Kindling项目目标--利用eBPF技术带来的可观测性的上帝视角


| 转载自:Kindling云可观测
| 作者:苌程
| 编辑:钱睿
| 设计:马丽娜
开源工具Kindling旨在帮助用户更好更快的定界云原生系统问题,并致力于打造云原生全故障域的定界能力。本文将从当前云可观测领域存在的痛点角度来说明Kindling的价值。
当前可观测性工具在云原生环境缺失了什么?
大家在使用可观测性产品当中,海量的数据一定会给排障带来障碍。稍微有点排障经验的技术人员都希望排障过程中能够追寻trace,并能沿着这个trace将各种可观测性的数据关联到这个trace上,这样最终就可以将问题根因找到。在eBPF技术出现之前,大家最常用的trace就是dapper论文中提到分布式追踪技术,但是在实际落地过程中会经常碰到以下痛点:
痛点1
探针自动化覆盖依赖人工
APM探针安装需要人工安装,应用重启才能生效,所以很难做到自动化覆盖所有业务。导致云原生环境里某些节点并未安装APM探针或者人工插桩,所以无法顺着trace深入排查遇到阻碍。
痛点2
探针难以覆盖多语言的微服务业务
微服务的设计哲学中强调,每个小团队可以使用擅长的语言并针对需求做出自认最佳的开发,这就意味着开发语言是多样的。trace也会由于多语言的难以统一追踪而断掉。
痛点3
APM trace缺少内核可观测数据
DNS的性能导致业务抖动、Kmem 相关bug导致业务pod oom重启、业务pod出现请求另外一个pod请求不通、业务迭代产生网络消耗大引起业务性能下降问题、共享存储导致业务请求性能发生抖动、 kube-dns 配置出现异常导致业务异常等等问题都很难通过单一的APM trace数据进行排障。
另外一个常见的问题就是某段代码突然慢了,这段代码之前都是运行好的,单凭APM trace中采集的数据难以回答为什么突然慢了。这个时候多半需要人为介入,再从应用日志、系统日志找到内核可观测性数据去排查问题,比如找到当时srtt数据是否正常,某次文件读写时间和传输数据量、操作系统进程调度是否正常。
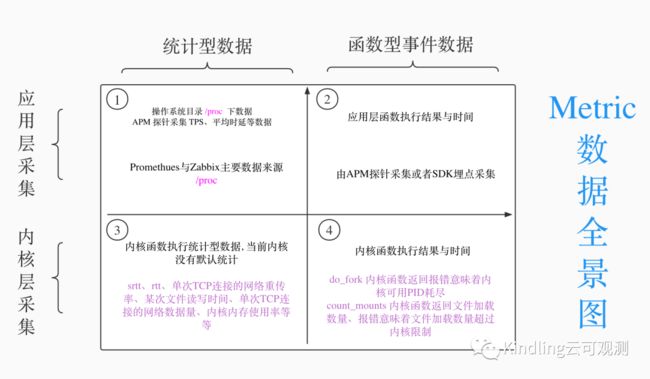
Metric数据全景图
1类型的Metric数据是Linux /proc下数据,Promethues和Zabbix等主流监控数据就来自于/proc 下的统计数据,APM探针也会有部分统计数据如TPS、平均时延、错误率等。
2类型的数据当前是APM产品主要采集的数据,该类型数据大量通过APM trace进行展示,并不是以常规指标形式展示,少部分数据以常规指标形式展示。
3类型的数据,当前该类型数据采集工具缺失,如BCC等工具是作为小工具临时使用,业界并未有监控工具将该部分数据作为可观测性数据7X24小时运行保存展示。
4类型的数据,当前主要还是专家型技术人员通过BCC、Bftrace、Ftrace等工具去获取内核函数执行情况。
Kindling基于eBPF技术构建的上帝视角带来了解决方案
关联内核可观测数据的trace
针对痛点1
当前业界的主要解决思路
当前业界的主要解决思路
有些公司推出了OneAgent概念,本质上利用脚本做自动化检测,自动化安装脚本,从而保证节点能够做到探针全覆盖。但是此种方式仍然需要人工干预决定业务何时才能重启,探针采集数据才能生效。
Kindling的解决思路
