ACL2022文章
上一周做了标准(中文)的文本简单处理和图谱搭建,在整个过程中,用到了如下知识点:
PDF处理、关键词抽取、训练数据构建、模型训练等等。
但由于,才疏学浅,很多东西都是一知半解,所以,就捋来了ACL2022的文章,选取了几篇可能会用到和有趣的文章来读。
链接:https://zhuanlan.zhihu.com/p/501680110
实体消歧:
实体消歧和实体链接是联系比较紧密的,实体消歧是识别实体mention真正指向的实体。即实体指称项的识别。
CCKS2019的解决方案:https://github.com/panchunguang/ccks_baidu_entity_link
目录
- ExtEnD: Extractive Entity Disambiguation
-
- 实体消歧的现有技术方案:
- 实体消歧建模方案:
-
- 生成任务:
- 多分类任务
- 抽取任务:
- EXTEND模型
- Ablation Study:
- Error Analysis
- Good Examples Make A Faster Learner Simple Demonstration-based Learning for Low-resource NER
-
- 基于实体导向的方法:
- 基于实例导向的方法:
- template 的表示(e 是实体,l是实体的label):
- ILDAE: Instance-Level Difficulty Analysis of Evaluation Data
-
- 评价数据的难度,可以应用的场景:
- 模型图:
- 研究点
- Training Data is More Valuable than You Think:A Simple and Effective Method by Retrieving from Training Data
-
- 论文思路
- 论文的模型图
- Text-to-Table: A New Way of Information Extraction
-
- 论文核心
- 在tradition transformer中,
- 在加入relation embedding后,
- seq2seq的建模如下(transformer解码部分,参考上文)
- 讨论部分
-
- 文本多样性
- 文本冗余
- 大表格
- 背景知识
- 推理
ExtEnD: Extractive Entity Disambiguation
Entity Disambiguation (ED),这项任务要求在给定文本cm中出现的提及m时,从一组候选e1, … … en中识别出正确的实体e∗
实体消歧的现有技术方案:
首先,实际的消歧只是通过独立的提及和实体向量之间的点乘来建模的,这可能无法捕捉到复杂的提及-实体互动(这一块,我也不太清楚,互动指的是什么??)。其次,从计算的角度来看,**实体是通过高维向量表示的,这些向量被缓存在一个预先计算的索引中。**因此,针对一个大的数据库进行分类有很大的内存成本,事实上,它与实体的数量成线性关系。除此之外,增加一个新的实体也需要修改索引本身。
实体消歧建模方案:
生成任务:
在自动回归的表述中,给定上下文中的提及,模型被训练为逐个令牌地生成正确的实体标识符。auto-regressive formulation
不足:(1)解码器,速度受限;(2)实体之间的相互作用,只能在波束搜素的回溯中间接发生。
多分类任务
给定实体候选集合,做多分类任务。
抽取任务:
给出一个提及m的语境cm,以及每个可能的候选者e1, …, en的文本表述作为输入。一个模型必须提取与最适合m的实体的文本表述相关的跨度。
(Given as input a context cm in which a mention m occurs, along with a text representation for each of the possible candidates e1, . . . , en, a model has to extract the span associated with the text representation of the entity that best suits m. )
建模形式:

