【毕业设计】基于HMM隐马尔科夫的股票预测 - 机器学习 股票预测 python
文章目录
- 0 前言
- 1 马尔科夫链
- 2 隐马尔科夫模型
- 3 HMM预测股票
0 前言
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
HMM隐马尔科夫模型及股票预测
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/kaaxuu/warehouse-seven-warehouse/blob/master/java/README.md
1 马尔科夫链
隐马尔科夫模型是自然语言处理中很重要的一种算法。在此之前,我们首先给大家介绍马尔科夫链。马尔科夫链,因安德烈·马尔科夫得名,是指数学中具有马尔科夫性质的离散事件的随机过程。在给定当前知识或信息的情况下,过去对于预测未来是无关的。每个状态的转移只依赖于之前的N个状态,这个过程被称为1个n阶的模型。其中n是影响转移状态的数目。最简单的马尔科夫过程就是一阶过程,每一个状态的转移只依赖于其之前的哪一个状态。用数学的表达式表示就是如下所示:
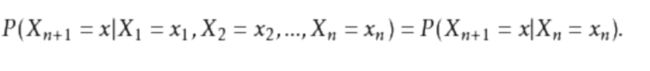
假设天气服从马尔科夫链:
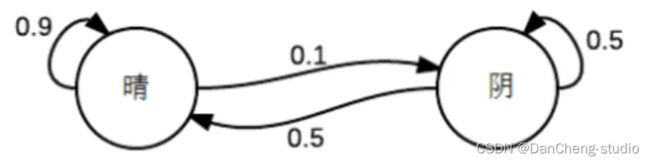
转移矩阵
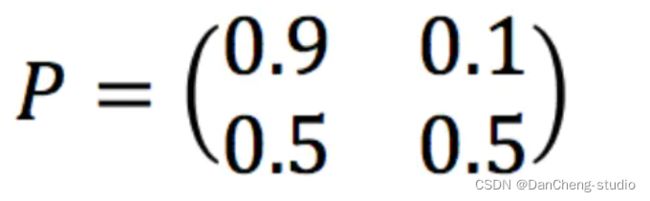
那么,从今天开始,在遥远的未来的某天,晴阴的概率分布是什么?
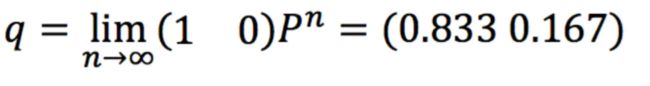
其实,不管是今天是晴天,还是阴天,其实很多天之后的晴阴分布收敛到一个固定分布。这个固定分布就是我们熟悉的稳态分布。因此,我们就为上面的一阶马尔科夫过程定义一以下三个部分:
- 1、状态:晴天、阴天
- 2、初始向量:定义系统在时间为0的时候的状态概率
- 3、状态转移矩阵:每种天气转换的概率。所有的能被这样描述的系统就是一个马尔科夫过程。
但是
以上出现一个明显的缺陷,也就是前后关系的缺失,带来了信息的缺失:例如我们经常玩的股市,如果只是观测市场,我们只能知道当天的价格,成交量等信息,但是并不知道当前的股市是处于什么状态。
在这种情况下我们有两个状态集合,一个是可以观察到的状态集合;另一个是一个隐藏的状态集合。我们希望能够找到一个算法可以根据股市价格的成交量状况和马尔科夫假设来预测股市的状况。基于上面我们提到的情况下,我们可以观察到状态序列和隐藏的状态序列是概率相关的。因此,我们可以将这种类型的过程建模为一个有隐藏的马尔科夫过程和一个与这个隐马尔科夫过程概率相关的并且可以观察到的状态集合,这就是我们今天要介绍的隐马尔科夫模型(HMM)。
接下学长来为大家详细介绍隐马尔科夫模型。
2 隐马尔科夫模型
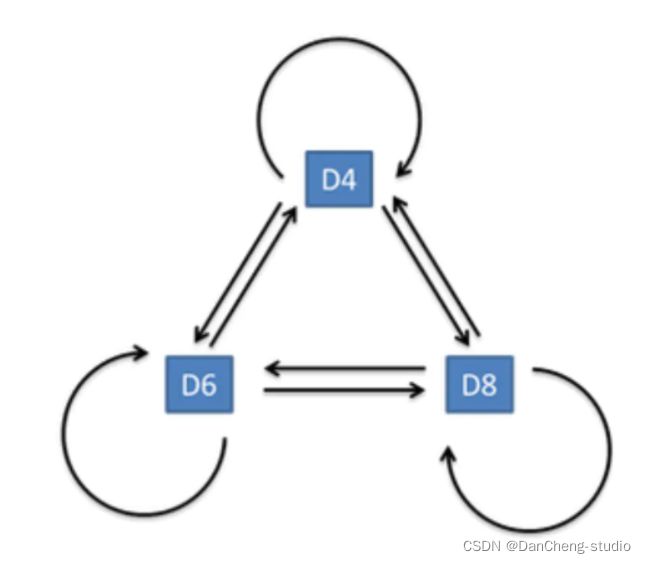
