ADS-NPU芯片架构设计的五大挑战
作者 | Dr. Luo
简介:东南大学工学博士,英国布里斯托大学博士后,复睿微电子英国研发中心GRUK首席AI科学家,常驻英国剑桥。Dr. Luo长期从事科学研究和机器视觉先进产品开发,曾在某500强ICT企业担任机器视觉首席科学家。
AI算法在自动驾驶ADS领域的行业应用,其当前从感知到认知的演进方向,主要体现在:
1)能够在统一空间支持多模传感器感知融合与多任务共享,在提升有限算力的计算效率的同时,确保算法模型在信息提取中对极端恶劣场景(雨雪雾、低照度、高度遮挡、传感器部分失效、主动或被动场景攻击等)的泛化感知能力,降低对标注数据和高清地图的过度依赖;
2)预测与规划联合建模,离线与在线学习相结合,监督与自监督学习相结合,从而能够处理不确定性下的安全行驶与有效决策,提供认知决策行为的可解释问题,通过持续学习解决新场景问题。
当前,对应于ADS传感器负载多样化和融合感知决策算法多样化的演进趋势,ADS的算力需求和芯片加速能力以(十倍速/每几年)的持续高增长态势呈现。ADS领域大算力NPU芯片的当前发展现状,真可谓是:大算力之时代,以感知策,四两拨千斤者;狂洗牌乎战局,唯快应变,一力降十会也。
图1. DNN任务占比分析: CNN vs Transformer (图表分析来自文献1)
如图1 所示,ADS算法从Compute-bound向Memory-bound演进。ADS的存算混合需求,可以通过“硬件预埋,算法迭代,算力均衡“ ,来提供一个向前兼容的解决方案,以通用大算力NPU设计来解决算法未来的不确定性,具体体现在:1) 底层架构的演进:从存算分离到近内存计算,最终走向内存计算; 2) 数据通道与模型:高速数据接口+数据压缩+模型压缩+低精度逼近计算+稀疏计算加速; 3) 并行的顶层架构:模型-硬件联合设计,以及硬设计可配置+硬件调度+软运行可编程调度引擎。
老子曾曰“合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。” 老子又曰 ”天下难事,必作于易;天下大事,必作于细。”处理艰难问题从易入手,致力远大目标从微着力。ADS-NPU芯片的架构设计,同样需要用【见微知著】的能力,来解决异构计算、稀疏计算、逼近计算、内存计算等几类常见的难题与挑战。
1. 异构计算之设计挑战

图2. 脉动阵列架构(图表分析来自文献1)

图3. 可配置的脉动阵列架构 (图表分析来自文献1)
对比CPU十百级的并行处理单元和GPU上万级的并行处理单元,NPU会有百万级的并行计算单元,可以采用Spatial加速器架构来实现,即Spatial PE空间单元阵列通过NoC,数据总线,或跨PE的互联来实现矩阵乘运算(全卷积计算或全连接FC计算)、数据流高速交互、以及运算数据共享。
粗颗粒度的可配置架构CGRA是Spatial加速器的一种形态,即可配置的PE Array通过纳秒或微秒级别可配置的Interconnect来对接,可以支持配置驱动或者数据流驱动运行。
如图2和图3所示,脉动Systolic加速器架构也是Spatial加速器的一类实现方式,其主要计算是通过1D或2D计算单元对数据流进行定向固定流动处理最终输出累加计算结果,对DNN输出对接卷积层或池化层的不同需求,可以动态调整硬件计算逻辑和数据通道,但存在的问题难以支撑压缩模型的稀疏计算加速处理。
