两大FPGA巨头的“AI技术路线”分别讲解
两大FPGA巨头的“AI技术路线”分别讲解
近日Intel发布了Stratix 10 NX FPGA,标志着Intel公司在FPGA领域的人工智能“落地计划”。而去年Xilinx发布了ACAP后大家就一直等待着Intel的对应动作,Intel在时隔半年多以后也在于有了响应。
同样是利用FPGA来实现人工智能算法,两家的技术路线上有什么区别呢?今天我们就有限的资料来加以解读一下。
专注开发FPGA十五年
FPGA&芯片的定制开发、技术交流+V好:xinpianxiehui
目录
1.计算篇
2.访存篇
3.FPGA应用篇
- 计算篇
计算篇一句话总结就是:做FPGA起家的已经不在单纯的做FPGA,而做处理器起家的还是想继续好好的做FPGA。
上面这句话如何解释,我们首先来看看Xilinx的ACAP里面都有什么:
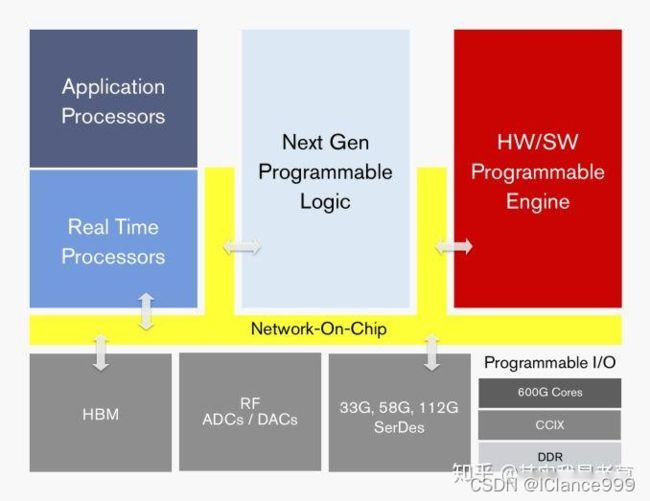
图1 Xilinx ACAP示意图
可以看到如今的ACAP早已经脱离了FPGA的范畴,除了中间那灰色的方块还是传统的FPGA那套东西以外,剩下的都是各种其它器件。甚至可以半开玩笑半认真的说,ACAP“主要是在做处理器”。除了左侧的应用处理器和实时处理器以外,右边的HW/SW Programanle Engine其实也是处理器。只不过是一直“众核处理器阵列”。
有图为证!
 图2 自适应数据流多核与传统多核的比较
图2 自适应数据流多核与传统多核的比较
把HW/SW Programanle Engine内部打开,其实是有很多“AI Core”组成的。这些AI Core采用的是自适应数据流的方式来组织多个核心。而Xilinx认为传统的多核是用层次化存储的方式来组织多个核心。当然这个不太全面,具体的可以阅读我以前写过的文章:

这些AI Core其实就是后面ACAP承载AI等数据密集型运算的主体,Core和Core之间一数据流的方式直连。包括相邻互联和长距离互联两种:
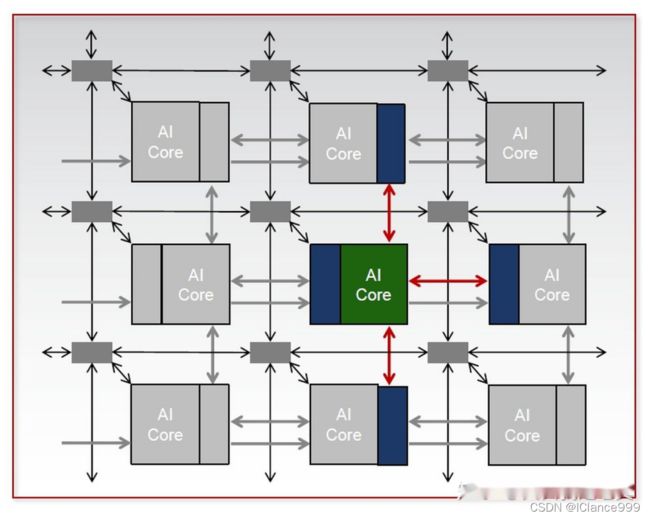
图3 AI Core的相邻互联方式,直接在旁边AI Core的Memory取数据 
图4 长距离AI互联,直接的点对点互联
这些互联方式组合就可以构成多种不同的互联方式,包括流水线、数据流图、广播等等。更多的细节就不再详细讨论了。总之,Xilinx的AI技术路线是做了一套专门的新的硬件体系来承载AI等新兴的数据密集型运算。
而Intel的思路完全不同,Intel应对AI计算的方式是“升级DSP模块”。


