【机器学习-样例】聚类模型
文章目录
-
- 一、阶层式分群
- 二、Kmeans聚类
- 三、密度为基础聚类法DBSCAN
- 四、聚类结果评估
- 五、模型比较
- 六、案例-新闻主题聚类
階層式分群(hierarchical clustering)
聚合式階層分群法 Agglomerative Hierarchical Clustering
分裂式階層分群法 Divisive Hierarchical Clustering
最佳分群群數(Determining Optimal Clusters)
切割式分群(partitional clustering)
K-means
K-medoid
最佳分群群數(Determining Optimal Clusters)
譜分群(Spectral Clustering)
一、阶层式分群
- 点之间的距离:
欧式距离
曼哈顿距离
余弦距离 - 群之间距离:
单一连接聚合演算法
完整连接聚合演算法complete
平均连接聚合演算法
沃德法ward
1.阶层式分群-scipy.cluster.hierarchy
数据准备
from sklearn.datasets import load_iris
iris=load_iris()
数据建模
%matplotlib inline
import matplotlib.pyplot as plt
import scipy.cluster.hierarchy as sch
Z=sch.linkage(iris.data,method='ward')#层次聚类
dendrogram=sch.dendrogram(Z)#结果以树状图保存
plt.title('Dendrogram')
plt.xlabel('iris')
plt.ylabel('Euclidean distances')
plt.show()

2.阶层式分群-sklearn.cluster->AgglomerativeClustering
数据建模
from sklearn.cluster import AgglomerativeClustering
hc=AgglomerativeClustering(n_clusters=3,affinity='euclidean',linkage='ward')#设置3个分群,点距用欧式,群距用沃德法
y_hc=hc.fit_predict(iris.data)
plt.scatter(iris.data[y_hc == 0, 2], iris.data[y_hc == 0, 3], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(iris.data[y_hc == 1, 2], iris.data[y_hc == 1, 3], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(iris.data[y_hc == 2, 2], iris.data[y_hc == 2, 3], s = 100, c = 'green', label = 'Cluster 3')
plt.title('Clusters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
 3.阶层式分区特点
3.阶层式分区特点
可以产生可视化分群结果,可以等结构产生后,再进行分群,不用一开决定分多少群。
但是计算速度缓慢。
二、Kmeans聚类
1.K-means
将数据集分为K个群,数据点Xj到其对应群中心Cj的距离总和是最小的
需要先设定k值和原始点
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=3,init='k-means++',random_state=123)#k-means++初始点选择方法
y_kmeans=kmeans.fit_predict(iris.data)
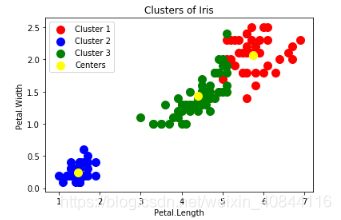
plt.scatter(iris.data[y_kmeans == 0, 2], iris.data[y_kmeans == 0, 3], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(iris.data[y_kmeans == 1, 2], iris.data[y_kmeans == 1, 3], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(iris.data[y_kmeans == 2, 2], iris.data[y_kmeans == 2, 3], s = 100, c = 'green', label = 'Cluster 3')
plt.title('Clusters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()

