深度学习算法第三课——BP神经网络
1.什么是BP神经网络?
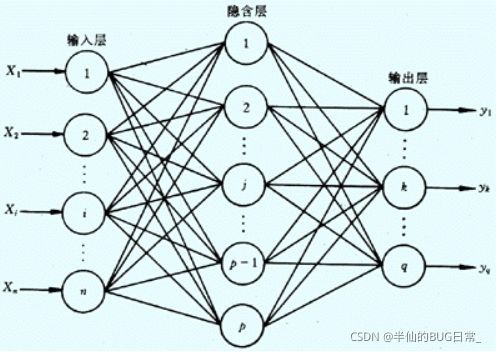
BP神经网络是一种多层前馈神经网络,主要特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出,则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出。结构如下:
2.梯度下降法
例:一元凸函数求极值
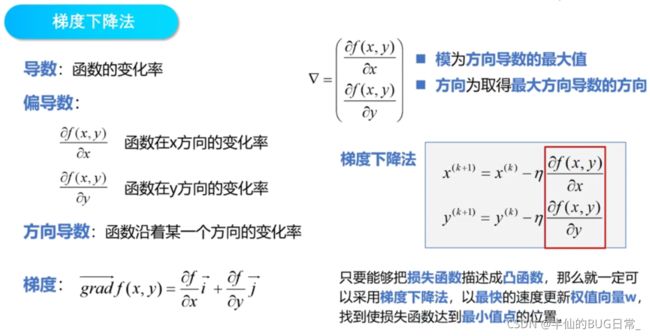
在距离极值点比较远的地方,步长的取值大一些,使得算法尽快收敛;在距离极值点比较近的地方,可以使步长逐渐减小,避免跨过极小值点,造成震荡。可以发现,斜率越大的地方让步长越大,斜率越小的地方让步长越小,让步长与导数保持正比例关系(如图)。上标表示迭代次数。采用这种方法进行迭代,可以根据函数自身的斜率进行对函数步长的自适应调整。当![]() 时,导数为正,x^(k+1)变得更小,向原点的方向移动,反之亦然。
时,导数为正,x^(k+1)变得更小,向原点的方向移动,反之亦然。

例:二元凸函数求极值

3.举例
这是一个最简单的两层神经网络,他的输入层,隐含层,输出层都只有一个节点,激活函数采用Sigmoid函数。训练的过程就是将 输入网络中,通过学习算法,寻找合适的模型参数(
输入网络中,通过学习算法,寻找合适的模型参数( 、
、 ),使得输出的
),使得输出的![]() 与样本标签的数据一致。假设现在有一个样本,属性值x为1,便签值y为0.8,将其输入至神经网络当中:
与样本标签的数据一致。假设现在有一个样本,属性值x为1,便签值y为0.8,将其输入至神经网络当中:

- 设置模型参数初始值。
- 正向计算预测值。可以看到结果与标签值误差较大,所以要用误差调整网络参数,也就是训练网络。
- 计算误差。使用平方损失函数计算出预测值与标签值得误差。
- 误差反向传播。对损失函数的梯度信息进行反向传播,同时更新所有的模型参数。首先更新输出层参数。
接下来再使用新的参数逐层正向计算,如此循环,知道误差收敛到一个理想的值。
如果隐含层中有多个神经元,那么误差项就会根据不同神经元得权值进行反向传播。
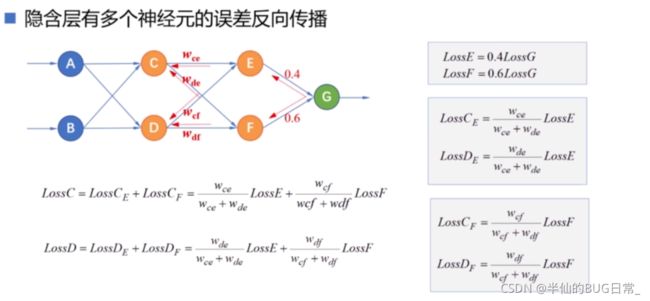
如果输出层中有多个神经元,继续按照权值比例逐层反向传播误差。

