ARM开发(二)ARM体系结构——ARM,数据和指令类型,处理器工作模式,寄存器,状态寄存器,流水线,指令集,汇编小练习题
一.fristly,我们依然由浅到深,先来了解什么是ARM.
1.ARM公司
(1)ARM公司1991年成立于英国剑桥,是专门从事基于RISC技术芯片设计开发的公司。
(2)主要出售芯片设计技术的授权,本身却不从事生产,靠转让设计许可由合作公司生产各具特色的芯片。
(3)半导体生产商从ARM公司购买其设计的ARM微处理器,根据各自不同的领域,加入适当的外围电路,从而形成自己的ARM微处理器芯片进入市场。
(4)目前,ARM微处理器几乎已经深入到工业控制,无线通讯,网络应用,消费电子产品,成像和安全产品各个领域。
2.ARM技术特征
(1)体积小,低功耗,低成本,高性能(7纳米微处理器)
(2)支持Thumb(16位)ARM(32位)双指令集,能很好地兼容8位/16位器件
tips:thumb指令体系不完整,支持通用的,必要时候还得使用ARM指令集,例如异常处理
(3)大量使用寄存器,指令执行速度更快
(4)大多数数据操作都在寄存器中完成
(5)寻址方式灵活简单,执行效率高。(9种寻址方式)
(6)指令长度固定。(ARM:32位,Thumb:16位)
3.ARM体系架构
(1)ARM v1:该版本的原型机是ARM 1,没有用于商业
(2)ARM v2:对v1版进行了扩展,包含了对32位结果的乘法指令和协处理器指令的支持。
(3)ARM v3:对v1版进行了扩展,包含了对32位结果的乘法指令和协处理器指令的支持。
(4)ARM v4(飞速发展):ARM7TDMI、ARM7TDMI-S、ARM720T、ARM9TDMI、ARM940T、ARM920T、Intel的StrongARM等是基于ARMv4T版本。
①ARM7系列微处理器:ARM7系列微处理器为低功耗的32位RISC处理器,最适合于要求低价位和低功耗的消费类应用。ARM7TDMI-S适用于工业控制、医疗系统、访问控制、POS机等场合,被称为ARM中的51系列单片机。
②ARM9系列微处理器ARM v4指令集的ARM9系列微处理器包含于不同的应用场合,具有以ARM920T、ARM922T和ARM940T三种类型。
(5)ARMv5:DSP、Java都支持
①ARM9E-S、ARM966E-S、ARM1022E以及Xscale是基于ARMv5TE的。
②ARM9EJ-S、 ARM926EJ-S、 ARM7EJ-S 、ARM1026EJ-S 。是基于ARMv5EJ的。
(6)ARMv6:2001年发布,增加媒体指令
ARM 11系列微处理器是ARM新指令架构ARMv6的新一代设计实现。该系列主要有ARM1136J、ARM1156T2和ARM1176JZ三个内核型号。
(7)ARMv7(Cortex系列):
①ARMv7架构采用了Thumb-2技术,Thumb-2技术比纯32位代码少使用31%的内存.减小了系统开销,同时能够提供比已有的基于Thumb技术的解决方案高出38%的性能。
②ARMv7架构对于早期的ARM处理器软件也提供很好的兼容性。
③ARMv7架构还采用了NEON技术,将DSP和媒体处理能力提高了近4倍,并支持改良的浮点运算,满足下一代3D图形、游戏应用以及传统嵌入式控制应用的需求。
(8)ARMv8:
在32ARM架构上进行开发的,首先用于对扩展虚拟地址和64位数据处理技术有更高要求的产品领域,如企业应用、高档消费电子产品等。
二.数据和指令类型
基本数据类型
(1)ARM 采用的是32位架构(2)ARM 约定:数据类型和c还是有很大区别Byte:8 bits
Halfword: 16 bits (2 byte)
Word :32 bits (4 byte)
Doubleword:64-bits(8byte)(Cortex-A处理器)
(3)大部分ARM core 提供:ARM 指令集(32-bit)