隐马尔科夫模型是一种统计模型,用来描述一个含有隐含层未知参数的马尔科夫过程。但是其中最大的难点就是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步分析。我们以日常的投骰子为例来解释隐马尔科夫模型:假设有三个不同的骰子(6面、4面、8面),每次先从三个骰子里面选择一个,每个骰子选中的概率为1/3,如下图所示,重复上述过程,得到一串数值[1,6,3,5,2,7]。这些可观测变量组成可观测状态链。同时,在隐马尔可夫模型中还有一条由隐变量组成的隐含状态链,在本例中即骰子的序列。比如得到这串数字骰子的序列可能为[D6, D8, D8, D6, D4, D8]。
具体如下:
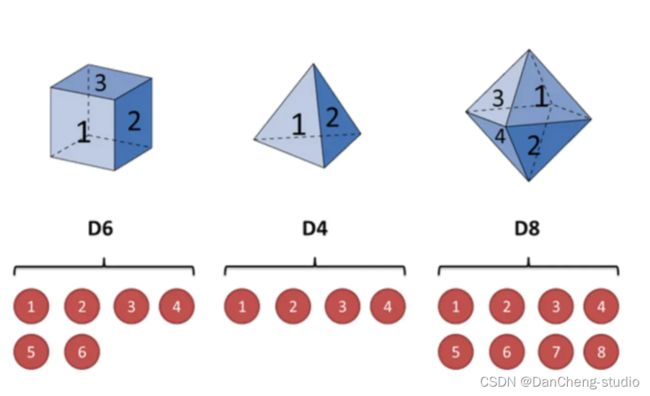
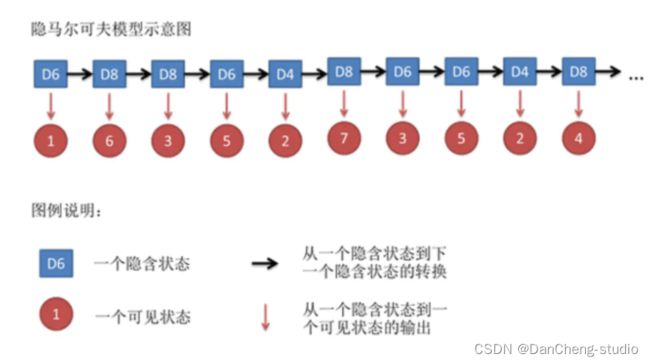
隐含状态转换示意图
3 HMM预测股票
这次使用HMM算法来进行股票预测,使用昨天的股票数据来预测今天是否涨跌。
import tushare as ts
token = '' # 设置tocken
pro = ts.pro_api(token) # 初始化pro接口
# 获取数据
df_gldq = pro.daily(ts_code='000651.sz', start_date='20201210', end_date='20210513')
df_gldq.sort_values(by='trade_date', inplace=True)
# 打印数据
df_gldq.to_excel('data/stock.xls')
首先使用tushare模块来获取数据。token是自己获取的,ts_code决定哪支股票,还有时间区间以及排序,最后写入stock.xls文件中。
#数据处理
df = pd.read_excel("data/stock.xls")
print("原始数据的大小:", df.shape)
print("原始数据的列名", df.columns)
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.reset_index(inplace=True, drop=False)
df.drop(['index', 'ts_code', 'open', 'high', 'low' , 'pre_close', 'change', 'pct_chg', 'amount'], axis=1, inplace=True)
#df['trade_date'] = df['trade_date'].apply(datetime.datetime.toordinal)
print(df.head())
dates = df['trade_date'][1:]
close_v = df['close']
volume = df['vol'][1:]
diff = np.diff(close_v)
#获得输入数据
X = np.column_stack([diff, volume])
print("输入数据的大小:", X.shape) #(1504, 2)
min = X.mean(axis=0)[0] - 8*X.std(axis=0)[0] #最小值
max = X.mean(axis=0)[0] + 8*X.std(axis=0)[0] #最大值
