers来进一步建模模态内交互。 LXMERT \text{LXMERT} LXMERT不使用额外的 Transformers \text{Transformers} Transformers,但是会在交叉注意力子层后加一个自注意力子层来进一步建立内部链接。在跨模态子层中,注意力模块的参数在两个stream中是共享的。在这种情况下,模型会学习单个函数来将图像和文本嵌入为向量。 ALBEF \text{ALBEF} ALBEF在交叉注意力之前为图像和文本使用分离的 Transformers \text{Transformers} Transformers,其能够更好的解构模态内交互和模态间交互。这种类型的架构有助于以更全面的方式来编码输入。但是另一方面,额外的特征编码器使得参数效率低下。
2. Dual Encoder
虽然fusion encoder能够在不同层面建模跨模态的交互,并在许多 V-L \text{V-L} V-L任务上取得state-of-the-art结果,其依赖一个大型的 Transformer \text{Transformer} Transformer网络俩建模 V-L \text{V-L} V-L交互。当执行Image-Text检索这样的跨模态匹配任务,fusion encoder必须联合编码所有的图像和文本对,其导致推断速度十分的慢。
作为对比,dual encoder使用单个模态的编码器来分别编码两个模态。然后,dual encoder采用采用浅注意力层或者点积等简单的方法来将图像嵌入和文本嵌入投影至相同的语义空间,用于计算 V-L \text{V-L} V-L相似分数。没有 Transformer \text{Transformer} Transformer中复杂的交叉注意力,在dual encoder中的 V-L \text{V-L} V-L交互建模策略更加的高效。因此,图像和文本的特征向量可以被预计算并存储,其相比于fuse encoder来对于检索任务更加的高效。虽然像 CLIP \text{CLIP} CLIP这样的dual encoder在image-text检索任务中展示了惊人的效果,但是在像 NLVR \text{NLVR} NLVR这样难的 V-L \text{V-L} V-L理解任务上效果并不好。这可能是由于两个模态间的浅层交互。
3. Fusion Encoder与Dual Encoder的合并
基于观察:fusion encoder在 V-L \text{V-L} V-L理解任务上的效果更好,而dual encoder则在检索任务上的效果更好。 FLAVA \text{FLAVA} FLAVA先采用dual encoder来获得单模态表示。然后,单模态嵌入被输入至fusion encoder来获得跨模态表示。抛开模型设计, FLAVA \text{FLAVA} FLAVA也执行了几个单模态预训练任务来改善单个模态表示的质量。 VLMo \text{VLMo} VLMo引入了 Mixture-of-Modality-Expert(MoME) \text{Mixture-of-Modality-Expert(MoME)} Mixture-of-Modality-Expert(MoME)并且统一dual encoder和fusion encoder在单个框架中。在对图像、文本和image-text对执行分阶段预训练后, VLMo \text{VLMo} VLMo不仅能在 V-L \text{V-L} V-L理解任务上微调,也能有效的用于image-text检索。
五、预训练目标
1. Masked Language Modeling
Masked language modeling(MLM) \text{Masked language modeling(MLM)} Masked language modeling(MLM),其被应用在 BERT \text{BERT} BERT上作为一个新颖的预训练任务从而被广泛得知。 VLP \text{VLP} VLP模型中的 MLM \text{MLM} MLM类似于预训练语言模型中的 MLM \text{MLM} MLM,但是预测被遮蔽的token时不仅使用余下的文本token,也使用视觉tokens。 VLP \text{VLP} VLP模型遵循 BERT \text{BERT} BERT的随机遮蔽策略。其形式定义如下:
L MLM = − E ( v , w ) ∼ D log P ( w m ∣ w ∖ m , v ) (1) \mathcal{L}_{\text{MLM}}=-\text{E}_{(\textbf{v},\textbf{w})\sim D}\text{log} P(\textbf{w}_m|\textbf{w}_{\setminus m}, \textbf{v}) \tag{1} LMLM=−E(v,w)∼DlogP(wm∣w∖m,v)(1)