Kindling利用eBPF技术或者内核模块技术构建的探针,以DeamonSet工作在Node所在的Linux操作系统上,即可覆盖所有环境,不会出现没有探针覆盖的情况。另外非常重要的一点是应用无需重启,探针即可采集内核层的数据,对业务无干扰。为了能够支持当前国内主流的CentOS7系列(eBPF运行在该类型操作系统默认内核上有技术局限性),Kindling通过构建内核模块的技术获取了同样数据,保证用户在高版本内核上与低版本内核获得同样的体验。
针对痛点2
当前业界的主要解决思路
针对不同语言推出不同的APM agent,但是有些语言如Go和C语言很难做到自动化插裝,只能提供SDK包以便人工插裝。另外每个语言特性不一致,导致不同语言探针采集的数据集很难一致,对后端的整合分析带来更大的压力,用户体验也不一致。会出现某种语言有某些指标,而另外语言可能就缺失了这部分的指标。
Kindling的解决思路
eBPF代码或者内核模块代码工作在内核层与语言无关,所以程序无需做任何插裝或改动,也不用重启即可被观测,所有程序采集指标完全一致,用户理解不会有偏差。
针对痛点3
当前业界的主要解决思路
当前比较常见的做法是将prometheus的数据和APM trace进行关联,这种方案能解决应用层导致的问题,但是针对云原生环境很多问题如DNS的性能导致业务抖动,共享存储导致业务请求性能发生抖动,代码突然执行慢了等问题排障帮助有限。
针对3与4类型的metric数据,当前主流做法是利用BCC、BFTRACE、Ftrace、Systamp等与内核交互的工具采集数据并输出至console中展示,当前并未有能提供7x24小时运行的可观测方案。主要原因是3与4类型中很多种类数据的数据量是非常大的,而7x24小时运行过程中,绝大多数情况是数据是正常的,保存这些大量正常的数据是浪费存储资源。
Kindling的解决思路
Kindling构建全局拓扑图和排障trace来排查问题,排障trace有别于APM trace,eBPF排障trace只是APM trace中的一个如A->B调用环节。Kindling重点做的事情就是将3与4类型的数据关联至排障trace当中,通过判断排障trace是否异常,决定该trace的存储,从而实现存储友好的7x24小时运行云原生可观测性工具。
Kindling使用和BCC、Bftrace同样的原理从而得到应用运行环境中3类型与4类型数据,为了能够支持当前国内主流的CentOS7系列(eBPF运行在该类型操作系统默认内核上有技术局限性),Kindling通过构建内核模块的技术获取了同样数据,保证用户在高版本内核上与低版本内核获得同样的体验。
Kindling 通过分析在同一个socket fd上的read系统调用和wrtie系统调用即可得到应用在处理该socket上请求耗时,并将该次请求与返回封装成排障trace。通过耗时、返回码等业务层语义能够确定每次eBPF排障trace是否异常。在一个socket fd上的read系统调用总时间,可以得到一个请求上的网络request时间,分析一个socket fd上的write系统调用总时间,可以得到一个请求上的网络response时间。将一个socket fd上的最后一个read和第一个write时间差即是程序处理的总时间。将同一个socket fd上三者时间关联在一起看,即可看到请求的耗时的完整分布,得到类似chrome里面下图

