【深度学习前沿应用】图像风格迁移
【深度学习前沿应用】图像风格迁移

活动地址:[CSDN21天学习挑战赛](https://marketing.csdn.net/p/bdabfb52c5d56532133df2adc1a728fd)
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:机器学习
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【深度学习前沿应用】图像风格迁移
- 前言
-
-
- 什么是图像风格迁移?
-
- 一、基于KNN的图像风格迁移
-
- (一)、数据加载及预处理
- (二)、创建数据集
- (三)、模型训练
- (四)、绘制图像
- 小结
- 二、基于像素梯度优化的图像风格迁移
-
- (一)、数据加载及预处理
- (二)、模型配置
- (三)、定义损失函数与优化过程
- (四)、生成图像
- 三、基于PaddleHub的图像风格迁移
- 总结
前言
什么是图像风格迁移?
图像风格迁移是指利用算法学习著名画作的风格,然后再把这种风格应用到另一张图片上的技术。
风格迁移的两个要素是内容与风格。我们希望达成的效果是,输入一张图像,程序可以把它转化为带有某种特定风格的图像,同时保留图像中原有的内容信息,而这种风格应该是由人工智能从该类风格的图像中学习得到。
下面介绍两种简单的方法,它们并没有用到GAN,甚至第一种方法竟甭神经网络。

一、基于KNN的图像风格迁移
导读:
这是一种颜色风格迁移。首先引入Lab色彩空间的概念。色彩空间是对颜色的一种量化描述。例如常见的RGB颜色空间,R、G、B分别为红、绿、蓝三个分量。而Lab色彩空间,L为亮度,其值从0到100;a为红色到绿色之间的变化区域,正数时代表红色,负数时代表绿色,其值从-120到120;b为黄色到蓝色之间的变化区域,正数时代表黄色,负数时代表蓝色,其值从-120到120。
之所以将图像从RGB空间转换到Lab空间,是因为Lab图像表示亮度的L通道反映了图像的内容,要做风格转换,只需保留L通道,而将a和b通道替换。
可以通过学习风格图像从L通道到a、b通道的映射,即由对应的L值来决定a、b的值。
仅考虑单个L值到单个a\b值的映射太单一,我们用3x3的块——L值以及八个邻域的值,共9个值。
用KNN来实现这个映射,在风格图像的L通道中找到K个与内容图像最接近的块,将风格图像对应的a、b值加权求和作为迁移图像的a、b值,权重为块像素之差的平方和的倒数。
(一)、数据加载及预处理
import paddle
import paddle as P
from paddle import ParamAttr
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.nn import Conv2D, BatchNorm, Linear, Dropout, AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
import numpy as np
import PIL
from sklearn.neighbors import KNeighborsRegressor
import os
from skimage import io
from skimage.color import rgb2lab, lab2rgb
from skimage.transform import resize
import matplotlib.pyplot as plt
import math
place = P.CUDAPlace(0)
P.disable_static(place)
image_style = '/home/aistudio/work/风格图像/'
print('风格图像:')
plt.imshow(io.imread(image_style+'虚空夜月.jpg'))
plt.show()
image_content = '/home/aistudio/work/浮光楼阁.png'
print('内容图像:')
plt.imshow(io.imread(image_content))
plt.show()
edge_size = 1
k = 4
(二)、创建数据集
L_train = []
ab_train = []
for file in os.listdir(image_style):
L0, ab0, _, _ = create_dataset(image_style+file)
L_train.extend(L0)
ab_train.extend(ab0)
knnr = KNeighborsRegressor(n_neighbors=k, weights='distance')
knnr.fit(L_train, ab_train)
(三)、模型训练
L_train = []
ab_train = []
for file in os.listdir(image_style):
L0, ab0, _, _ = create_dataset(image_style+file)
L_train.extend(L0)
ab_train.extend(ab0)
knnr = KNeighborsRegressor(n_neighbors=k, weights='distance')
knnr.fit(L_train, ab_train)
(四)、绘制图像
def rebuild(image_content):
L, _, row, col = create_dataset(image_content)
ab = knnr.predict(L).reshape([row-2*edge_size, col-2*edge_size, -1])
Lab = np.zeros([row, col, 3])
Lab[:,:,0] = rgb2lab(io.imread(image_content))[:,:,0]
for x in range(edge_size, row-edge_size):
for y in range(edge_size, col-edge_size):
Lab[x, y, 1] = ab[x-edge_size, y-edge_size, 0]
Lab[x, y, 2] = ab[x-edge_size, y-edge_size, 1]
return Lab
小结
这种方法的缺点是只能迁移色彩风格,无法做到纹理、质感、笔触等的风格化。每次需单独学习。
优点是内容图像和迁移图像可以不同尺寸,并且一次可以使用多张风格图像,实现多种风格的迁移。
二、基于像素梯度优化的图像风格迁移
第二种方法虽然也是一种老方法,但是它的做法对我来说反而是新奇的。
一般,我们用神经网络,是将网络的参数作为自变量,构造损失函数更新它们。但是现在反了过来,以输入作为自变量!