其中, v \textbf{v} v表示视觉, w \textbf{w} w表示文本的token, w m \textbf{w}_m wm表示被遮蔽的文本token, w ∖ m \textbf{w}_{\setminus m} w∖m表示表示余下的文本token,并且 D D D表示训练数据集。
2. Prefix Language Modeling
Prefix Language Modeling(PrefixLM) \text{Prefix Language Modeling(PrefixLM)} Prefix Language Modeling(PrefixLM)统一了 masked language model \text{masked language model} masked language model和 language modeling \text{language modeling} language modeling。 PrefixLM \text{PrefixLM} PrefixLM用于使模型具有良好的生成能力,确保无需微调的文本诱导的zero-shot生成能力。 PrefixLM \text{PrefixLM} PrefixLM不同于标准的 LM \text{LM} LM,其能对前缀序列进行双向注意力并仅在余下的token执行自回归分解。在seq-to-seq框架下的 PrefixLM \text{PrefixLM} PrefixLM不仅能像 MLM \text{MLM} MLM那样享受双向上下文表示,也能像 LM \text{LM} LM那样执行文本生成。正式的定义如下:
L PrefixLM = − E ( v , w ) D log P ( w ≥ T p ∣ w ≤ T p , v ) (2) \mathcal{L}_{\text{PrefixLM}}=-\textbf{E}_{(\textbf{v},\textbf{w})~D}\text{log} P(\textbf{w}_{\geq T_p}|\textbf{w}_{\leq T_p},\textbf{v}) \tag{2} LPrefixLM=−E(v,w) DlogP(w≥Tp∣w≤Tp,v)(2)
其中, T p T_p Tp表示前缀的长度。
3. Masked Vision Modeling
类似于 MLM \text{MLM} MLM, masked vision modeling(MVM) \text{masked vision modeling(MVM)} masked vision modeling(MVM)采样图像的区域或者patches,并以15%的概率遮蔽这些视觉特征。 VLP \text{VLP} VLP模型需要通过余下的视觉特征和所有的文本特征来重构被遮蔽的视觉特征。被遮蔽的视觉特征被设置为0。由于视觉特征是高维且联系的, VLP \text{VLP} VLP模型提出了 MVM \text{MVM} MVM的两种变体。
3.1 Masked Features Regression
这种方式将遮蔽特征的模型输出回归到其原始视觉特征中。 VLP \text{VLP} VLP模型首先将遮蔽特征的模型输出转换为一个与原始视觉特征相同维度的向量,并在该特征向量与原始特征向量上执行 L2 \text{L2} L2回归。形式化的定义如下:
L MVM = E ( v , w ) ∼ D f ( v m ∣ v ∖ m , w ) (3) \mathcal{L}_{\text{MVM}}=\textbf{E}_{(\textbf{v},\textbf{w})\sim D} f(\textbf{v}_m|\textbf{v}_{\setminus m},\textbf{w}) \tag{3} LMVM=E(v,w)∼Df(vm∣v∖m,w)(3)
f ( v m ∣ v ∖ m , w ) = ∑ i = 1 K ∥ h ( v m i ) − O ( v m i ) ∥ 2 2 (4) f(\textbf{v}_m|\textbf{v}_{\setminus m},\textbf{w})=\sum_{i=1}^{K}\parallel h(\textbf{v}_m^i)-O(\textbf{v}_m^i) \parallel_2^2 \tag{4} f(vm∣v∖m,w)=i=1∑K∥h(vmi)−O(vmi)∥22(4)
其中, h ( v m i ) h(\textbf{v}_m^i) h(vmi)表示预测的视觉表示, O ( v m i ) O(\textbf{v}_m^i) O(vmi)表示原始的视觉表示。