NPU的第二类计算单元是Vector矢量加速器架构,面向矢量的Element-wise Sum、Conv1x1卷积、Batch Normalization、激活函数处理等运算操作,其计算可以通过可配置的矢量核来实现,业界常用的设计是标量+矢量+阵列加速器的组合应用来应对ADS多类传感器的不同前处理需求和多样化算法模型流水线并行处理的存算混合需求。
NPU SoC也可以采用多核架构技术,即提供千百级的加速器物理核来组件封装和Chiplet片上互联提供更高程度的平行度,尤其是适合大算力下高并行数据负载,这需要底层硬件调度与上层软件调度相结合,提供一个分布式硬件计算资源的细颗粒度运行态调用。
NPU另外一个在演进中的内存处理器PIM架构,即通过将计算靠近存储的方式来降低数据搬移能耗和提升内存带宽。可以分成近内存计算与内存计算两种类型。近内存计算将计算引擎靠近传统的DRAM或者SRAM cell,保持它们的设计特性。
内存计算需要对内存cell添加数据计算逻辑,多采用ReRAM或者STT-MRAM新型工艺,目前采用模拟或数字类型的设计,可实现>100TOPS/Watt的PPA性能,但技术难题是如何在运行态时进行大模型参数动态刷新,工艺实现可能也落后于市场预期。
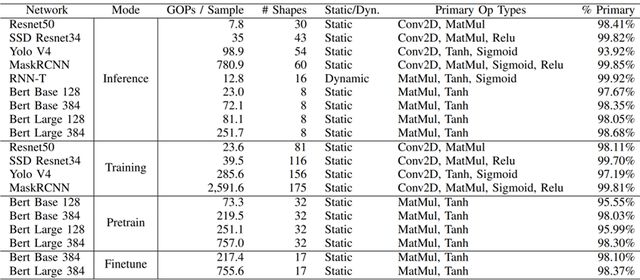
图4. AI算法模型负载的算子分布统计(图表分析来自文献2)
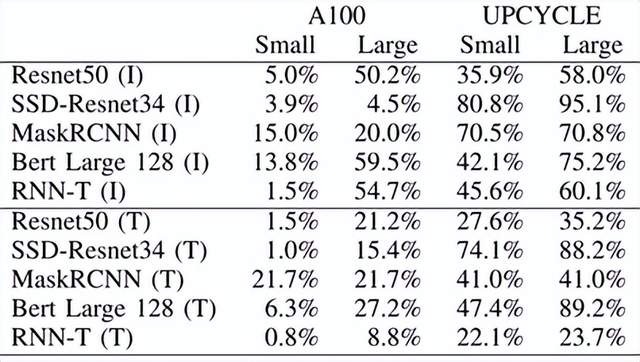
图5. nVidia A100的TensorCore架构与UPCYCLE 融合架构的计算效率对比 (图表分析来自文献2)
当前市场上主流AI芯片,常用的架构有以下几种形态:1) GEMM加速架构(TensorCore from nVidia, Matrix Core from AMD); 2) CGRA (初创公司); 3) Systolic Array (Google TPU); 4) Dataflow (Wave, Graphcore,初创公司); 4) Spatial Dataflow (Samba Nova, Groq); 5) Sparse架构 (Inferentia)。
如图4与图5所示案例可以看出,ADS-NPU设计其中有一个挑战是低计算效率问题。异构计算架构一个主要的目的是希望从设计方法学上找到一个硬设计时优化可配置与软运行时动态可编程的平衡点,从而能够提供一个通用的方案覆盖整个设计空间。
另外值得一提的是,UPCYCLE 的融合架构案例,涉及到SIMD/Short Vector, Matrix Multiply, Caching, Synchronization等多核优化策略,这个案例,说明只是通过短矢量处理+传统的内存缓存+同步策略的传统方法结合,在不使用标量+矢量+阵列的微架构组合条件下,依旧可以从顶层软件架构层面的优化(指令集和工具链优化策略,模型-硬件联合优化)来实现7.7x整体计算性能提升与23x功耗效率提升。
2. 稀疏计算之设计挑战
ADS-NPU低效率计算问题,从微架构设计领域,可以涉及到:1) 稀疏数据(稀疏DNN网络,或者稀疏输入输出数据)导致PE对大量零值数据的无效计算问题;2)PE之间由于软件硬件调度算法的效率低,PE之间互相依赖导致的延迟问题;3)数据通道与计算通道峰值能力不匹配导致的数据等待问题。
上述问题2和问题3可以从顶层架构和存算微架构设计上来有效解决。问题1可以对稀疏数据进行压缩处理来有效提升微架构计算单元PE的效率。如图6和图7所示,稀疏数据图编码的案例,可以有效提升数据存储空间和对数据通道的冲击,计算单元依据非零数据NZVL分布图进行有效甄别计算,以添加简单的逻辑单元为代价就可以将一个72PE的计算效率提升到95%,数据带宽降低40%。
