何恺明团队新作:只用普通ViT,不做分层设计也能搞定目标检测
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
微软的Swin Transformer去年横空出世,一举突破了Transformer做视觉任务复杂度过高的问题。
这种把Transformer“卷积网络”化的做法,也成为当前ViT研究领域的热门方向。
但现在,何恺明团队的最新论文提出了不同的观点:
在目标检测任务上,像Swin Transformer那样的复杂操作可能是没有必要的。
只用普通ViT做骨干网络,一样能在目标检测任务上拿下高分。

不对ViT引入分层设计
ViT可以说是打开了Transformer跨界处理视觉任务的新大门。
但原始ViT的问题在于,它是一个非层次化的架构。也就是说,ViT只有一个单一尺度的特征图。
于是在目标检测这样的任务中,ViT就面临着两个问题:
其一,如何在下游任务中用预训练好的骨干网络来处理好各种大小不同的物体?
其二,全局注意力机制的复杂度与输入图像尺寸的平方呈正比,在面对高分辨率图像时,处理效率低下。
以Swin Transformer为代表,给出的解决方案是向CNN学习,将分层设计重新引入骨干网络:
基于分层特征图,利用特征金字塔网络(FPN)或U-Net等技术进行密集预测
将自注意力计算限制在不重叠的局部窗口中,同时允许跨窗口连接,从而带来更高的效率。
而何恺明团队的这篇新论文,则试图寻找一个新的突破方向。
其核心,是放弃FPN设计。
具体而言,研究人员通过对ViT的最后一层特征图进行卷积或反卷积,得到了多尺度特征图,从而重建出一个简单的FPN。

相比于标准特征金字塔通过bottom-up、top-down和lateral connection做特征融合的方法,可以说得上是简单粗暴。
另外,在对高分辨率图像进行特征提取时,研究人员也采用了窗口注意力机制,但没有选择像Swin Transformer那样做shift。
在进行信息交互时,他们将block均分为四个部分,探索了两种策略:全局传播和卷积传播。
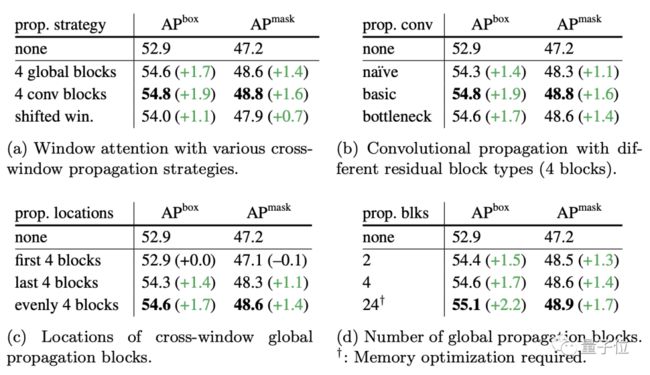
从表格中可以看出,采用4个卷积块(conv block)的效果是最好的。
这种新方法被命名为ViTDet。
论文还提到,结合MAE方法进行预训练,效果更好。
从实验结果来看,以ViT作为骨干网络的方法,在模型较大时,展现出了比Swin、MVITv2等采用分层策略的方法更优的性能。

研究人员表示:
使用普通ViT作为骨干网络,基于MAE方法进行预训练,由此得到的ViTDet能与之前所有基于分层骨干网络的先进方法竞争。
关于作者
Yanghao Li,本硕毕业于北京大学,现在在Facebook AI研究院担任研究工程师。
Hanzi Mao,本硕毕业于华中科技大学,2020年在德州农工大学拿到博士学位,现为Facebook AI研究院高级研究科学家。
另外,除了何恺明,Ross Girshick大神也坐镇了这篇论文。
论文地址:
https://arxiv.org/abs/2203.16527
— 完 —


点个在看 paper不断!