扫盲:mmdetection安装以及训练自己的数据集
一、安装
# 创建环境名为mmdet
conda create -n mmdet python=3.7
# 激活环境mmdet
conda activate mmdet
# 安装pytorch1.6
# 安装torchvision0.7.0
# 安装cuda,此处注意cuda版本要对应上或电脑已经安装了更高的版本,cuda版本向下兼容,电脑安装最新的cuda并把驱动升级到最新。
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch
# 安装对应版本的mmcv-full,这个是官方已经给编译过的,安装时注意版本与上一步相同。cu102为cudatoolkit10.2,torch1.6.0为pytorch1.6.0。对应不上安装时看不出来,用的时候必报错,而且找不到原因。而且这是官方编译好的,意味着不能瞎改pytorch版本。
pip install mmcv-full==1.4.6 -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.6.0/index.html
# 安装mmdet,安装检测模块的需要的包
pip install mmdet
# 安装mmrotate,安装旋转检测模块需要的包,这个不用mmrotate可不安
pip install mmrotate
# 也可以用另一种方法安装mmrotate
git clone https://github.com/open-mmlab/mmrotate.git
cd mmrotate
pip install -r requirements/build.txt
pip install -v -e .
1.报错不要慌,领悟每个命令行作用的同时,看看版本对没对上,csdn好多博文版本没对上或者用mim安装导致各种报错。
2.安装失败,这只是一种可能,看看是否安装了VS2019 C++buildtool,因为之前安装pycocotool的时候因为没安装这个工具导致安装不上。安装这个工具即使不需要,也没有任何害处,可能将来会用到。
二、demo演示文件测试效果
进入image_demo.py文件,读一读。
# ....
def parse_args():
parser = ArgumentParser()
parser.add_argument('img', help='Image file')
parser.add_argument('config', help='Config file')
parser.add_argument('checkpoint', help='Checkpoint file')
# ....稍加修改,让配置参数时,更加规整而且配置时一一对应,更加严谨。
# ....
def parse_args():
parser = ArgumentParser()
parser.add_argument('--img', help='Image file')
parser.add_argument('--config', help='Config file')
parser.add_argument('--checkpoint', help='Checkpoint file')
# ....pycharm中配置参数:1.图片路径2.模型路径3.权重路径;此处的模型与权重最好时完全对应上。
--img
D:\\Project\\mmdetection-master\\demo\\demo.jpg
--config
D:\\Project\\mmdetection-master\\configs\\faster_rcnn\\faster_rcnn_r50_fpn_1x_coco.py
--checkpoint
D:\\Project\\mmdetection-master\\faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth报个小错,无伤大雅。小小警告,一般都是告诉我xx已经淘汰了;被xx替代了;建议替换等等。


结果出来了,意味着你的环境配置已经问题不大了,后面如果缺组件,在现在的环境内pip install xxx即可。
三、简单的口罩检测——训练自己的数据集
1.首先准备好数据集——一些未标注的图片

2.用labelme标注软件进行标注
labelme安装很简单,在本环境安装就行。
# 安装pyqt5
pip install pyqt5
# 安装labelme
pip install labelme
# 运行labelme
labelme标注过程过于简单,不赘述。注意:
(1)不要乱改标注后的json文件名,要一一对应。
(2)矩形框标注从左上到右下符合图片坐标的规定。

3.json to coco,格式转换。
运行一下脚本,注意输入文件位置与输出文件位置。
import os
import json
import numpy as np
import glob
import shutil
import cv2
from sklearn.model_selection import train_test_split
np.random.seed(41)
classname_to_id = {
"mask": 0, #改成自己的类别
"person": 1
}
class Lableme2CoCo:
def __init__(self):
self.images = []
self.annotations = []
self.categories = []
self.img_id = 0
self.ann_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1) # indent=2 更加美观显示
# 由json文件构建COCO
def to_coco(self, json_path_list):
self._init_categories()
for json_path in json_path_list:
obj = self.read_jsonfile(json_path)
self.images.append(self._image(obj, json_path))
shapes = obj['shapes']
for shape in shapes:
annotation = self._annotation(shape)
self.annotations.append(annotation)
self.ann_id += 1
self.img_id += 1
instance = {}
instance['info'] = 'spytensor created'
instance['license'] = ['license']
instance['images'] = self.images
instance['annotations'] = self.annotations
instance['categories'] = self.categories
return instance
# 构建类别
def _init_categories(self):
for k, v in classname_to_id.items():
category = {}
category['id'] = v
category['name'] = k
self.categories.append(category)
# 构建COCO的image字段
def _image(self, obj, path):