网络是预训练的,使用时固定参数不变,用于提取内容图像、风格图像以及迁移图像的特征,再用这些特征构造内容损失和风格损失。最小化迁移图像和内容图像的内容损失;最小化迁移图像和风格图像的风格损失。
首先,初始化迁移图像 = 一部分内容图像 + 一部分噪声。
(一)、数据加载及预处理
import paddle
import paddle as P
from paddle import ParamAttr
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.nn import Conv2D, BatchNorm, Linear, Dropout, AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
import numpy as np
import PIL
from sklearn.neighbors import KNeighborsRegressor
import os
from skimage import io
from skimage.color import rgb2lab, lab2rgb
from skimage.transform import resize
import matplotlib.pyplot as plt
import math
# place = P.CUDAPlace(0)
# P.disable_static(place)
means = np.array([0.485, 0.456, 0.406])
image_style = io.imread('/home/aistudio/work/风格图像/虚空夜月.jpg')
image_style = resize(image_style, (384,512))
image_style = (image_style - means) * 255
image_content = io.imread('/home/aistudio/work/浮光楼阁.png')
sz = image_content.shape[:2]
image_content = resize(image_content, (384,512))
image_content = (image_content - means) * 255
image_transfer = 0.3*image_content + 0.7*np.random.randint(-20, 20, (image_content.shape[0],image_content.shape[1],image_content.shape[2]))
print('初始化的迁移图像:')
plt.imshow(PIL.Image.fromarray(np.uint8(image_transfer/255+means)))
plt.show()
image_transfer = P.to_tensor(image_transfer[:,:,:,None].transpose([3,2,0,1]).astype('float32'), stop_gradient=False)
(二)、模型配置
使用的预训练网络为VGG19。
代码链接:https://github.com/PaddlePaddle/PaddleClas/blob/dygraph/ppcls/modeling/architectures/vgg.py
参数下载链接:https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/VGG19_pretrained.pdparams
由于我们只使用卷积部分提取特征,所以对代码作出一点修改。
计算内容损失使用层conv4_2,计算风格损失使用层conv1_1, conv2_1, conv3_1, conv4_1, conv5_1。
将所有最大池化改为平均池化,以改善梯度流。
- 卷积块定义:
class ConvBlock(nn.Layer):
def __init__(self, input_channels, output_channels, groups, name=None):
super(ConvBlock, self).__init__()
self.groups = groups
self._conv_1 = Conv2D(
in_channels=input_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "1_weights"),
bias_attr=False)
if groups == 2 or groups == 3 or groups == 4:
self._conv_2 = Conv2D(
in_channels=output_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "2_weights"),
bias_attr=False)
if groups == 3 or groups == 4:
self._conv_3 = Conv2D(
in_channels=output_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "3_weights"),
bias_attr=False)
if groups == 4:
self._conv_4 = Conv2D(
in_channels=output_channels,
out_channels=output_channels,
kernel_size=3,
stride=1,
padding=1,
weight_attr=ParamAttr(name=name + "4_weights"),
bias_attr=False)
# self._pool = MaxPool2D(kernel_size=2, stride=2, padding=0)
self._pool = AvgPool2D(kernel_size=2, stride=2, padding=0)