Kindling 获取到的3类型数据与4类型数据通过各种关联手段关联至排障trace,在确定排障trace异常之时能存储该排障trace,同时也存储了3类型数据与4类型数据。该种方式确保了Kindling是可以运行在云原生环境的7X24小时存储友好的可观测性工具。
Kindling未来的发展思路与Roadmap
kindling未来希望在有全局拓扑图和排障trace的概念之上,不断丰富第3与第4类型的数据,能够帮助用户排障云原生上所有故障。
在丰富指标方面,主要遵循以下两个思路:
希望社区用户能够贡献更多的故障场景至太空舱项目https://github.com/Kindling-project/space-capsule,该项目致力于收集云原生上不同种类的故障,并通过混沌工程进行在一个demo中模拟各种种类故障。在探针端,针对每种故障,分析内核源代码,明确内核层面关键指标,给出排障方向。根据当前的场景,已经在Kindling 演进思维导图中“探针指标能力增强”中列出来了一些的指标。
将会不断借鉴其它排障工具的原理、提炼eBPF技术能够获取到的3类型与4类型数据,并找到使用3类型与4类型数据的故障场景,也欢迎社区用户一起贡献工具、场景和思路。
以下的思维导图是Kindling近一年想做的事情。其中云原生故障场景和业务场景,欢迎各位用户持续不断贡献。
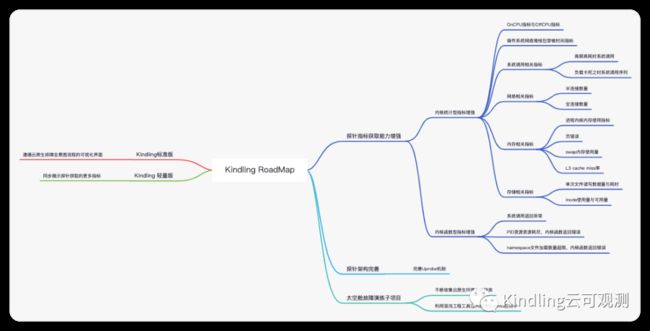
Kindling 演进思维导图
主要时间节点如下:
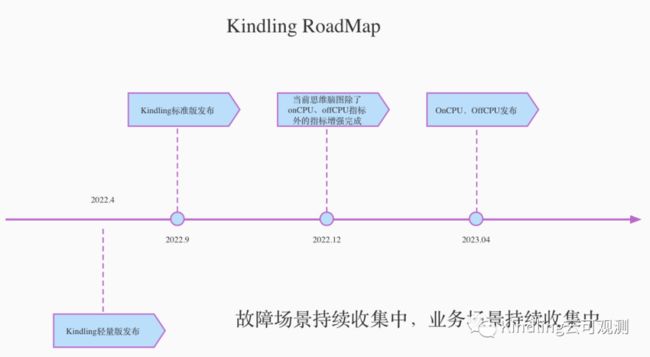
这里再多花点时间介绍下我们认为对用户非常有帮助的OnCPU和OffCPU指标功能:
程序OnCPU火焰图是解决线上CPU消耗较高时的排障利器,OffCPU火焰图是解决程序等待资源较长的排障利器。OnCPU的火焰图已经有很多开源项目正在演进了,Kindling无意重复造轮子或者集成某一个OnCPU火焰图工具。Kindling正在做的是借鉴了OnCPU和OffCPU火焰图的思路,利用eBPF技术分析排障trace异常时间段内,不同线程的表现,最终能够帮助用户分析异常发生时间段,哪些线程可能是问题元凶、再进一步分析哪些函数或者资源导致了异常,并且要能够实现7X24小时常并存储友好。

相关阅读 | Related Reading

开源运营是开源社区的护城河——开源社理事、华为开源能力中心开源专家庄表伟访谈实录

IDC报告:开源成为企业提升创新能力、生产力、协作和透明度的关键

DeepMind爆发史:决定AI高峰的“游戏玩家”|深度学习崛起十年
开源社简介
开源社成立于 2014 年,是由志愿贡献于开源事业的个人成员,依 “贡献、共识、共治” 原则所组成,始终维持厂商中立、公益、非营利的特点,是最早以 “开源治理、国际接轨、社区发展、开源项目” 为使命的开源社区联合体。开源社积极与支持开源的社区、企业以及政府相关单位紧密合作,以 “立足中国、贡献全球” 为愿景,旨在共创健康可持续发展的开源生态,推动中国开源社区成为全球开源体系的积极参与及贡献者。
2017 年,开源社转型为完全由个人成员组成,参照 ASF 等国际顶级开源基金会的治理模式运作。近八年来,链接了数万名开源人,集聚了上千名社区成员及志愿者、海内外数百位讲师,合作了近百家赞助、媒体、社区伙伴。