3.2 Masked Feature Classification
这种方式会对遮蔽特征预测目标语言类别。 VLP \text{VLP} VLP模型首先会将遮蔽特征的输出再输入至全链接层来预测目标类别的分数,然后进一步利用softmax函数来转换出一个规范化的预测分布。需要注意的是,这里没有真实标签。这里有训练 VLP \text{VLP} VLP模型的两个关键的方法。一种方式是将目标检测模型输出的最可能类别作为硬标签,并假设遮蔽特征上检测到的类别是真实标签,然后应用交叉熵损失函数来最小化预测和伪标签的间隔。另一种方式是利用软标签作为监督信号,软标签是检测器的原始输出并且最小化两个分布的 KL \text{KL} KL散度。正式形式定义如下:
L MVM = E ( v , w ) ∼ D f ( v m ∣ v ∖ m , w ) (5) \mathcal{L}_{\text{MVM}}=\textbf{E}_{(\textbf{v},\textbf{w})\sim D}f(\textbf{v}_m|\textbf{v}_{\setminus m},\textbf{w}) \tag{5} LMVM=E(v,w)∼Df(vm∣v∖m,w)(5)
使用从 Faster R-CNN \text{Faster R-CNN} Faster R-CNN中获得的目标检测输出,并将遮蔽区域的目标检测类别作为标签:
f 1 ( v m ∣ v ∖ m , w ) = ∑ i = 1 K CE ( c ( v m i ) − g 1 ( v m i ) ) (6) f_1(\textbf{v}_m|\textbf{v}_{\setminus m}, \textbf{w})=\sum_{i=1}^K \text{CE}(c(\textbf{v}_m^i)-g_1(\textbf{v}_m^i)) \tag{6} f1(vm∣v∖m,w)=i=1∑KCE(c(vmi)−g1(vmi))(6)
其中, g 1 ( v m i ) g_1(\textbf{v}_m^i) g1(vmi)检测到的目标类别, K K K表示视觉区域的数量。
通过软标签的监督信号来避免假设,软标签是检测器的原始输出:
f 2 ( v m ∣ v ∖ m , w ) = ∑ i = 1 K D K L ( c ^ ( v m i ) − g 2 ( v m i ) ) (7) f_2(\textbf{v}_m|\textbf{v}_{\setminus m},\textbf{w})=\sum_{i=1}^K \text{D}_{KL}(\hat{c}(\textbf{v}_m^i)-g_2(\textbf{v}_m^i)) \tag{7} f2(vm∣v∖m,w)=i=1∑KDKL(c^(vmi)−g2(vmi))(7)
其中, g 1 ( v m i ) g_1(\textbf{v}_m^i) g1(vmi)检测到的目标类别分布。
4. Vision-Language Matching
Vision-Language Matching(VLM) \text{Vision-Language Matching(VLM)} Vision-Language Matching(VLM)是对齐视觉和语言最常使用的预训练目标函数。在single-stream VLP \text{VLP} VLP模型中,他们使用特定的 [CLS] \text{[CLS]} [CLS]表示作为两个模型的融合表示。在dual-stream VLP \text{VLP} VLP模型中,拼接特定的视觉表示 [ CLS V ] [\text{CLS}_V] [CLSV]和特定的文本表示 [ CLS T ] [\text{CLS}_T] [CLST]作为两种模态的融合表示。 VLP \text{VLP} VLP模型将两种模态的融合表示输入至全链接层和一个sigmoid函数来预测介于0到1的分数,其中0表示视觉和语言不匹配,并且1表示视觉和语言匹配。在训练过程中, VLP \text{VLP} VLP模型在每个step中从数据集采样正或负样本对。负样本对通过替换随机采样替换视觉或者文本来构造。
5. Vision-Language Contrastive Learning