image = {}
from labelme import utils
img_x = utils.img_b64_to_arr(obj['imageData'])
h, w = img_x.shape[:-1]
image['height'] = h
image['width'] = w
image['id'] = self.img_id
image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
return image
# 构建COCO的annotation字段
def _annotation(self, shape):
# print('shape', shape)
label = shape['label']
points = shape['points']
annotation = {}
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(classname_to_id[label])
annotation['segmentation'] = [np.asarray(points).flatten().tolist()]
annotation['bbox'] = self._get_box(points)
annotation['iscrowd'] = 0
annotation['area'] = 1.0
return annotation
# 读取json文件,返回一个json对象
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
# COCO的格式: [x1,y1,w,h] 对应COCO的bbox格式
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
#训练过程中,如果遇到Index put requires the source and destination dtypes match, got Long for the destination and Int for the source
#参考:https://github.com/open-mmlab/mmdetection/issues/6706
if __name__ == '__main__':
labelme_path = "./labelme-data/maskdataset"
saved_coco_path = "./labelme-data/coco-format"
print('reading...')
# 创建文件
if not os.path.exists("%scoco/annotations/" % saved_coco_path):
os.makedirs("%scoco/annotations/" % saved_coco_path)
if not os.path.exists("%scoco/images/train2017/" % saved_coco_path):
os.makedirs("%scoco/images/train2017" % saved_coco_path)
if not os.path.exists("%scoco/images/val2017/" % saved_coco_path):
os.makedirs("%scoco/images/val2017" % saved_coco_path)
# 获取images目录下所有的joson文件列表
print(labelme_path + "/*.json")
json_list_path = glob.glob(labelme_path + "/*.json")
print('json_list_path: ', len(json_list_path))
# 数据划分,这里没有区分val2017和tran2017目录,所有图片都放在images目录下
train_path, val_path = train_test_split(json_list_path, test_size=0.1, train_size=0.9)
print("train_n:", len(train_path), 'val_n:', len(val_path))
# 把训练集转化为COCO的json格式
l2c_train = Lableme2CoCo()
train_instance = l2c_train.to_coco(train_path)
l2c_train.save_coco_json(train_instance, '%scoco/annotations/instances_train2017.json' % saved_coco_path)
for file in train_path:
# shutil.copy(file.replace("json", "jpg"), "%scoco/images/train2017/" % saved_coco_path)
img_name = file.replace('json', 'jpg')
temp_img = cv2.imread(img_name)
try:
cv2.imwrite("{}coco/images/train2017/{}".format(saved_coco_path, img_name.split('\\')[-1].replace('png', 'jpg')), temp_img)
except Exception as e:
print(e)
print('Wrong Image:', img_name )
continue
print(img_name + '-->', img_name.replace('png', 'jpg'))
for file in val_path:
# shutil.copy(file.replace("json", "jpg"), "%scoco/images/val2017/" % saved_coco_path)
img_name = file.replace('json', 'jpg')
temp_img = cv2.imread(img_name)
try:
cv2.imwrite("{}coco/images/val2017/{}".format(saved_coco_path, img_name.split('\\')[-1].replace('png', 'jpg')), temp_img)
except Exception as e:
print(e)
print('Wrong Image:', img_name)
continue
print(img_name + '-->', img_name.replace('png', 'jpg'))
# 把验证集转化为COCO的json格式
l2c_val = Lableme2CoCo()
val_instance = l2c_val.to_coco(val_path)
l2c_val.save_coco_json(val_instance, '%scoco/annotations/instances_val2017.json' % saved_coco_path)
路径分布

instances_train2017.json节取
{
"info": "spytensor created",
"license": [
"license"
],
"images": [
{
"height": 737,
"width": 1024,
"id": 0,
"file_name": "19.jpg"
},
...