图5 Intel将DSP模块升级成为AI张量
我们知道,AI算法的核心就是大量的乘加/乘累加。再传统的FPGA中乘累加是依靠DSP模块实现的。为了追求较高的灵活性,普通的DSP模块就是一个或者两个乘法器,外加一个加法器构成。这样就可以基于这种基本的DSP模块配合FPGA的其它部分构成各种不同的运算算法。
但AI运算不是一般的乘加,而是一种“张量”运算。张量的概念大家可以具体去查询其它知乎上的回答和专栏。简单的说就是一组数据先乘后加,乘加之间还有级联。因此提升FPGA执行AI算法的最好方法自然就是把DSP模块升级为更加适应AI张量运算的模块。就是下面这张。

图6 AI张量运算模块内部结构
图6这张清晰度一般的图可以让我们简单的一窥AI张量运算模块的内部结构。可以看到是大量的乘法器,不同模块之间的级联通道,以及对应的加法。这非常符合张量运算先乘后加,多维运算的运算过程。这样让底层运算结构与算法高度匹配,就可以保证算法的执行效率。
综上所述,可以很清楚的明白:Xilinx的计算路线,是依靠独立的AI Core阵列,用类似于阵列处理器的方式来实现的。这种模式独立于传统的FPGA结构之外,是一个独立的硬件组成单元。而Intel则选择了将嵌入在FPGA内部的DSP模块直接升级乘了AI张量模块,依然是FPGA内部的组成模块之一。
2.访存篇
要高效的执行AI算法,让底层的运算器件更为符合算法特征只是做了一半,甚至只是一小半工作。局座张将军经常讲一句名言:“外行谈战略,内行谈后勤”(貌似已经沦为“公知”的袁老师也经常喜欢引用)。我这里也暂时借用一下:“外行看计算,内行看存储”。对于算法加速,很多时候取决于存储的数据能否及时的被“送”到运算单元中,从而能保证运算单元可以满负荷运转。在这里Xilinx和Intel也采取了不同的策略,Intel“求诸于外”而Xilinx“反求诸于内”。
先说Intel,因为比较容易理解。

图7 采用Chiplet形式的FPGA封装
图7给出了Stratix 10NX FPGA的封装结构,很显然的突出了Intel的Chiplet方案。依靠EMIB的接口方式,把HBM(High Bandwidth Memory)直接和FPGA内核连接在一起,从而形成了一块较大容量的“近计算内存”。从而极大的提升了存储器到FPGA的访存延迟。简单、粗暴,但是有效。谁让Intel掌握了EMIB这样的前沿科技呢。
而Xilinx的ACAP中则祭出了另外一个“法宝”:片上网络(NoC)。