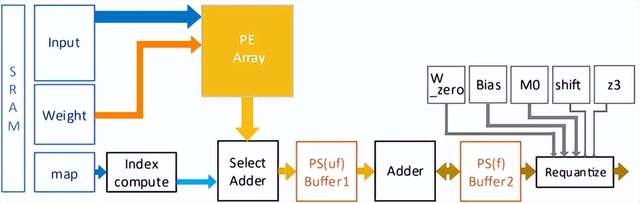
图6. 稀疏计算微架构案例(图表分析来自文献3)
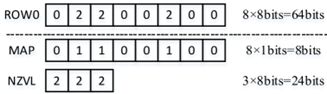
图7. 稀疏数据图编码案例(图表分析来自文献3)
3. 逼近计算之设计挑战
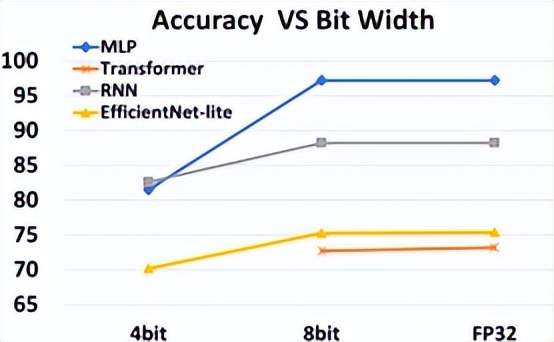
图8. 算法模型与量化表征的关系案例(图表分析来自文献6)
算法模型与量化表征的关系案例如图8所示,逼近计算设计可以通过算法模型的低比特参数表征+量化后训练的方式,在不降低算法模型精度的情况下,通过时间和空间复用的方式,等效增加低比特MAC PE单元。
逼近计算的另外一个优势是可以与稀疏计算相结合。低比特表征会增加数据的稀疏特性,类似ReLU等激活函数和池化计算也会产出大量零值数据。另外浮点数值如果用bit-slices进行表征,也会有大量高位零比特特征。
零值输出数据意味着可以通过预计算可以直接跳过后续大量的卷积计算等。如图9所示的案例,其中简单的bit-slice数据分解表征会产生偏置分布,可以通过Signed Bit-Slice方法来解决,从而将PPA性能有效提升到(x4能耗,x5性能,x4面积)。

图9. Signed Bit-Slice和RLE游程编码案例 (图表分析来自文献4)
4. 内存计算之设计挑战
ADS-NPU设计其中有一个挑战是数据墙问题能耗墙问题,即计算单元PE存算分离设计导致数据重复搬移,数据共享困难,数据通道与计算通道峰值能力不匹配会导致PE的低效率和SRAM/DRAM高能耗。
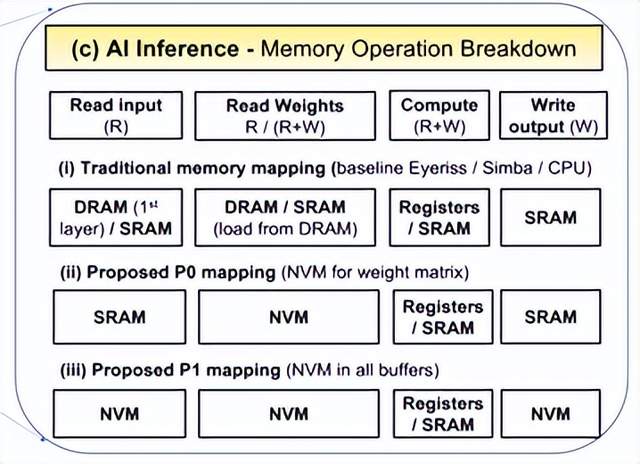
图10. MRAM取代SRAM案例 (图表分析来自文献5)
一个有趣的尝试是用新型工艺MRAM (STT/SOT/VGSOT-MRAM) 来部分或全部取代SRAM, P0方案是只取代算法模型参数缓存和全局参数缓存;P1方案是MRAM全面取代SRAM。对比SRAM-only架构,从图10 的案例可以看出MRAM-P0解决方案可以有>30%能耗提升,MRAM-P1解决方案有>80%能耗提升,芯片面积减少>30%。

图11. Von Neumann与内存计算的架构对比 (图表分析来自文献6)

图12. 内存计算的模拟墙问题 (图表分析来自文献6)
当前初创公司的内存计算架构策略需要对内存cell添加数据计算逻辑,通过采用ReRAM或者STT-MRAM新型工艺,采用模拟或数字类型的设计来实现。模拟内存计算IMC对打破传统的Von Neumann计算机架构内存墙和能耗墙应该更有优势,但需要同时打破设计中的模拟墙问题,这也是当前数字设计IMC-SRAM或者IMC-MRAM占多数的原因。
如图11和图12所示,IMC的主要问题来自于模数转换ADC/DAC接口和激活函数的接口带来的设计冗余。一种新的实验设计是用基于RRAM的RFIMC微架构(RRAM cells + CLAMP circuits + JQNL-ADCs + DTACs)。每个RRAM cell代表2比特内存数据,4个RAM cell来存储8比特的权重,JQNL-ADC采用8比特浮点数。
从图13可以看出RFIMC的微架构能够部分解决模拟墙的问题,可实现>100TOPS/Watt的PPA性能,但存在的问题是,只支持小规模的全矢量矩阵乘,超大尺寸的矩阵乘,需要将模拟数据进行局部搬移,是否有数据墙的问题仍未知。

图13. RFIMC的性能分解图 (图表分析来自文献6)