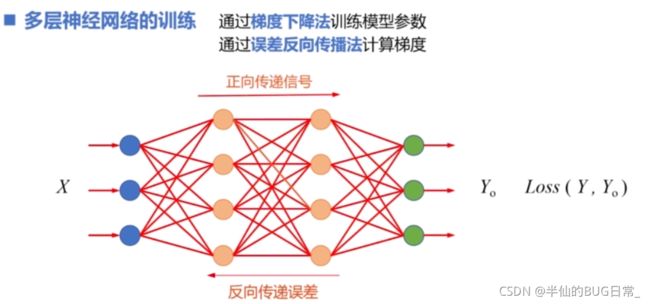
训练的过程可以概括为,首先在输入层输入样本特征 ,然后再神经网络中逐层传递,最后在输出层输出预测值
,然后再神经网络中逐层传递,最后在输出层输出预测值![]() ,将神经网络输出的预测值与标签值比较并计算损失Loss(Y,Yo)。如果损失比较大,就是用梯度下降法调整最后一层神经元的参数,然后反向传播梯度信息,逐层后退,更新模型参数,完成一轮训练。参数调整后的网络再次根据样本特征,正向传播预测值,反向传播误差,调整模型参数。通过这样不断的训练,直到网络输出与标签值一致。
,将神经网络输出的预测值与标签值比较并计算损失Loss(Y,Yo)。如果损失比较大,就是用梯度下降法调整最后一层神经元的参数,然后反向传播梯度信息,逐层后退,更新模型参数,完成一轮训练。参数调整后的网络再次根据样本特征,正向传播预测值,反向传播误差,调整模型参数。通过这样不断的训练,直到网络输出与标签值一致。
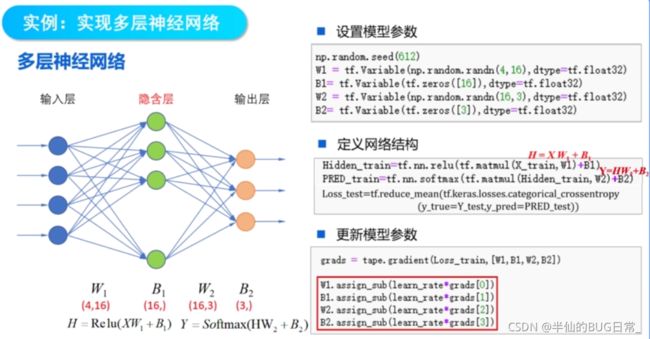
4.实例:多层神经网络实现鸢尾花分类
#1.导入库,设置GPU模式
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#2.分别加载训练集和测试集数据,并将他们转化为numpy数组
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1],TEST_URL)
df_iris_train = pd.read_csv(train_path,header=0)
df_iris_test = pd.read_csv(test_path,header=0)
iris_train = np.array(df_iris_train)
iris_test = np.array(df_iris_test)
iris_train.shape,iris_test.shape
#3.数据预处理
x_train = iris_train[:,0:4]
y_train = iris_train[:,4]
x_test = iris_test[:,0:4]
y_test = iris_test[:,4]
x_train = x_train-np.mean(x_train,axis=0)
x_test = x_test-np.mean(x_test,axis=0)
#4.设置超参数和显示间隔
learn_rate = 0.5 #学习率
iter = 50
display_step = 10
#5.设置模型参数的初始值
np.random.seed(612)
W1 = tf.Variable(np.random.randn(4,16),dtype=tf.float32)
B1 = tf.Variable(tf.zeros([16]),dtype=tf.float32)
W2 = tf.Variable(np.random.randn(16,3),dtype=tf.float32)
B2 = tf.Variable(tf.zeros([3]),dtype=tf.float32)
#6.训练模型
#定义四个空的列表用来存放训练过程中的准确率和损失
acc_train=[]
acc_test=[]
cce_train=[]
cce_test=[]
for i in range(0,iter+1):
with tf.GradientTape() as tape:
Hidden_train = tf.nn.relu(tf.matmul(X_train,W1)+B1)
PRED_train = tf.nn.softmax(tf.matmul(Hidden_train,W2)+B2)
Loss_train=tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train))
Hidden_test = tf.nn.relu(tf.matmul(X_test,W1)+B1)
PRED_test = tf.nn.softmax(tf.matmul(Hidden_test,W2)+B2)
Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=PRED_test))
accuracy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train.numpy(),axis=1),y_train,tf.float32)))
accuracy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test.numpy(),axis=1),y_test),tf.float32))
acc_train.append(accuracy_train)
acc_test.append(accuracy_test)
cce_train.append(Loss_train)
cce_test.append(Loss_test)
grads = tape.gradient(Loss_train,[W1,B1,W2,B2])
W1.assign_sub(learn_rate * grads[0])
B1.assign_sub(learn_rate * grads[1])
W2.assign_sub(learn_rate * grads[2])
B2.assign_sub(learn_rate * grads[3])
if i % display_step ==0:
print("i: %i, TrainAcc:%f, TrainLoss:%f, TestAcc:%f, TestLoss: %f" % (i,accuracy_train,Loss_train,accuracy_test,Loss_test))
#7.结果可视化
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(cce_train,color="blue",lable="train")
plt.plot(cce_test,color="red",lable="test")
plt.xlabel("迭代次数")
plt.ylabel("损失")
plt.legend()
plt.subplot(122)
plt.plot(acc_train,color="blue",lable="train")
plt.plot(acc_test,color="red",lable="test")
plt.xlabel("迭代次数")
plt.ylabel("精确度")
plt.legend()
plt.show()