Vision-Language Contrastive Learning(VLC) \text{Vision-Language Contrastive Learning(VLC)} Vision-Language Contrastive Learning(VLC)会从 N × N N\times N N×N个可能的视觉语言对中预测是否匹配,其中 N N N是给定的batch大小。需要注意,在一个训练batch中有 N 2 − N N^2-N N2−N个负视觉语言对。 VLP \text{VLP} VLP使用特定的 [ CLS V ] [\text{CLS}_V] [CLSV]表示视觉,并使用特定的 [ CLS T ] [\text{CLS}_T] [CLST]表示文本。 VLP \text{VLP} VLP模型会计算规范化softmax的视觉-文本相似度和文本视觉相似度,并利用交叉熵损失函数来进行更新。相似度通常是通过点积来实现,正式的形式如下:
p m v 2 t ( I ) = exp ( s ( I , T m ) / τ ) ∑ m = 1 M exp ( s ( I , T m ) / τ ) (8) p_m^{v2t}(I)=\frac{\text{exp}(s(I,T_m)/\tau)}{\sum_{m=1}^M\text{exp}(s(I,T_m)/\tau)} \tag{8} pmv2t(I)=∑m=1Mexp(s(I,Tm)/τ)exp(s(I,Tm)/τ)(8)
p m t 2 v ( T ) = exp ( s ( T , I m ) / τ ) ∑ m = 1 M exp ( s ( T , I m ) / τ ) (9) p_m^{t2v}(T)=\frac{\text{exp}(s(T,I_m)/\tau)}{\sum_{m=1}^M\text{exp}(s(T,I_m)/\tau)} \tag{9} pmt2v(T)=∑m=1Mexp(s(T,Im)/τ)exp(s(T,Im)/τ)(9)
L VLC = 1 2 E ( I , T ) ∼ D [ CE ( y v 2 t , p v 2 t ( I ) ) + CE ( y t 2 v , p t 2 v ( T ) ) ] (10) \mathcal{L}_{\text{VLC}}=\frac{1}{2}\text{E}_{(I,T)\sim D}[\text{CE}(y^{v2t},p^{v2t}(I))+\text{CE}(y^{t2v}, p^{t2v}(T))] \tag{10} LVLC=21E(I,T)∼D[CE(yv2t,pv2t(I))+CE(yt2v,pt2v(T))](10)
其中, I I I和 T T T分别表示图像和文本, s ( c o t ) s(cot) s(cot)表示相似度函数, τ \tau τ表示温度系数。 y v 2 t y^{v2t} yv2t和 y t 2 v y^{t2v} yt2v表示 vision2text \text{vision2text} vision2text检索的标签和 text2vision \text{text2vision} text2vision检索的标签。
6. Word-Region Alignment
Word-Region Aligment(WRA) \text{Word-Region Aligment(WRA)} Word-Region Aligment(WRA)是一种对齐视觉区域(或者patches)和单词的无监督预训练目标函数。 VLP \text{VLP} VLP模型利用最优运输来学习视觉和语言的对齐。由于精确的最小值计算会比较复杂,因此 VLP \text{VLP} VLP模型使用 IPOT \text{IPOT} IPOT算法来近似 OT \text{OT} OT距离。在求解完最小值后, OT \text{OT} OT距离会作为训练 VLP \text{VLP} VLP模型的 WRA \text{WRA} WRA损失函数。正式的形式如下:
L WRA = min T ∈ I I ( a,b ) ∑ i = 1 T ∑ j = 1 K T i j ⋅ c ( w i , v j ) (11) \mathcal{L}_{\text{WRA}}=\min_{T\in II(\textbf{a,b})}\sum_{i=1}^T\sum_{j=1}^K \text{T}_{ij}\cdot c(\textbf{w}_i,\textbf{v}_j) \tag{11} LWRA=T∈II(a,b)mini=1∑Tj=1∑KTij⋅c(wi,vj)(11)
其中, c ( w i , v j ) c(\textbf{w}_i,\textbf{v}_j) c(wi,vj)是评估 w i \textbf{w}_i wi和 v j \textbf{v}_j vj距离的代价函数, T ∈ I I ( a,b ) = { T ∈ R T × K ∣ T 1 m = a , T ⊤ 1 n = b } T\in II(\textbf{a,b})=\{T\in \mathbb{R}^{T\times K}|T1_m=\textbf{a},T^\top1_n=\textbf{b}\} T∈II(a,b)={T∈RT×K∣T1m=a,T⊤1n=b}, a \textbf{a} a和 b \textbf{b} b是以 w i \textbf{w}_i wi和 v j \textbf{v}_j vj为中心的狄拉克函数系数。