Thumb 指令集(16-bit )
(4)Cortex-A处理器16位和32位Thumb-2指令集
16位和32位ThumbEE指令集
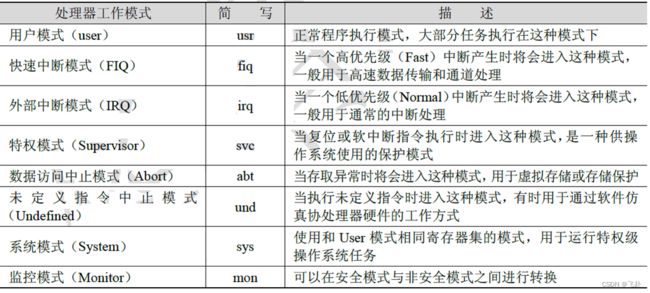
三.处理器地工作模式
以Cortex-A9 为例, Cortex-A9基于ARMv7-A架构,共8种工作模式
除用户模式外的其他7种处理器模式称为特权模式( Privileged Modes)。
在特权模式下,程序可以访问所有的系统资源,也可以任意地进行处理器模式切换。其中以下5种处理器模式又称为异常模式。
(1)快速中断模式(FIQ)。
(2)外部中断模式(IRQ)。
(3)特权模式( Supervior)。
(4)数据访问中止模式( Abort)。
(5)未定义指令中止模式(Undefined)。
处理器模式可以通过软件控制进行切换,也可以通过外部中断或异常处理过程-进行切换。
四.ARM的寄存器
1.通用寄存器
通用寄存器(R0~R15)可分成不分组寄存器R0~R7、分组寄存器R8~R14和程序计数器R15 三类。
(1)不分组寄存器R0~R7
不分组寄存器R0~R7是真正的通用寄存器,可以工作在所有的处理器模式下,没有隐含的特殊用途。(2)分组寄存器R8~R14
---分组寄存器R8~R14取决于当前的处理器模式,每种模式有专用的分组寄存器用于快速异常处理。---寄存器R8~Rl2可分为两组物理寄存器。一组用于FIQ模式,另一组用于除FIQ以外的其他模式。第1组访问R8_fiq~R12_fiq,允许快速中断处理。第二组访问R8_usr~R12_usr,寄存器R8~R12没有任何指定的特殊用途。---寄存器R13~R14可分为7个分组的物理寄存器。1个用于用户模式和系统模式,而其他6个分别用于fiq、svc、abt、irq、und、mon六种异常模式。访问时需要指定它们的模式,如:R13_<mode>,R14_<mode>;其中:<mode>可以从usr、svc、abt、und、irq和fiq六种模式中选取一个。---寄存器R13通常用作堆栈指针,称作SP。每种异常模式都有自己的分组R13。通常R13应当被初始化成指向异常模式分配的堆栈。在入口处,异常处理程序将用到的其他寄存器的值保存到堆栈中;返回时,重新将这些值加载到寄存器。这种异常处理方法保证了异常出现后不会导致执行程序的状态不可靠。---寄存器R14用作子程序链接寄存器,也称为链接寄存器LK (Link Register)。当执行带链接分支(BL)指令时,得到R15的备份。---在其他情况下,将R14当做通用寄存器。类似地,当中断或异常出现时,或当中断或异常程序执行BL指令时,相应的分组寄存器R14_svc、R14_irq、R14_fiq、R14_abt和R14_und用来保存R15的返回值。---FIQ模式有7个分组的寄存器R8~R14,映射为R8_fiq~R14_fiq。在ARM状态下,许多FIQ处理没必要保存任何寄存器。User、IRQ、Supervisor、Abort和Undefined模式每一种都包含两个分组的寄存器R13和R14的映射,允许每种模式都有自己的堆栈和链接寄存器。(3)程序计数器R15寄存器R15用作程序计数器(PC)。在ARM状态,位[1:0]为0,位[31:2]保存PC。在Thumb状态,位[0]为0,位[31:1]保存PC。① 读程序计数器。指令读出的R15的值是指令地址加上8字节。由于ARM指令始终是字对齐的,所以读出结果值的位[1:0]总是0(在Thumb状态下,情况有所变化)。读PC主要用于快速地对临近的指令和数据进行位置无关寻址,包括程序中的位置无关转移。② 写程序计数器。写R15的通常结果是将写到R15中的值作为指令地址,并以此地址发生转移。由于ARM指令要求字对齐,通常希望写到R15中值的位[1:0]=0b00。---由于ARM体系结构采用了多级流水线技术,对于ARM指令集而言,PC总是指向当前指令的下两条指令的地址,即PC的值为当前指令的地址值加8个字节。