X = pd.DataFrame(X)
#异常值设为均值
for i in range(len(X)): #dataframe的遍历
if (X.loc[i, 0]< min) | (X.loc[i, 0] > max):
X.loc[i, 0] = X.mean(axis=0)[0]
#数据集的划分
X_Test = X.iloc[:-30]
X_Pre = X.iloc[-30:]
print("训练集的大小:", X_Test.shape) #(1474, 2)
print("测试集的大小:", X_Pre.shape) #(30, 2)
接下来是数据的预处理。获取特征因子与标签,归一化、异常值处理、数据集划分等等。
model = GaussianHMM(n_components=8, covariance_type='diag', n_iter=1000, min_covar=0.1)
model.fit(X_Test)
expected_returns_volumes = np.dot(model.transmat_, model.means_)
expected_returns = expected_returns_volumes[:,0]
predicted_price = [] #预测值
current_price = close_v.iloc[-30]
for i in range(len(X_Pre)):
hidden_states = model.predict(X_Pre.iloc[i].values.reshape(1,2)) #将预测的第一组作为初始值
predicted_price.append(current_price+expected_returns[hidden_states])
current_price = predicted_price[i]
然后是利用HMM做股票预测
x = dates[-29: ]
y_act = close_v[-29:]
y_pre = pd.Series(predicted_price[:-1])
plt.figure(figsize=(8,6))
plt.plot_date(x, y_act,linestyle="-",marker="None",color='g')
plt.plot_date(x, y_pre,linestyle="-",marker="None",color='r')
plt.legend(['Actual', 'Predicted'])
plt.show()
将预测股票走势折线图与股票真实折线图做对比
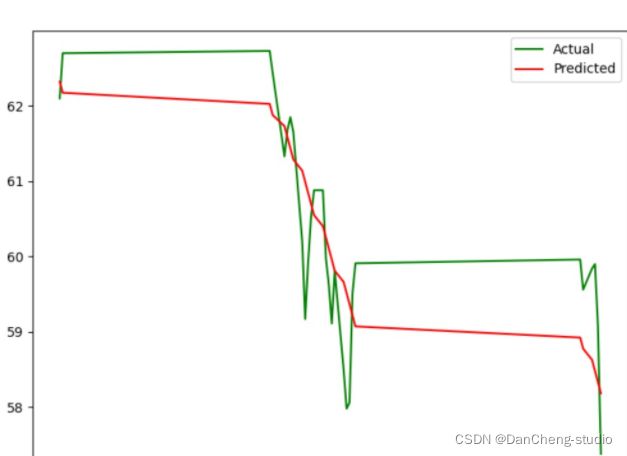
可以看出预测的股票曲线虽然无法完全拟合真实股票走势,但是大体的趋势是一致的。另外值得一提的是,很多股票预测实验预测值与真实值贴的很紧密,这一般都是用今天的信息预测今天涨跌了,这种预测是无意义的。
选题指导, 项目分享:
https://gitee.com/kaaxuu/warehouse-seven-warehouse/blob/master/java/README.md