],
"annotations": [
{
"id": 0,
"image_id": 0,
"category_id": 0,
"segmentation": [
[
52.74809160305344,
350.9083969465649,
191.6793893129771,
457.0152671755725
]
],
"bbox": [
52.74809160305344,
350.9083969465649,
138.93129770992365,
106.1068702290076
],
"iscrowd": 0,
"area": 1.0
},
...
],
"categories": [
{
"id": 0,
"name": "mask"
},
{
"id": 1,
"name": "person"
}
]
}在 json 文件中有三个必要的键:
-
images: 包含多个图片以及它们的信息的数组,例如file_name、height、width和id。 -
annotations: 包含多个实例标注信息的数组。 -
categories: 包含多个类别名字和 ID 的数组。
4.对应自己的数据集去修改源码的类别
因为采用的时coco格式,故去修改源码中coco(80个类别)的类别,改成自己数据集的两个类别。
1.修改第一处
mmdet\core\evaluation\class_names.py# ...
def coco_classes():
# return [
# 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
# 'truck', 'boat', 'traffic_light', 'fire_hydrant', 'stop_sign',
# 'parking_meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
# 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
# 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
# 'sports_ball', 'kite', 'baseball_bat', 'baseball_glove', 'skateboard',
# 'surfboard', 'tennis_racket', 'bottle', 'wine_glass', 'cup', 'fork',
# 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
# 'broccoli', 'carrot', 'hot_dog', 'pizza', 'donut', 'cake', 'chair',
# 'couch', 'potted_plant', 'bed', 'dining_table', 'toilet', 'tv',
# 'laptop', 'mouse', 'remote', 'keyboard', 'cell_phone', 'microwave',
# 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
# 'scissors', 'teddy_bear', 'hair_drier', 'toothbrush'
# ]
return [
'mask', 'person',
]
# ...把80类注释掉,改成自己的类别,不改就会出现类别的检测错误,mask检测成person,person检测成bicycle。
2.修改第二处
mmdet\datasets\coco.pyclass CocoDataset(CustomDataset):
# CLASSES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
# 'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
# 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
# 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
# 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
# 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
# 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
# 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
# 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
# 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
# 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
# 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
# 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
# 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush')
#
# PALETTE = [(220, 20, 60), (119, 11, 32), (0, 0, 142), (0, 0, 230),
# (106, 0, 228), (0, 60, 100), (0, 80, 100), (0, 0, 70),
# (0, 0, 192), (250, 170, 30), (100, 170, 30), (220, 220, 0),
# (175, 116, 175), (250, 0, 30), (165, 42, 42), (255, 77, 255),
# (0, 226, 252), (182, 182, 255), (0, 82, 0), (120, 166, 157),
# (110, 76, 0), (174, 57, 255), (199, 100, 0), (72, 0, 118),
# (255, 179, 240), (0, 125, 92), (209, 0, 151), (188, 208, 182),
# (0, 220, 176), (255, 99, 164), (92, 0, 73), (133, 129, 255),
# (78, 180, 255), (0, 228, 0), (174, 255, 243), (45, 89, 255),
# (134, 134, 103), (145, 148, 174), (255, 