def forward(self, inputs):
conv1 = self._conv_1(inputs)
x = F.relu(conv1)
if self.groups == 2 or self.groups == 3 or self.groups == 4:
conv2 = self._conv_2(x)
x = F.relu(conv2)
if self.groups == 3 or self.groups == 4:
x = self._conv_3(x)
x = F.relu(x)
if self.groups == 4:
x = self._conv_4(x)
x = F.relu(x)
x = self._pool(x)
return x, conv1, conv2
- 前向传播函数:
def forward(self, inputs):
conv1 = self._conv_1(inputs)
x = F.relu(conv1)
if self.groups == 2 or self.groups == 3 or self.groups == 4:
conv2 = self._conv_2(x)
x = F.relu(conv2)
if self.groups == 3 or self.groups == 4:
x = self._conv_3(x)
x = F.relu(x)
if self.groups == 4:
x = self._conv_4(x)
x = F.relu(x)
x = self._pool(x)
return x, conv1, conv2
- VGG网络定义:
class VGGNet(nn.Layer):
def __init__(self):
super(VGGNet, self).__init__()
self.groups = [2, 2, 4, 4, 4]
self._conv_block_1 = ConvBlock(3, 64, self.groups[0], name="conv1_")
self._conv_block_2 = ConvBlock(64, 128, self.groups[1], name="conv2_")
self._conv_block_3 = ConvBlock(128, 256, self.groups[2], name="conv3_")
self._conv_block_4 = ConvBlock(256, 512, self.groups[3], name="conv4_")
self._conv_block_5 = ConvBlock(512, 512, self.groups[4], name="conv5_")
def forward(self, inputs):
x, conv1_1, _ = self._conv_block_1(inputs)
x, conv2_1, _ = self._conv_block_2(x)
x, conv3_1, _ = self._conv_block_3(x)
x, conv4_1, conv4_2 = self._conv_block_4(x)
_, conv5_1, _ = self._conv_block_5(x)
return conv4_2, conv1_1, conv2_1, conv3_1, conv4_1, conv5_1
- 定义网络作特征提取器
vgg19 = VGGNet()
vgg19.set_state_dict(P.load('/home/aistudio/work/vgg19_ww.pdparams'))
vgg19.eval()
(三)、定义损失函数与优化过程
- 定义内容损失:
内容损失是迁移图像、内容图像在conv4_2层输出特征的L2损失。
def contentloss(content, transfer):
return 0.5 * P.sum((content - transfer)**2)
- 计算特征映射的Gram矩阵
风格损失略复杂,先引入格拉姆矩阵(Gram Matrix)的概念。格拉姆矩阵由展平后的特征图两两作内积得到。

其中i、j是特征图通道的编号,k是展平后特征图的长度,也就是展平前的长x宽。
def gram(feature):
_, c, h, w = feature.shape
feature = feature.reshape([c,h*w])
return P.matmul(feature, feature.transpose([1,0]))
- 定义风格损失:
Gram Matrix实际上可看做是feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),在feature map中,每一个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字就代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等,同时,Gram的对角线元素,还体现了每个特征在图像中出现的量,因此,Gram有助于把握整个图像的大体风格。有了表示风格的Gram Matrix,要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。
故风格损失构造为

其中w为conv1_1, conv2_1, conv3_1, conv4_1, conv5_1层的权重。
def styleloss(style, transfer, weight):
loss = 0
for i in range(len(style)):
gram_style = gram(style[i])
gram_transfer = gram(transfer[i])
_, c, h, w = style[i].shape
loss += weight[i] * P.sum((gram_style - gram_transfer)**2) / (2*c*h*w)**2
return loss
- 自定义一个Adam优化器,更新迁移函数图像的参数
