论文阅读-多任务(2021)-YOLOP:用于自动驾驶目标检测与语义分割的实时多任务模型
YOLOP
论文:YOLOP: You Only Look Once for Panoptic Driving Perception
地址:https://paperswithcode.com/paper/yolop-you-only-look-once-for-panoptic-driving

论文阅读
YOLOP同时处理三项视觉感知任务+实时速度运行(Jetson TX2-23FPS)+保持较高精度
关于方法详情,如下图所示,全景驾驶场景感知网络YOLOP包括一个共享的编码器和三个特定的解码器处理不同任务,解码器之间没有复杂的共享机制,保证网络的端到端高效训练。
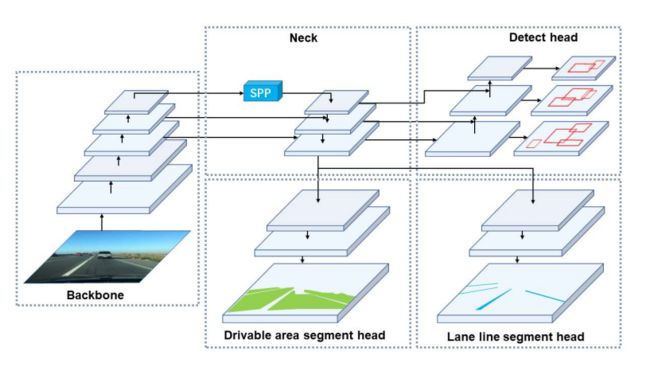
对于编码器,包含一个主干和一个neck,其中主干网络用于提取输入图像的特征,通常是选用图像分类网络,但是论文受YOLOv4的启发选用了CSPDarknet来作为主干,该主干有效解决了优化过程的梯度冗余问题,支持特征的高效传播和服用,满足模型对于实时的要求。
对于Neck,起作用在于融合主干网络生成的特征,YOLOP的neck由空间金字塔池化模块SPP和特征金字塔网络FPN组成。SPP生成并融合不同尺度的特征,FPN则融合不同语义层级的特征,使得生成的特征包含多尺度和多个语义层级的信息。
对于解码器,有三个,分别是交通目标检测头、可通行区域分割头和车道线分割头,后两者使用结构相同的分割头。
对于检测头,和YOLOv4相同,采用基于anchor的多尺度检测策略。首先使用通路聚合网络PAN(自底而上的特征金字塔网络)。FPN自顶而下传递语义特征,PAN自底而上传递位置特征,论文将二者结合以便产生更好的特征融合效果,之后直接在PAN种使用融合有多尺度信息的特征图进行检测。然后每个多尺度特征图的grid都会标记三个不同比例的先验框,然后检测头对位置偏移量、框尺寸以及类别标签进行预测。
对于分割头,论文奖FPN的输出( W / 8 , H / 8 , 256 W/8,H/8,256 W/8,H/8,256)直接灌给分割头,经过三次三次上采样后输出预测结果 ( W , H , 2 ) (W,H,2) (W,H,2),因为SPP模块已经在共享的neck种一个用,这里不需要额外的SPP模块。
训练目标
对于损失函数,检测头的损失函数:
L d e t = α 1 L c l a s s + α 2 L o b j + α 3 L b o x L_{det}=\alpha_1 L_{class}+\alpha_2 L_{obj}+\alpha_3 L_{box} Ldet=α1Lclass+α2Lobj+α3Lbox
其中前两者都是focal loss,使得网络更多关注难样本,第三个是 L C I o U L_{CIoU} LCIoU,该损失考虑了Pred和GT之间的距离、重叠率、anchor尺寸和比例.
分割头的损失有两个即可通行区域分割头损失 L d a − s e g L_{da-seg} Lda−seg和车道线分割损失 L l l − s e g L_{ll-seg} Lll−seg,二者都包含一个交叉熵损失 L c e L_{ce} Lce用于最小化Pred和GT之间的像素分类误差,道路损失还额外包含一个IoU损失 L I o U = T N T N + F P + F N L_{IoU}=\frac{TN}{TN+FP+FN} LIoU=TN+FP+FNTN。
最终模型的损失是一个带权复合损失:
L a l l = γ 1 L d e t + γ 2 L d a s e g + γ 3 L l l − s e g L_{all}=\gamma_1 L_{det}+\gamma_2 L_{da_seg}+\gamma_3 L_{ll-seg} Lall=γ1Ldet+γ2Ldaseg+γ3Lll−seg
训练的时候,先冻结模型其他部分权重,只训练编码器和检测头,然后冻结主干和检测头训练两个分割头,最终整个网络联合训练。
欢迎扫描二维码关注微信公众号 深度学习与数学 ,每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾。