中心点
centers=kmeans.cluster_centers_#4列分别对应4个特征iris.feature_names
centers
>>>array([[6.85 , 3.07368421, 5.74210526, 2.07105263],
[5.006 , 3.418 , 1.464 , 0.244 ],
[5.9016129 , 2.7483871 , 4.39354839, 1.43387097]])
... ...
plt.scatter(centers[:,2],centers[:,3],s=100,c='yellow',label='Centers')
... ...
2.CASE:使用kmeansx进行客户属性分群
绘图函数
#绘图函数
def pain(y,k,colors,kmodel):
for i in range(k):
plt.scatter(X[y == i, 0], X[y == i, 1], s = 100, c =colors[i] , label ='Cluster %s'% (i+1))
plt.title('Clusters of customers')
plt.xlabel('Annual Income(k$)')
plt.ylabel('Spending Score (1-100)')
centers=kmodel.cluster_centers_
plt.scatter(centers[:,0],centers[:,1],s=100,c='yellow',label='Centers')
plt.legend()
plt.show()
数据准备
#客户分类
import pandas as pd
df=pd.read_csv('E:/Jupyter workspace/python_for_data_science/Data/customers.csv')
df.head()
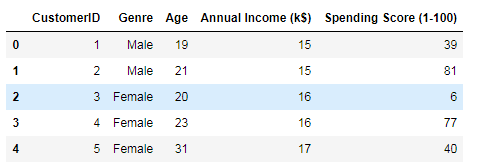
#只选取两个特征
#dataframe转矩阵
X=df.iloc[:,[3,4]].values
建模并绘图
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=5,init='k-means++',random_state=42)#k-means++初始点选择方法
y_kmeans=kmeans.fit_predict(X)
colors=['red','blue', 'green','cyan','magenta']
pain(y_kmeans,5,colors,kmeans)

三、密度为基础聚类法DBSCAN
eps:Density密度。以数据点为圆心所设的半径长度
核心点
边界点
噪音点:既不属于核心点也不属于边界点
密度相连:两个核心点互为边界点,则可把两个核心点合并在同一群组中
特点:
与Kmeans相比,不需要先知道K,可以找到任意形状,能够识别出噪声点,对于数据库中样本的顺序不敏感。
不适合高纬数据,不适合反映已变化数据的密度
##PIL图像处理模块
import numpy as np
from PIL import Image
img=Image.open('E:/Jupyter workspace/python_for_data_science/Data/handwriting.png')
#转化成像素图像
img2=img.convert('L')
#转化成数据--255白;0黑,每个数据代表图像对应位置像素点是否有颜色
imgarr=np.array(img2)
#二值化后(0-1),筛选出0黑点的位置
from sklearn.preprocessing import binarize
imgdata=np.where(binarize(imgarr,0)==0)
#返回两个数组,第一个数据是点在矩阵列方向第n行,第二个数组是点在矩阵的行方向的第m列,坐标(m,n)
#可视化
%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(imgdata[1],imgdata[0],s=100,c='red',label='culster1')
 构建二维矩阵
构建二维矩阵
X=np.column_stack([imgdata[1],imgdata[0]])#将两个数据河伯能成两列的矩阵
A.使用KMeans
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=2,init='k-means++',random_state=42)
y_kmeans=kmeans.fit_predict(X)
plt.scatter(X[y_kmeans==0,0],X[y_kmeans==0,1],s=100,c='red',label='Cluster 1')
plt.scatter(X[y_kmeans==1,0],X[y_kmeans==1,1],s=100,c='green',label='Cluster 1')
centers=kmeans.cluster_centers_
plt.scatter(centers[:,0],centers[:,1],s=100,c='yellow',label='Centers')
plt.show()