def adam(image_transfer, m, v, g, t, η, β1=0.9, β2=0.999, ε=1e-8):
m = β1*m + (1-β1)*g
v = β2*v + (1-β2)*g**2
m_hat = m / (1 - β1**t)
v_hat = v / (1 - β2**t)
image_transfer -= η*m_hat / (P.sqrt(v_hat) + ε)
return image_transfer, m, v
(四)、生成图像
定义一个训练函数,由于只更新迁移图像参数,因此只需要计算一次内容图像与风格图像的特征,而迁移图像的特征在每次更新迭代中都会发生变化:
- 单步迭代
def trainer(image_transfer, m, v, net, features_content, features_style, t, η):
features_transfer = net(image_transfer)
loss_content = contentloss(features_content[0], features_transfer[0])
weight_style = [0.5,1.0,1.5,3.0,4.0]
loss_style = styleloss(features_style[1:], features_transfer[1:], weight_style)
loss = 1e0*loss_content + 1e3*loss_style
net.clear_gradients()
gradients = P.grad(loss, image_transfer)[0]
m,v=0,0
image_transfer, m, v = adam(image_transfer, m, v, gradients, t, η)
return image_transfer, m, v
- 多轮迭代
def train(image_transfer, net, epoch_num):
features_content = net(P.to_tensor(image_content[:,:,:,None].transpose([3,2,0,1]).astype('float32')))
features_style = net(P.to_tensor(image_style[:,:,:,None].transpose([3,2,0,1]).astype('float32')))
m = P.zeros_like(image_transfer)
v = P.zeros_like(image_transfer)
for epoch in range(epoch_num):
image_transfer, m, v = trainer(image_transfer, m, v, net, features_content, features_style, epoch+1, 2)
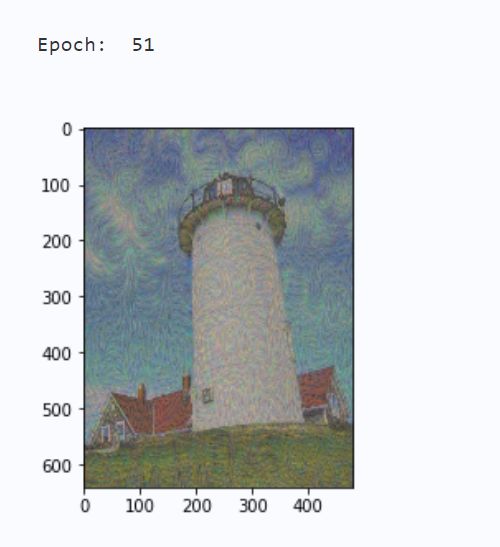
if (epoch) % 50 == 0:
print('Epoch: ', epoch+1)
im = np.squeeze(image_transfer.numpy().transpose([2,3,1,0]))
im = im/255 + means
im = resize(im, sz)
im = PIL.Image.fromarray(np.uint8(im*255))
plt.imshow(im)
plt.show()
- 执行训练:
train(image_transfer, vgg19, 250)
输出结果如图2-1所示:




三、基于PaddleHub的图像风格迁移
上述方法训练虽然简单,但是只能处理相同大小的内容图像与风格图像,在某些应用场景中并不方便,PaddleHub也提供了图像风格迁移的接口,实现简单方便且高效,代码如下:
import paddlehub as hub
import cv2
import matplotlib.image as mpimg
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
! hub install stylepro_artistic
stylepro_artistic = hub.Module(name="stylepro_artistic")
results = stylepro_artistic.style_transfer(images=[{
'content': cv2.imread("work/浮光楼阁.png"),
'styles': [cv2.imread("work/风格图像/虚空夜月.jpg")]}],
alpha = 1.0,
visualization = True)
# 原图展示
test_img_path = "work/浮光楼阁.png"
img = mpimg.imread(test_img_path)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()
# 原图展示
test_img_path = "work/风格图像/虚空夜月.jpg"
img = mpimg.imread(test_img_path)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show()
# 预测结果展示
test_img_path = "transfer_result/ndarray_1620094320.1111157.jpg"
img = mpimg.imread(test_img_path)
# 展示预测结果图片
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.show()
总结
本系列文章内容为根据清华社初版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞浆开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
