小 T 导读:兴盛优选需要通过实时产生的数据来判断设备是否工作、检测通讯是否延时、观测 SNMP OID 流量是否正常等,从而保障运维与网络人员及时发现问题并修复。为高效处理各类时序数据,保障服务的稳定运行,在对比了 Elasticsearch、InfluxDB 和 TDengine 三款产品之后,他们选择并落地了 TDengine。

企业介绍
湖南兴盛优选电子商务有限公司(简称兴盛优选),总部位于湖南长沙,是一家关注民生的互联网“新零售”平台,主要定位是解决家庭消费者的日常需求,提供包括蔬菜水果、肉禽水产、米面粮油、日用百货等全品类精选商品。兴盛优选依托社区实体便利店,通过“预售+自提”的模式为用户提供服务,是社区电商中唯一一家估值超过 150 亿美金的“独角兽”。
业务背景
为了保证互联网服务的高效和稳定,我们需要监控公司所有的节点服务器(包括云服务器)、交换机及路由器。我们需要通过实时产生的数据来判断设备是否工作、检测通讯是否延时、观测 SNMP OID 流量是否正常等,从而保障运维与网络人员及时发现问题并修复。
这类数据是非常典型的时序数据,应该如何高效地处理呢?现在市面上有几款非常流行的时序数据库(Time Series Database)产品。应该如何评估并选择适合我们业务场景的技术平台呢?
产品调研
针对该业务场景,我们调研了如下几个产品:Elasticsearch、InfluxDB 和 TDengine。具体对比如下。
Elasticsearch
- 优点:可以分布式部署,可以无障碍插入,支持任意的字段类型,查询速度快。
- 缺点:只适合记录日志且并发数据量不大的情况,对于海量设备的时序数据写入有性能问题。
InfluxDB
- 优点:支持无模式(Schemaless 写入),限制较少。
- 缺点:当面对大批量的数据同时插入或读取时,内存容易被占满,导致死机。尤其是其中的轮询机制,在检验过期数据时,内存占用特别大。此外,在读取数据时,读出来的是列表,可读性差,解析比较麻烦。
TDengine
- 优点:列式存储以及“一个设备一张表”的模型与我们业务场景十分契合。此外,还可以兼容我们以前使用 InfluxDB 时所习惯的插入方式,代码可读性强,支持强绑定参数。在执行海量数据的查询时,响应速度比 InfluxDB 更快。
- 缺点:Schemeless 的支持还在持续完善之中。
由于该项目未来需要监控我们公司的所有服务器,平均每台对应的 OID 会有几百个,如果每 1-5 秒采集存储一次,并发数据量会非常大。因此,我们从候选中淘汰了 Elasticsearch。
接下来我们又继续对比了 InfluxDB 和 TDengine。InfluxDB 单节点性能不足,集群闭源且性能未知。反观 TDengine,其集群功能是开源的,且保留了企业版的部分核心功能。这让我们可以直接非常深入地了解 TDengine 的优劣。从这方面考虑,我们选择了 TDengine。而且在实际使用中,我们又发现了 TDengine 的一大优势,其“一个设备一张表”的模型十分契合我们的实际场景。
系统架构
在引入 TDengine 之后,我们的系统架构如下图所示。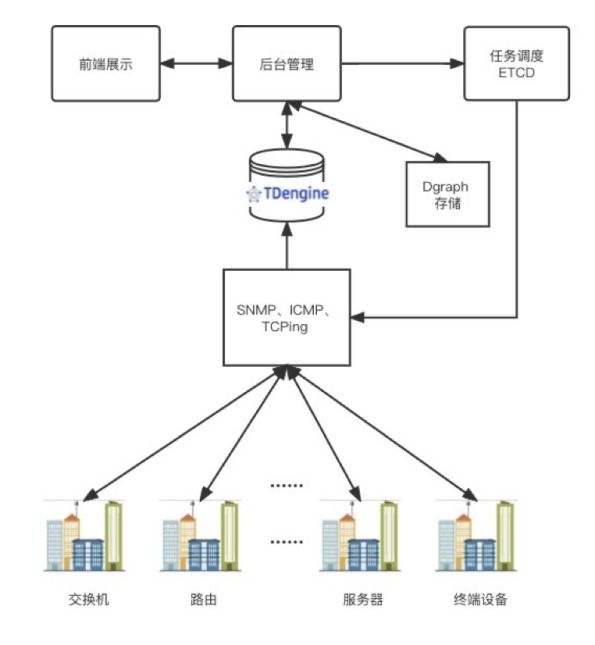
在该架构下,前端制定好规则下发(例如:流量阈值,延时阈值),后端看是否需要存储规则,或检查规则是否发生变化,然后把规则下发给 ETCD 来做定时任务调度。我们共有三个程序任务,通过 ETCD 管理,定时和各类设备通信,根据不同规则分别抓取各自需要的数据:
- SNMP 引擎通过 OID 监控网络设备各项指标
- TCPing 引擎用于监控服务器 TCP 端口状态
- ICMP 引擎重点采集接收或返回数据的时间
这三大类数据采集之后,会经过统一处理,再写入 TDengine。
我们使用 5 个节点搭建了一套 TDengine 集群:
我们选择了无模式写入,在写入时自动建表,具体写入方式可参考官网。这样一来,每一台服务器对应的类型都是一张超级表,我们选择尽量地分表 ,提升查询速度。
对于 SNMP 类型的超级表来说,每一个子表就是一个 OID。对于 TCPing 类型,我们按照 TCP 端口来区分子表。对于 ICMP 类型的超级表,我们以 task_id 和 task_type 作为区分子表的依据:
目前我们已经存储了 500 万张子表,平均算下来设备上报频率大概为 3 秒 1 行,总数据量达到了百亿级别,而占用的存储空间只有 70GB 左右。这应该得益于 TDengine 针对性地使用了列式压缩,存储资源占用很小,压缩率大概为 8% 左右。TDengine 可以很好地顶住写入和存储压力。而查询方面,我们会批量查询部分表的特定时间的值,大部分数据用于实时的监控报警。

经验总结
在使用过程中,花时间相对较多的大概是无模式插入的摸索吧。
对于从 InfluxDB 切换过来的用户,初期可能会有一些不适应。因为 TDengine 最初并不是按照 Schemaless 来设计的,这个功能是后期加入的,系统最终还是会把无模式转化成 SQL 再进行写入,只是简化了用户的操作。不过 TDengine 一直在完善相关的生态适配,比如对于大小写的特殊字符的存储,完善元数据管理,收纳各种形式的数据类型,也在逐步向 InfluxDB 的自由式写入靠近。
除此之外,我们也遇到过一个问题,目前 Go 连接器的查询 API 暂时不支持将多条 SQL 拼接在一起统一执行。因此我们采取了并发读取,但性能可能会受到一点影响,期待后续的版本能够解决。
最后,TDengine 的支持团队相当负责,配合积极,让我们快速上手了这款轻便易用、性能超高的时序数据库。目前我们只接入了一部分服务器及设备,后续我们计划把公司全国范围内所有的服务器都接入进来,也会推荐公司更多部门使用。一切顺利的话,我们也会考虑包括仓库运货机器人,物流线设备等更多应用场景。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。