五.程序的状态寄存器
寄存器R16用作当前程序状态寄存器(Current Program Status Register, CPSR) 可以在任何处理器模式下被访问,它包含下列内容:
(1) ALU (Arithmetic Logic Unit, 算术逻辑单元)状态标志的备份。
(2)当前的处理器模式。
(3)中断使能标志。
(4)设置处理器的状态(只在4T架构)。
tips:
每一种处理器模式下都有一个专用的物理寄存器作备份程序状态寄存器( Saved Program Status Register, SPSR)。当特定的异常中断发生时,这个物理寄存器负责存放当前程序状态寄存器的内容。当异常处理程序返回时,再将其内容恢复到当前程序状态寄存器。
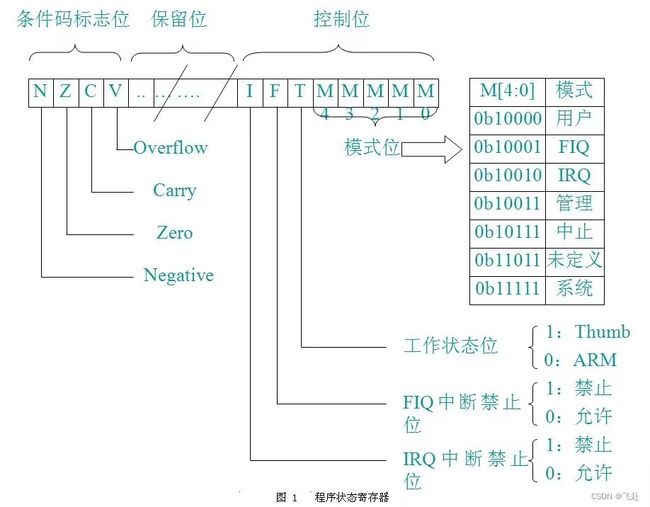
(1)条件码标志
N、 Z 、 C 、 V ( Negative 、 Zero 、 Carry 、 oVerflow )均为条件码标志位( Condition Code Flags ),它们的内容可被算术或逻辑运算的结果所改变,并且可以决定某条指令是否被执行。 CPSR 中的条件码标志可由大多数指令检测以决定指令是否执行。在 ARM 状态下,绝大多数的指令都是有条件执行的。在 Thumb 状态下,仅有分支指令是有条件执行的。通常条件码标志通过执行比较指令( CMN、CMP、TEQ、TST )、一些算术运算、逻辑运算和传送指令进行修改。(2) 条件码标志的通常含义如下:N :如果结果是带符号二进制补码,那么,若结果为负数,则 N=1;若结果为正数或 0 ,则 N = 0 。Z :若指令的结果为 0 ,则置 1 (通常表示比较的结果为 “ 相等 ” ),否则置 0 。C :可用如下 4 种方法之一设置:----加法(包括比较指令CMN)。若加法产生进位(即无符号溢出),则C置1;否则置0。
----减法(包括比较指令CMP)。若减法产生借位(即无符号溢出),则C置0;否则置1。
----对于结合移位操作的非加法/减法指令,C置为移出值的最后1位。
----对于其他非加法/减法指令,C通常不改变。
V :可用如下两种方法设置,即一-对于加法或减法指令,当发生带符号溢出时,V置1,认为操作数和结果是补码形式的带符号整数。
一-对于非加法/减法指令,V通常不改变。
(3)控制位
程序状态寄存器PSR(Program Status Register)的最低8位I、F、T和M[4:0]用作控制位。当异常出现时改变控制位。处理器在特权模式下时也可由软件改变。
a .中断禁止位I:置1,则禁止IRQ中断;
F:置1,则禁止FIQ中断。
b . T 位T=0 指示ARM执行;
T=1 指示Thumb执行。
c .模式控制位M4、M3、M2、Ml和M0(M[4:0])是模式位,决定处理器的工作模式,如表所列。
(4)其他位
程序状态寄存器的其他位保留,用做以后的扩展。

六.流水线
流水线的基本概念
Ø 流水线技术 应用 于计算机系统结构的各个方面,流水线技术的基本思想是将一个重复的时序分解成若干个子过程,而每一个子过程都可有效地在其专用功能段上与其他子过程同时执行。Ø 流水线结构的 类型 :按完成的功能分类可分为单功能流水线和多功能流水线;按同一时间内各段之间的连接方式分类可静态流水线和动态流水线;按数据表示分类可分为标量流水线处理器和向量流水线处理器。Ø 指令流水线就是将一条指令分解成一连串执行的子过程,例如把指令的执行过程细分为取指令、指令译码、取操作数和执行 4 个子过程。例如: 例如把指令的执行过程细分为取指令、指令译码、取操作数和执行 4 个子过程。指令流水线处理的时空图如下所示,其中的 1 、 2 、 3 、 4 、 5 表示要处理的 5 条指令。从图可见采用流水方式可同时执行多条指令。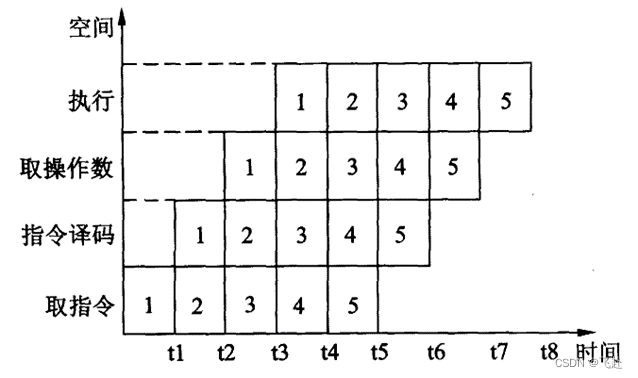