图8 采用NoC互联的ACAP内部
可以看到ACAP内部各个大的硬件结构之间是依靠NoC互联的,而在AI Core阵列的入口处依靠DMA可以通过NoC直接访问外部的DRAM。这是避免了低效的“可编程互联”结构,用片上网络的高带宽直接把数据送到AI Core阵列的入口,然后用流传输的方式直接送到AI Core内部的Memory来处理。这种方法是在优化芯片内部的传输能力。
值得一提的是,Altera比Xilinx更早的尝试在FPGA内部使用NoC来互联各个可编程模块。2014年我在KTH苦苦研究片上网络之时,读到多伦多大学发表的NoC-FPGA的论文。那论文里的配图风格和Altera的数据手册配图如出一辙。当时坐我旁边的一个哥们儿(华人,复旦大学本硕毕业,KTH去读的博士)去Xilinx实习以后回来谈到这个问题,说Xilinx保守,对于FPGA中嵌入NoC比较保留。然而时过境迁,没想到今天的Intel FPGA中仍然没有看到对于硬核实现的NoC的介绍(软核的早已实现),但在Xilinx的ACAP中是明确的看到了。
综上所述,Intel FPGA依靠着自家已经高度成熟的EMIB技术,走Chiplet的道路,优化存储器到FPGA之间的Die-2-Die传输效率。而Xilinx则通过NoC来优化片内传输效率,减少数据在芯片内部的传输时间。
以上是本人根据接触到的资料对于Xilinx和Intel的FPGA实现AI运算的技术路线的一点解读。由于水平和资料都有限,难免出现纰漏,如果有更多消息的知友们可以补充。如果觉得留言不过瘾的,可以开个贴专门再讲。
最后的最后,在啰唆几句纯粹是猜测的话。Xilinx和Intel之所以出现这两种不同的技术路线,很大程度是取决于他们背后的技术储备和对于FPGA的定位。对于Intel而言,它旗下有CPU、GPU(开发中)、Movidius VPU、FPGA等多种面向不同场景的人工智能计算平台。所以在Intel这里,“FPGA就是FPGA”,只不过是一种实现AI算法的途径而已。而在Xilinx这里,FPGA就是它的全部。为了适应更大的市场,Xilinx需要“FPGA不止是FPGA”。所以就诞生了ACAP这样“超越了FPGA”的新型器件。
最后一段话纯粹是个人胡诌,再次声明,各位就当看个乐。
FPGA&芯片的定制开发、技术交流+V好:xinpianxiehui

3.FPGA应用AI工作篇
FPGA自诞生起一直在高速复杂计算领域里占有极大的优势,借助于计算机辅助设计工具通过Verilog编程,设计者可以很方便地将一个通用结构的FPGA芯片构造成一个规模宏大的并行的计算结构,这个结构能以通用CPU无法比拟的高速进行极其复杂的数据处理。然而,FPGA作为一种硬件可重构的体系结构,在过去的很长一段时间内都被用作ASIC的小批量替代品。
在有实用价值的图像分析、语音理解等模式识别的处理计算中,通常需要在几个毫秒之内对一幅图像的所有像素逐点进行卷积计算,分析、比较计算结果,得到可靠的结论。算法研究工作者通常用普通计算机的软件来处理静态数据,得到理论结果,但实际应用中如此慢的响应速度根本无法满足实际工程的需求。最近二十多年来,图像分析、语音理解等模式识别研究的算法理论研究已逐步成熟,引起了工业界的兴趣,大量的研究经费转向如何设计可以高速进行复杂数据处理的并行计算机结构,并研发实用的AI系统。因此近二十多年来,FPGA芯片和Verilog设计/验证方法得到了飞速的发展。
在图像处理方面,如人脸识别、指纹识别、语音识别方面的机器人,其AI表现也十分抢眼。 在这一类机器人的计算系统中许多极其复杂的计算工作,绝大部分都是由FPGA结构实现的。而且FPGA可以与各种不同的存储器、各种不同类型的并行接口或是计算机接口,如PCIe等方便地连接,它也可以把机器人与计算机网络和广大的知识库融为一体,构成极其庞大、响应迅速的AI知识系统。
根我所知,许多AI研究工作者习惯于用软件进行算法研究,他们中的大多数人用静态的图像或静态的声音(录下来的声音)做语音理解或者翻译方面的工作。在整个过程中,虽然数据处理的计算速度比较慢,但还是可以得到可靠的分析处理结果。但是在实际工程应用当中,这样慢的处理速度显然没有多大实用价值,因为在许多场合,响应根本无法用于实际场合。随着研究工作向设计实际系统转换,我建议软件系统的工程师们应该学会如何使用FPGA,以及如何用FPGA做复杂计算的加速。其实对计算机科学和工程专业毕业的软件工程师而言,只要有数字电路的基础知识,学习Verilog HDL语言并不困难,学会RTL级别Verilog的编程来构造可综合的并行迭代计算结构并不困难,只需要花费一两个月就能上手。