B.使用DBSCAN
from sklearn.cluster import DBSCAN
dbs=DBSCAN(eps=1,min_samples=3)
y_dbs=dbs.fit_predict(X)
plt.scatter(X[y_dbs==0,0],X[y_dbs==0,1],s=100,c='red',label='Cluster 1')
plt.scatter(X[y_dbs==1,0],X[y_dbs==1,1],s=100,c='green',label='Cluster 1')
plt.show()
 这个例子表明以中心点分群的kmeans模型对一些实际应用中不很适用
这个例子表明以中心点分群的kmeans模型对一些实际应用中不很适用
四、聚类结果评估
1.找到合适的wcss:kmeans.inertia_
import pandas as pd
df=pd.read_csv('E:/Jupyter workspace/python_for_data_science/Data/customers.csv')
X=df.iloc[:,[3,4]].values
wcss=[]
for i in range(1,11):
kmeans=KMeans(n_clusters=i,init='k-means++',random_state=42)#k-means++初始点选择方法
y_kmeans=kmeans.fit_predict(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1,11),wcss)
 通过观测拐点,作为合适的聚类分群数,图上约5处
通过观测拐点,作为合适的聚类分群数,图上约5处
2.Silhouse
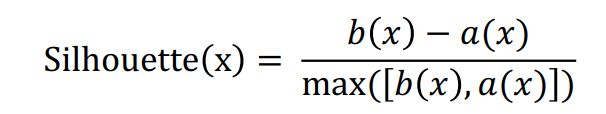 a(x)是x距离群内其它点的平均距离
a(x)是x距离群内其它点的平均距离
b(x)是x距离其它群内点之间的最小平均距离
1效果最好,0效果最差
from sklearn.metrics import silhouette_score
sils=[]
for i in range(2,11):
kmeans=KMeans(n_clusters=i,init='k-means++',random_state=42)#k-means++初始点选择方法
y_kmeans=kmeans.fit_predict(X)
sil=silhouette_score(X,y_kmeans)
sils.append(sil)
plt.plot(range(2,11),sils)
 5这个点的silhouette最接近1 ,效果最好
5这个点的silhouette最接近1 ,效果最好
五、模型比较
#层次聚类-沃德法
from sklearn.cluster import AgglomerativeClustering
ward =AgglomerativeClustering(n_clusters=5,affinity='euclidean',linkage='ward')
y_ward=ward.fit_predict(X)
#层次聚类-完整连接聚合法
from sklearn.cluster import AgglomerativeClustering
complete =AgglomerativeClustering(n_clusters=5,affinity='euclidean',linkage='complete')
y_complete=ward.fit_predict(X)
#kmeans
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=i,init='k-means++',random_state=42)
y_kmeans=kmeans.fit_predict(X)
for est, title in zip([y_ward,y_complete,y_kmeans],['ward','complete','kmeans']):
print(title,silhouette_score(X,est))

由结果知,kmeans方法稍好于其它两种
各种聚类模型适用:

六、案例-新闻主题聚类
从网上获取多篇新闻文章,将每篇文章使用结巴分词,建立词频矩阵,计算每篇文章形成的矩阵向量间的余弦相似度,以相似度分值进行聚类,将文章聚成若干类
1.抓取文章
参考
import pandas as pd
df=pd.read_excel('E:/Jupyter workspace/python_for_data_science/Data/news.xlsx')
df.head()

2.结巴分词
结巴分词简介
import jieba
#结巴分词简介
for ind,row in df[:5].iterrows():
print(row.title)
print('-----')

for ind,row in df[:5].iterrows():
print(' '.join(jieba.cut(row.title)))#用空格将列表(生成器)中的元素练成一整段字符串
print('-----')

每篇文章内容使用结巴分词
import jieba
articles=[]
titles=[]
for ind,row in df.iterrows():
articles.append(' '.join(jieba.cut(row.content)))#将空格见错开的文章一一投入列表
titles.append(row.title)#标题不需要分词
3.建立词频矩阵
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer()
X=vectorizer.fit_transform(articles)
X.shape
>>>(498, 16528)
每篇新闻按照所有分词建立的矩阵
df_word=pd.DataFrame(X.toarray(),columns=vectorizer.get_feature_names())
df_word.head()
 4.计算余弦相似度
4.计算余弦相似度
#X和X里的每条向量一一对比,计算两两之间的余弦相似度分值
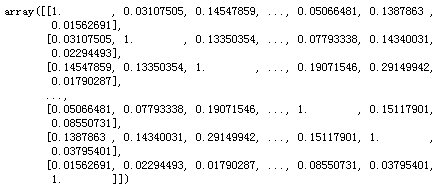
from sklearn.metrics.pairwise import cosine_similarity
cosm=cosine_similarity(X,X)
cosm.shape
>>>(498, 498)
cosm
5.使用kmeans聚类
##使用KMeans聚类
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=10,init='k-means++',random_state=123)
k_data=kmeans.fit_predict(cosm)
k_data.shape
>>>(498,)
k_data

这498篇文章已经被聚类完毕
6.查看某一类的所有文章对应的标题
#找到聚类编号为7 的标题
import numpy as np
titles_ary=np.array(titles)
titles_ary[k_data==7]