input sentence,candidate set是有候选实体构成的。
然后,使用抽取模型,得到正确的span的start和end。
the knowledge base here is Wikipedia and the candidate text representations are Wikipedia page titles.
EXTEND模型
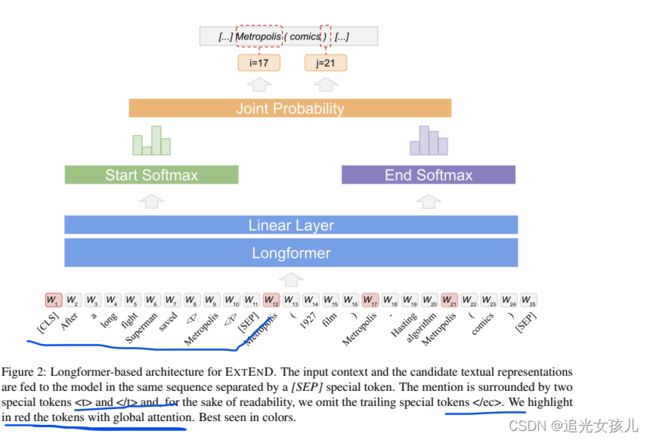
任务建模形式:给定一个query和context,模型需要抽取得到正确的span。
假设,m是mention,context是上下文,m的上下文表示为cm,则候选实体的context集合表示为:Cnd(m) = {cnd1, . . . , cndn}
然后,将ED建模为如下形式,将每个tuple (m,cm)和Cnd(m)作为query,xc是context。
模型的输入是:xq和xc,即query和context
**在query中,**将m所在位置的左右,用特殊标记 和标记。
在每个candidate之间,使用标记。
训练:对start和end的position位置的预测做loss计算,cross entropy loss
推断:选择Cnd中,start和end的概率分值都较高的,作为预测得到的span;即正确的实体。
补充:考虑到文本长度问题和transformer中的注意力机制的二次复杂度(影响计算效率),提出使用Longformer训练的BART作为PLM.
第二,提出将【CLS】和每个candidate 中的第一个token作为全局表征并激活的方法。
Ablation Study:
BART
Longformer
Error Analysis
无效的context。(上下文)
title 可能不足以作为candidate(这篇文章是把维基页面的title作为了mention的candidate)
Good Examples Make A Faster Learner Simple Demonstration-based Learning for Low-resource NER
这篇是在数据集的构建问题上,应该是算在Prompt learning范畴的。
核心是如何为instance构建demonstration.
基于实体导向的方法:
- random,随机选择
- popular select,选择在train set出现频次最高的
- search,选择在dev set中表现最好的.
基于实例导向的方法:
检索与input最相似的实例,添加到demonstration中。
相似度计算,则是采用cosine similarity
template 的表示(e 是实体,l是实体的label):
- no-context:e is l
- context:s,e is l
- lexical: s,但是要把s中e替换为对应的label.
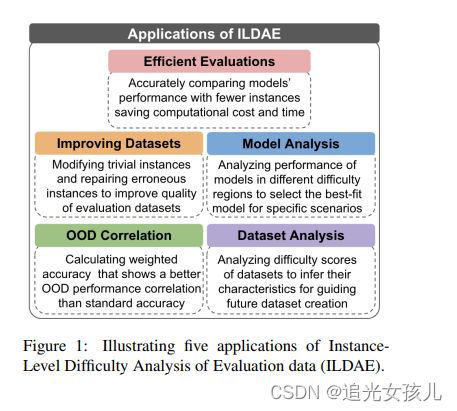
ILDAE: Instance-Level Difficulty Analysis of Evaluation Data
论文依旧是数据检索有关的,是通过评价数据的难度,找到合适的evaluation dataset。
目的是希望在轻量级的数据集上,达到和大量数据集相媲美的效果。
评价数据的难度,可以应用的场景:
Difficulty Score的计算
数据规模: we train a model each with 5, 10,15, 20, 25, 50, and 100 % of the total training examples
数据损坏程度: we train a model each with different levels of noise (2, 5, 10, 20,25% of the examples) in the training data
训练步数(在不同训练epoch下的checkpoint来计算难度):总共训练了N = E ∗(7+ 5) models,其中,7和5分别表示data size和data corruption。N表示训练的epoch,在论文中,取到了E=10,训练的模型总数是120个。
模型图:
1是使用全部数据得到的结果
2是使用计算的difficulty score,选取evaluation数据的过程。

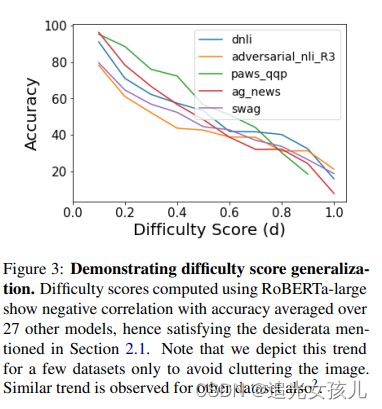
研究点
在不同数据集上,数据难度越大,模型效果越差。
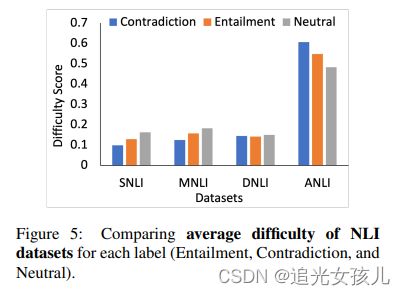
数据集的不同label下的数据难度。
根据难度,赋予数据weight和未赋予weight条件下,效果的比较。