7. Frame Order Modeling
为了更好的建模视频的时间, VLP \text{VLP} VLP模型随机打乱一些输入帧的顺序,并且预测每个帧的实际位置。在实践中, Frame Order Modeling(FOM) \text{Frame Order Modeling(FOM)} Frame Order Modeling(FOM)被建模为一个分类任务。
8. Particular Pre-training Ojbects
VLP \text{VLP} VLP模型有时也会使用一些下游任务的训练目标,例如: visual question answering(VQA) \text{visual question answering(VQA)} visual question answering(VQA)和 visual captioning(VC) \text{visual captioning(VC)} visual captioning(VC)来作为预训练目标函数。对于 VQA \text{VQA} VQA, VLP \text{VLP} VLP模型会采用上面提及的融合表示,并应用全链接层,然后使用转换后的表示来对预定义答案候选进行分类。此外, VLP \text{VLP} VLP模型除了将任务建模为预定义候选答案的分类外,也能够以原始文本的形式直接生成答案。对于 VC \text{VC} VC,为了使 VLP \text{VLP} VLP模型具有生成能力需要重构输入句子, VLP \text{VLP} VLP模型利用一个自回归解码器来生成图像或者视频对应的文本描述。
六、预训练数据集
预训练数据集对于跨模态表示学习来说至关重要。预训练数据集的质量和尺寸有时会超过训练策略和算法的重要性。因此,对于广泛使用的预训练数据集进行详细描述是必要的。
因为 VLP \text{VLP} VLP包括image-language预训练和video-language预训练,因此将预训练数据集划分为两个主要类别。在后面的小节中会为每种类别提供具有代表性预训练数据集的更多细节。值得注意的是,无论预训练数据集属于哪种类别,在不同的研究中数据集的尺寸和来源都不同。在许多工作中, VLP \text{VLP} VLP预训练数据集通过合并不同任务或者场景中的公开数据集来构造。然而,像 VideoBERT \text{VideoBERT} VideoBERT、 ImageBERT \text{ImageBERT} ImageBERT和 ALIGN \text{ALIGN} ALIGN和 CLIP \text{CLIP} CLIP这样的工作则会在自己构建的数据集上执行预训练。这些自构数据通常要比公共数据集大且可能包含更多的噪音。
1. 用于 Image-language \text{Image-language} Image-language预训练的数据集
对于 image-language \text{image-language} image-language预训练,最广泛使用的数据形式是image-text对。大多数的image-language预训练数据集通常是由大量的image-caption对构成的。 SBU \text{SBU} SBU和 Flickr30k \text{Flickr30k} Flickr30k是从 Flickr \text{Flickr} Flickr收集的,并使用人工生成的标签进行标注。 COCO \text{COCO} COCO包含了许多具有5个人工生成caption的图片组成,然后经过特殊的程序进行过滤来保证图像和标注的质量。 CC3M \text{CC3M} CC3M和 CC12M \text{CC12M} CC12M是通过从互联网上爬取图像和alt-text属性来构造的。由于比较松散的过滤策略, CC12M \text{CC12M} CC12M包含的噪音要多于 CC3M \text{CC3M} CC3M。另一个数据源是视觉问答任务。许多image-language数据集会被组织成结构化数据。代表性的大规模数据集是 Visual Genome(VG) \text{Visual Genome(VG)} Visual Genome(VG)。 VG \text{VG} VG在其结构化数据形式中包含了丰富的信息。它的区域级描述和问答对在image-language预训练中被频繁的使用。除了 VG \text{VG} VG, VQA \text{VQA} VQA和 GQA \text{GQA} GQA也是视觉问答中流行的数据集。相比于 VQA \text{VQA} VQA, GQA \text{GQA} GQA进一步缓解了系统性偏差。