流水线处理机的主要指标
(1)吞吐率
在单位时间内,流水线处理机流出的结果数称为吞吐率。对指令而言就是单位时间里执行的指令数。如果流水线的子过程所用时间不一样长,则吞吐率P应为最长子过程的倒数。
(2)建立时间
流水线开始工作,须经过一定时间才能达到最大吞吐率,这就是建立时间。若m个子过程所用时间一样,均为t0,则建立时间T0=mΔt0。
流水线的分类
1、3级流水线ARM组织(到ARM7) 三级流水线又被称为最优流水线
(1)取指令(Fetch): 从寄存器装载一条指令。
(2)译码(Decode):识别被执行的指令,并为下一个周期准备数据通路的控制信号。
(3)执行(Excute): 处理指令并将结果写回寄存器。图2-5所示为3级流水线指令的执行过程。
当处理器执行简单的数据处理指令时,流水线使得平均每个时钟周期能完成1条指令。但1条指令需要3个时钟周期来完成,因此,有3个时钟周期的延时(Latency),但吞吐率(Throughput) 是每个周期1条指令。
2、5级流水线ARM组织(到ARM7)
(1)取指令(Fetch): 从存储器中取出指令,并将其放入指令流水线。
(2)译码(Decode): 指令被译码,从寄存器堆中读取寄存器操作数。
(3)执行(Execute): 将其中1个操作数移位,并在ALU中产生结果。
(4)缓冲/数据( Buffer/Data): 如果需要则访问数据存储器,否则ALU只是简单地缓冲1个时钟周期。
(5)回写(Write-back): 将指令的结果回写到寄存器组中,包括任何从寄存器读出的数据。
5级流水线中提前1级来读取指令操作数,得到的值是不同的,5级流水线ARM完全仿真3级流水线的行为,在取指级增加的PC值被直接送到译码级的寄存器,穿过两级之间的流水线寄存器。下一条指令的PC+4等于当前指令的PC+8,因此,未使用额外的硬件便得到了正确的R15。
2、5级流水线ARM组织(到ARM7)
(1)取指令(Fetch): 从存储器中取出指令,并将其放入指令流水线。
(2)译码(Decode): 指令被译码,从寄存器堆中读取寄存器操作数。
(3)执行(Execute): 将其中1个操作数移位,并在ALU中产生结果。
(4)缓冲/数据( Buffer/Data): 如果需要则访问数据存储器,否则ALU只是简单地缓冲1个时钟周期。
(5)回写(Write-back): 将指令的结果回写到寄存器组中,包括任何从寄存器读出的数据。
5级流水线中提前1级来读取指令操作数,得到的值是不同的,5级流水线ARM完全仿真3级流水线的行为,在取指级增加的PC值被直接送到译码级的寄存器,穿过两级之间的流水线寄存器。下一条指令的PC+4等于当前指令的PC+8,因此,未使用额外的硬件便得到了正确的R15。
影响流水线性能的因素
(1)互锁
在典型的程序处理过程中,经常会遇到这样的情形,即一条指令的结果被用作下一条指令的操作数,如:
流水线的操作产生中断,因为第1条指令的结果在第2条指令取数时还没有产生。第2条指令必须停止,直到结果产生为止。
(2)跳转指令
跳转指令也会破坏流水线的行为,因为后续指令的取指步骤受到跳转日标计算的影响,所以必须推迟。但是,当跳转指令被译码时,在它被确认是跳转指令之前,后续的取指操作已经发生。这样一来,已经被预取进入流水线的指令不得不丢弃。如果跳转目标的计算是在ALU阶段完成的,那么在得到跳转目标之前已经有两条指令按原有指令流读取。




七.指令集
关于指令的讲解就要上代码了,代码比较简单重在理解
(1)搬移指令