208, 186),
# (197, 226, 255), (171, 134, 1), (109, 63, 54), (207, 138, 255),
# (151, 0, 95), (9, 80, 61), (84, 105, 51), (74, 65, 105),
# (166, 196, 102), (208, 195, 210), (255, 109, 65), (0, 143, 149),
# (179, 0, 194), (209, 99, 106), (5, 121, 0), (227, 255, 205),
# (147, 186, 208), (153, 69, 1), (3, 95, 161), (163, 255, 0),
# (119, 0, 170), (0, 182, 199), (0, 165, 120), (183, 130, 88),
# (95, 32, 0), (130, 114, 135), (110, 129, 133), (166, 74, 118),
# (219, 142, 185), (79, 210, 114), (178, 90, 62), (65, 70, 15),
# (127, 167, 115), (59, 105, 106), (142, 108, 45), (196, 172, 0),
# (95, 54, 80), (128, 76, 255), (201, 57, 1), (246, 0, 122),
# (191, 162, 208)]
CLASSES = ('mask', 'person')
PALETTE = [(220, 20, 60), (119, 11, 32)]类别和颜色做一下修改。
3.配置文件修改
生成自己的配置文件:因为项目自带的配置文件由于模块化设计,有继承关系,参数不能在一个文件上修改,配置参数很麻烦。采用一种方法:先把要用的模型的配置文件在train中作为配置参数运行一遍,会在work_dir文件中找到一个完整的配置文件。
1.复制想要的模型的配置文件绝对路径。
2.将绝对路径复制放进pycharm配置参数
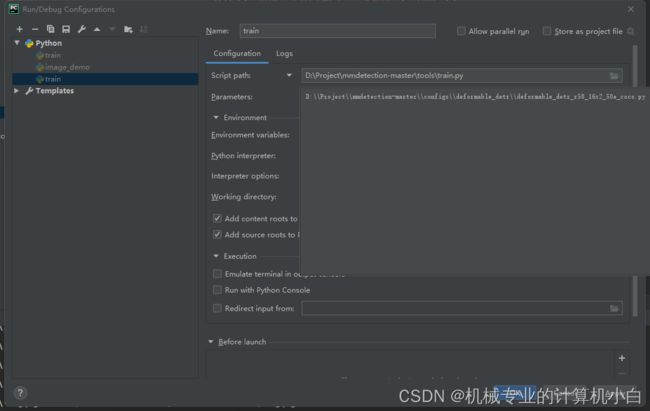
3.运行后在work_dir中找到并改名

4.修改输出类别数量,coco数据集80类,自己数据集2类。num_classes
# ...
bbox_head=dict(
type='DeformableDETRHead',
num_query=300,
num_classes=80,
in_channels=2048,
sync_cls_avg_factor=True,
as_two_stage=False,
# ...# ...
bbox_head=dict(
type='DeformableDETRHead',
num_query=300,
num_classes=2,
in_channels=2048,
sync_cls_avg_factor=True,
as_two_stage=False,
# ...5.修改训练集和验证集路径
# ...
train=dict(
type='CocoDataset',
ann_file='D:\\Project\\mmdetection-master\\mmdet\\data\\labelme-data\\coco-formatcoco\\annotations\\instances_train2017.json',
img_prefix='D:\\Project\\mmdetection-master\\mmdet\\data\\labelme-data\\coco-formatcoco\\images\\train2017',
# ...
# ...
val=dict(
type='CocoDataset',
ann_file='D:\\Project\\mmdetection-master\\mmdet\\data\\labelme-data\\coco-formatcoco\\annotations\\instances_val2017.json',
img_prefix='D:\\Project\\mmdetection-master\\mmdet\\data\\labelme-data\\coco-formatcoco\\images\\val2017',
# ...6.加上预训练模型
load_from = 'D:\\Project\\mmdetection-master\\deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth'7.修改训练的配置
batch size和num_workers,这个算法很吃内存,batch size=1
# ...
data = dict(
samples_per_gpu=1,
workers_per_gpu=1,
# ...修改这一块,50个epoch
evaluation = dict(interval=10, metric='bbox')
checkpoint_config = dict(interval=50)
log_config = dict(interval=10, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = 'D:\Project\mmdetection-master\deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth'
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
auto_scale_lr = dict(enable=False, base_batch_size=32)8.重新编译文件,修改完 class_names.py 和 voc.py 之后一定要重新编译代码(运行python setup.py install,要不报错AssertionError: The `num_classes` (80) in Shared2FCBBoxHead of MMDataParallel does not matche。
9.开始训练

电脑配置不够,内存爆了,一顿操作猛如虎,一看结果250,以后拿个简单的模型试一试,但是过程是可以借鉴的。
换Faster r-cnn,同样的思路,再用demo检测一下。
--img
D:\\Project\\mmdetection-master\\demo\\mask.jpg
--config
D:\\Project\\mmdetection-master\\configs\\faster_rcnn\\my_faster_rcnn_r50_fpn_1x_coco.py
--checkpoint
D:\\Project\\mmdetection-master\\tools\\work_dirs\\faster_rcnn_r50_fpn_1x_coco\\epoch_30.pth
这么少的数据集,能有这个效果,已经不错了。