上面提及的数据集适用于大多数的应用和场景。这里也有一些用于特定cases设计的数据集。 Matterport3D \text{Matterport3D} Matterport3D是用 RGB-D \text{RGB-D} RGB-D图像组成的,使用标签进行分类和分段。 Fashion-Gen \text{Fashion-Gen} Fashion-Gen包含了由专业造型师生成的搭配物品描述的时尚图片。
2. 用于 Video-language \text{Video-language} Video-language预训练的数据集
相较于image-language预训练数据集,video-language预训练数据集通常更耗时,并且更难收集和处理。这些不便限制了社区和预训练规模的发展。video-language预训练数据集覆盖了不同的场景和来源。它们中的大部分,例如 Kinetics400 \text{Kinetics400} Kinetics400、 HowTo100M \text{HowTo100M} HowTo100M和 WebVid-2M \text{WebVid-2M} WebVid-2M是从互联网上收集并使用不同程序进行处理的。这些视频类型通常会包含字幕,器能够为视频片段和文本提供弱或者强的对齐。虽然这些字幕有时可能对于对齐不同模态来说太弱,但仍然提供了有用的信息,特别是在大规模数据集上预训练的。 TVQA \text{TVQA} TVQA是一个从电视节目生成的video-language预训练数据集。这些电视节目被收集,并且转换为由多个对话组成的数据集,用于理解视频并识别视频中的语义概念。
考虑到这些数据集的形成和来源的多样性,研究人工会应用不同的标注和处理程序。例如, Kinetics-400 \text{Kinetics-400} Kinetics-400是用许多由动作相关的视频组成,这些视频标注了动作的类别。
七、下游任务
1. 分类任务
1.1 Visual Question Answering(VQA)
给定一个视觉输入(图像或者视频), VQA \text{VQA} VQA表示能够为一个问题提供正确答案的任务。该任务通常会被当做一个分类任务,模型从候选池中预测出最适合的答案。为了获得准确的效果,根据提出的问题从图像中推断逻辑蕴含很重要。
1.2 Visual Reasoning and Compositional Question Answering(GQA)
GQA \text{GQA} GQA是 VQA \text{VQA} VQA的升级版本,目标是推进自然场景中视觉推理的研究。数据集中的图像、问题和答案具有匹配语义的表示。这种结构化表示的优点是,答案的分布更加的均匀,并且能够从更多的维度分析模型的表现。相比于传统 VQA \text{VQA} VQA的单个评估指标, GQA \text{GQA} GQA包括了多个维度的评估指标:consistency, validity, plausibility, distribution和grounding。
1.3 Video-Language Inference(VLI)
给定一个视频片段以及对齐的字幕,结合基于视频内容的自然语言假设,一个模型需要推断假设与给定视频片段为蕴含还是矛盾。
1.4 Visual Entailment(VE)
在 VE \text{VE} VE任务中,图像是premise,文本是hypothesis。其目标是预测文本是否蕴含图像,共包含三种标签:蕴含、中立和矛盾。
1.5 Visual Commonsense Reasoning(VCR)
VCR \text{VCR} VCR任务是机器看到图像时能够推断常识信息和认知理解的任务。对于基于图像提出的问题,这里有几个可选的答案。模型必须从几个答案中选择一个答案,然后从若干个可选理由中挑选一个为什么选择该答案的利用。这样, VCR \text{VCR} VCR能够被划分为两个任务,包含问答以及答案利用。
1.6 Natural Language for Visual Reasoning(NLVR)
NLVR \text{NLVR} NLVR是更加广泛 VCR \text{VCR} VCR类别的子任务,仅限于分类范式。 NLVR \text{NLVR} NLVR任务的输入是两个图像和一个文本描述,输出是两个图像间是否有关系,并且与文本的描述是否一致。由于其涉及到覆盖各种语言现象的长文本,所以其与 VQA \text{VQA} VQA具有显著的不同。