.text @ 汇编文本段的开始 @ 搬移指令 mov r0, #5 @ r0 = 5 mov r1, r0 @ r1 = r0 mov r2, #1 @ r2 = 1 mov r3, r2, LSL #3 @ r3 = r2<<3 mov r4, r3, LSR #2 @ r4 = r3>>2 mrs r6, cpsr @ 将cpsr寄存器的内容搬移到 r6寄存器 msr cpsr, #0xd3 @ 将r1寄存器的内容写入 cpsr中 @ mov r1, #0x10 @ msr cpsr, r1 @ 不改变工作模式情况下,改变处理器状态 mrs r0, cpsr @ 注意:不能对 立即数(常数)移位操作 mov r1, #1 @ orr 按位或 orr r0, r1, LSL #5 msr cpsr, r0 .end @ 汇编文本段的结束(2)算术指令
.text add r0, #4 @ r0 = r0 + 4 add r0, r0, #4 sub r1, r0, #-4 @ r1 = r0-(-4) sub r1, r1, r0, LSR #2 @ r1 = r1 - (r0>>2) .end(3)逻辑指令
.text @ 将模式设置为 usr/system模式 @ mrs r0, cpsr @ and r0, #0xfffffffc @ ==> bic r0, #0x3 @将 r0中 第0号和第1号位清零 @ msr cpsr, r0 @ orr r0, #0x3 @ mrs r0, cpsr @ msr cpsr, r0 @ 非特权模式,不能向cpsr状态寄存器写入数据 @ mrs r0, cpsr @ bic r0, #0x40 @ 将r0中 第6号位清零 @ msr cpsr, r0 mrs r0, cpsr tst r0, #0x20 @ 测试 r0 的第5号位是否为 零 NOP @ 空指令 NOP .end(4)跳转指令
.text main: mov r0, #2 bl func1 while: b while func1: mov r6, lr cmp r0, #2 bleq func2 blne func3 mov pc, r6 func2: add r0, #3 mov pc, lr func3: sub r0, #1 mov pc, lr .end(5)ldr+str指令
.text main: @ ldr 伪指令,将buf这个地址 不合法的立即数,写到r0中 ldr r0, =buf @ ldrb 将 r0地址上的第一个字节数据 读到 r1 中 ldrb r1, [r0] @ ldrb 将 r0+4 地址上的第一个字节数据 读到 r1 中 @ r1 = *(r0+4) @ldrb r1, [r0, #4] mov r2, #0x9 @ strb 将 r2中的数据前1个字节写入 r0+2 地址上 @ *(r0 + 2) = r2 strb r2, [r0, #2] main_end: NOP NOP .data @ 汇编文件数据段的开始,cpu不会直接取址 buf: @ buf相当于 缓冲区首地址(数组名) @ .byte表示一个字节空间,此处定义初始化一个空间 .byte 0x1, 0x2, 0x3, 0x4, 0x5 .end
八.最后整一个小练习题来帮助大家了解了解汇编吧。
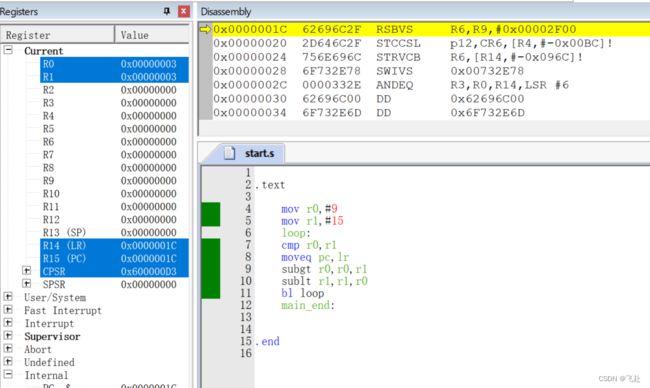
解题:
.text mov r0,#9 mov r1,#15 loop: cmp r0,r1 moveq pc,lr subgt r0,r0,r1 sublt r1,r1,r0 bl loop main_end: .end思路c语言的算法已经给出来了,我们只需要翻译,用到的是辗转相除法
1.将9赋给r0,15赋给r1
2.设置一个loop标记
3.比较r0和r1
如果它们等于,就把上一个lr地址放到pc里面去
如果是大于执行 r0=r0-r1
如果是小于执行 r1=r1-r0
然后一直循环到等于跳出程序
最后证明最大公约数是3.