Training Data is More Valuable than You Think:A Simple and Effective Method by Retrieving from Training Data
这篇文章还是在说数据的事,如何构建号的训练数据。
论文思路
大致思想是,检索出与输入文本最相似的有标签的训练实例,然后将它们与输入文本串联起来,输入到模型中,生成结果。
效果,可以达到的是,带有REINA的BART-base与BART-large相媲美,后者现在包含了两倍的参数。
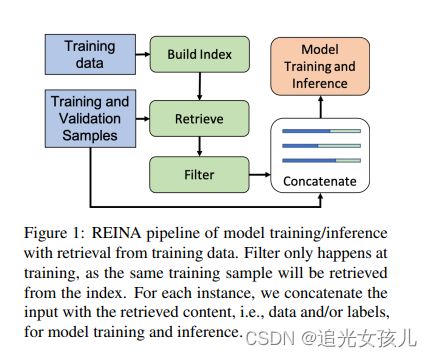
论文的模型图
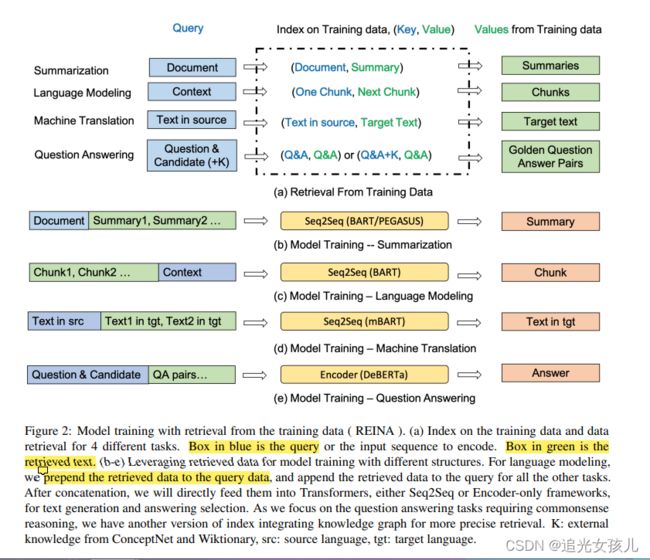
给定一个query,从训练数据中检索得到最相近的value,然后和最初的query(也就是input),做concat,作为模型的输入,完成整个任务。
检索分值评价:BM25score。
https://blog.csdn.net/Tink1995/article/details/104745144
模型输出结果:
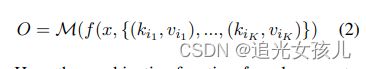
其中,模型的输入部分,f(x,{(),()})这一部分,是根据不同的任务,有所区别的。
在summary任务中,
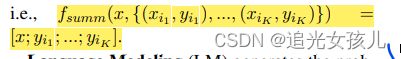
在language model中,

Text-to-Table: A New Way of Information Extraction
这篇文章是建模了新的任务,以往多是,table2text,这篇文章首次是text2table。
但这个过程会面临许多问题,比如,
数据集的问题
表格的建模问题
模型性能评价问题
论文核心
采用seq2seq的方式,微调预训练模型。
在表格产生过程,采用了两种额外的技术,table constraint 和 tabel relation embeddings。(表约束控制表中行的创建,表关系嵌入影响单元格及其行标题和列标题之间的对齐方式。)
我们的方法还将包括行关系嵌入和列关系嵌入在内的表关系嵌入纳入了Transformer解码器的自我关注。

在transformer计算中,relation vector被加进去了。
在tradition transformer中,

在加入relation embedding后,
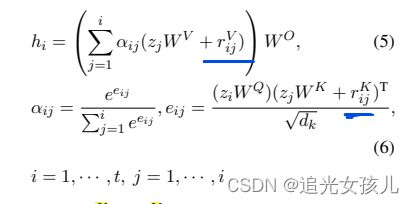
seq2seq的建模如下(transformer解码部分,参考上文)
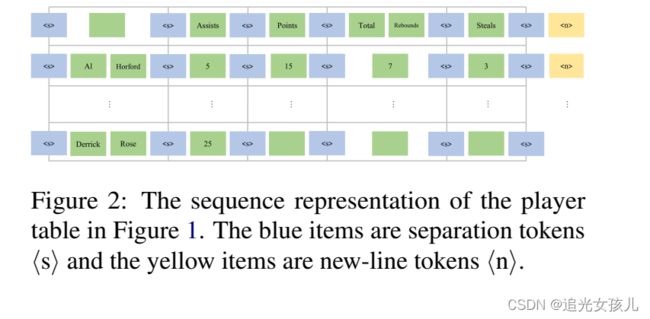
将输入文本text,输出为如下格式:
表示开头,表示行结束。
损失函数是:cross-entropy loss。

讨论部分
这部分,我觉得很有意思。是从几个方面做的分析。
文本多样性
从不同文本中抽取相同表述的内容是具有难度的
文本冗余
有像WikiBio这样的情况,其中文本包含大量冗余信息。
大表格
Rotowire 中的表有大量的列,即使对于我们使用 TC 和 TRE 的方法,从它们中提取也是具有挑战性的
背景知识
WikiTableText 和 WikiBio 来自开放领域。因此,在此类数据集上执行 text-to-table 需要使用大量背景知识。应对这一挑战的一种可能方法是使用更强大的预训练语言模型或外部知识库
推理
有时信息没有在文本中明确呈现,需要推理才能进行正确提取。例如,Rotowire 上的一篇文章报道了两支球队“网队”和“奇才队”之间的比赛。从一句话:“篮网从一开始就控制了这场比赛,首节后以31-14领先”,人类可以推断出“奇才”的得分是14分,这对于机器来说还是很难的