5. 算法-硬件之共同设计挑战
ADS算法多样化的演进趋势和对NPU大算力存算的混合需求,需要算法-NPU联合设计来实现模型整体效率。
常用的量化与模型裁剪能够解决一部分问题,模型-硬件联合搜索,可以认为NPU预定义的硬件架构是模板,网络模型ASIC-NAS是一个典型的案例,即在有限硬件计算空间内进行DNN的模型搜索和模型小型化,寻求计算单元的最佳组合模型来提升相同计算复杂度下的等效算力效率。
NPU添加了硬件的可配置和细颗粒可调度,但依旧存在很大的性能约束性。如图14 和图15所示,SkyNet算法与硬件共同设计的案例,是将NPU细颗粒度的PE单元进行Bundle优化封装,其价值在于可以降低NAS架构搜索的高维空间,从而减低对硬件底层架构的依赖关系和优化算法的复杂度。
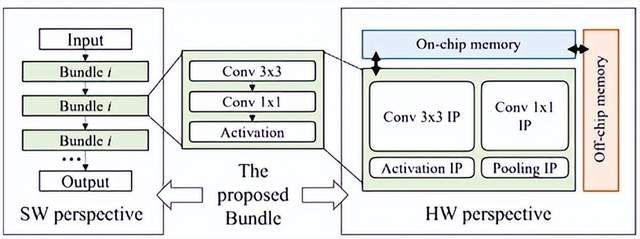
图14. SkyNet算法与硬件共同设计案例 (图表分析来自文献7)
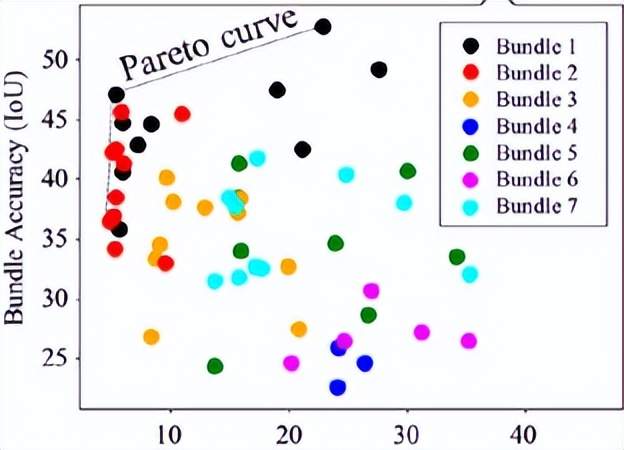
图15. SkyNet-Bundle-NAS示例 (图表分析来自文献7)
作者 | Dr. L. Luo
参考文献:
【1】J. Kim, and etc., “Exploration of Systolic-Vector Architecture with Resource Scheduling for Dynamic ML Workloads”,
https://arxiv.org/pdf/2206.03060.pdf
【2】M Davies, and etc., “Understanding the limits of Conventional Hardware Architectures for Deep-Learning”,
https://arxiv.org/pdf/2112.02204.pdf
【3】C. Wu, and etc., “Reconfigurable DL accelerator Hardware Architecture Design for Sparse CNN”,
https://ieeexplore.ieee.org/document/9602959
【4】D. Im, and etc., “Energy-efficient Dense DNN Acceleration with Signed Bit-slice Architecture”,
https://arxiv.org/pdf/2203.07679.pdf
【5】V Parmar, and etc., “Memory-Oriented Design-Space Exploration of Edge-AI Hardware for XR Applications”,
https://arxiv.org/pdf/2206.06780.pdf
【6】Z Xuan,and etc., “High-Efficiency Data Conversion Interface for Reconfigurable
Function-in-MemoryComputing”,
https://ieeexplore.ieee.org/document/9795103
【7】X Zhang, and etc., “Algorithm/Accelerator Co-Design and Co-Search for Edge AI”,
https://ieeexplore.ieee.org/document/9785599