1.7 Grouding Referring Expressions(GRE)
GRE \text{GRE} GRE任务的目标给定一个引用表达式(referring expression)来定位图像中的具体区域,其主要挑战是理解和对齐视觉和文本领域的各种类型信息,例如视觉属性、定位以及与周边区域的交互。特别地,模型能够输出每个区域的分数,并且具有最高分的区域被用作预测区域。
1.8 Category Recognition(CR)
CR \text{CR} CR是指识别产品的类别和子类别,例如: { HOODIES, SWEATERS } \{\text{HOODIES, SWEATERS}\} {HOODIES, SWEATERS}和 { TROUSERS, PANTS } \{\text{TROUSERS, PANTS}\} {TROUSERS, PANTS},其是描述产品的重要属性,也被用于许多真实生活中的应用。
2. 回归任务
2.1 Multi-modal Sentiment Analysis(MSA)
MSA \text{MSA} MSA的目标是利用多模态信号来检测视频中的情感。它将预测一个语料的情感倾向作为一个连续稠密变量。
3. 检索任务
3.1 Vision-Language Retrieval(VLR)
VLR \text{VLR} VLR涉及到使用合适的匹配策略来同时理解视觉和语言领域。它包含两个子任务,vision-to-text和text-to-vision检索,其中vision-to-text检索是为每个图像从大规模的描述池中挑选出最相关的文本描述。 VLR \text{VLR} VLR被广泛的应用在领域相关搜索、多搜索引擎和基于上下文的视觉检索中。
4. 生成任务
4.1 Visual Captioning(VC)
VC \text{VC} VC的目标是,给定一个视觉输入,并为其生成语义和语法合适的文本描述。为视觉输入生成相关且可解释的captions不仅需要丰富的语言知识,也需要与视觉输入中出现的场景、实体以及交互相一致。
4.2 Novel Object Captioning at Scale(NoCaps)
NoCaps \text{NoCaps} NoCaps扩展了 VC \text{VC} VC任务来测试模型描述 Open Image \text{Open Image} Open Image数据集中新实体的能够,这些实体未在训练集中出现。
4.3 Visual Dialogue(VD)
VD \text{VD} VD的具体任务如下:给定一个图像、一个由一系列问答对构成的对话历史和一个后续的自然语言问题,任务的目标是以自由文本的形式回答这个问题。 VD \text{VD} VD是图灵测试的视觉模拟。
5. 其他任务
5.1 Multi-modal Machine Translation(MMT)
MMT \text{MMT} MMT是翻译和文本生成双重任务,基于从其他模态获得的额外信息来将文本从一种语言翻译为另一种。附加的视觉信息用于异常直接文本机器翻译中可能出现的歧义,并帮助保留文本描述的上下文。多模态表示空间有助于增强表示,补充视觉嵌入和语言嵌入中固有的语义信息。
5.2 Vision-Language Navigation(VLN)
VLN \text{VLN} VLN是一个基于语言指令的、在真实世界中基于动态所见和探索的代理定位的真实语言任务。类似于生成任务,其通常被视为sequence-to-sequence转码任务。然而, VLN \text{VLN} VLN具有独特性。其通常具有更长的序列且由于其是实时演化的任务,问题的动力学性质也非常不同。
5.3 Optical Character Recognition(OCR)
OCR \text{OCR} OCR通常是值从图像(例如路牌、产品照片)以及文档(账单、发票、财务报告等)中抽取手写或者打印文本,其包括两个部分:文本检测(类似于回归)和文本识别(类似于分类)。
此外,一些视频相关下游任务用来评估video-text预训练模型,包括: action classification(AC) \text{action classification(AC)} action classification(AC)、 action segmentation(AS) \text{action segmentation(AS)} action segmentation(AS)和 action step Localization(ASL) \text{action step Localization(ASL)} action step Localization(ASL)。