SQL查询优化:详解SQL Server非聚集索引
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml
在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索引的表.但相比实际的表而言.非聚集索引中所存储的表的列数要窄很多,因为非聚集索引仅仅包含原表中非聚集索引的列和指向实际物理表的指针。
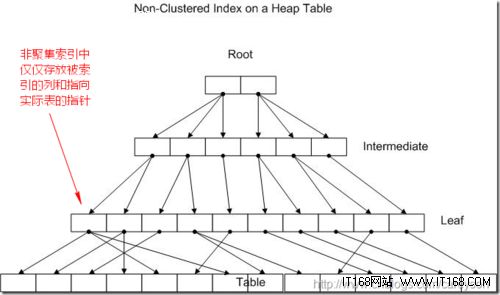
并且,对于非聚集索引表来说,其中所存放的列是按照聚集索引来进行存放的.所以查找速度要快了很多。但是对于性能的榨取来说,SQL SERVER总是竭尽所能,假如仅仅是通过索引就可以在B树的叶子节点获取所需数据,而不再用通过叶子节点上的指针去查找实际的物理表,那性能的提升将会 更胜一筹.
下面我们来看下实现这一点的几种方式.
非聚集索引的覆盖
正如前面简介所说。非聚集索引其实可以看作一个聚集索引表.当这个非聚集索引中包含了查询所需要的所有信息时,则查询不再需要去查询基本表,而仅仅是从非聚集索引就能得到数据:
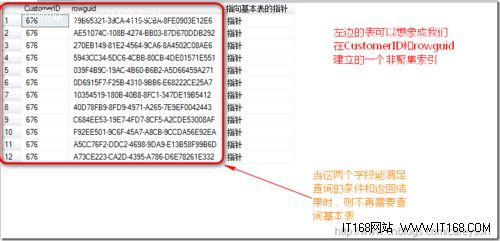
下面来看非聚集索引如何覆盖的:
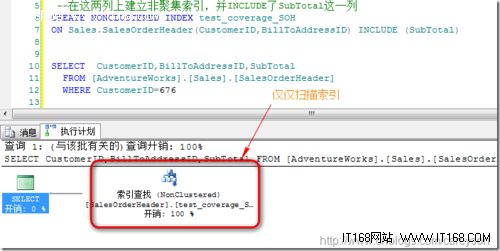
在adventureWorks的SalesOrderHeader表中,现在只有CustomerID列有非聚集索引,而BillToAddressID没有索引,我们的查询计划会是这样:
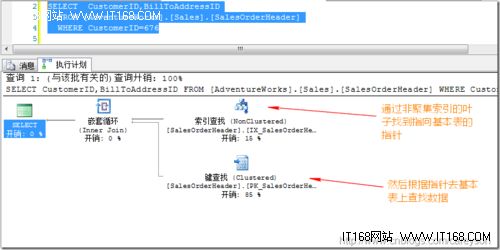
查询会根据CustomerID列上的非聚集索引找到相应的指针后,去基本表上查找数据.从执行计划可以想象,这个效率并不快。
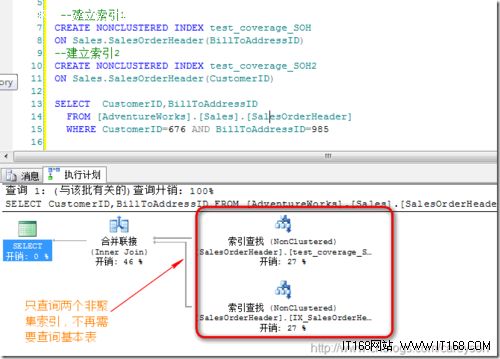
下面我们来看覆盖索引,通过在CustomerID和BillToAddressID上建立非聚集索引,我们覆盖到了上面查询语句的所有数据:
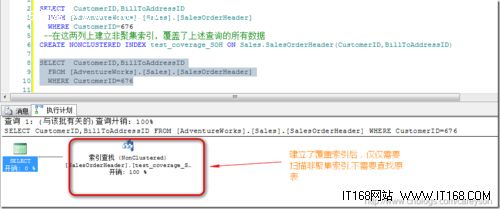
通过覆盖索引,可以看到执行计划简单到不能再简单,直接从非聚集索引的叶子节点提取到数据,无需再扫描基本表!
这个性能的提升可以从IO统计看出来,下面我们来看有覆盖索引和没有覆盖索引的IO对比:

索引的覆盖不仅仅带来的是效率的提升,还有并发的提升,因为减少了对基本表的依赖,所以提升了并发,从而减少了死锁!
理解INCLUDE的魔力
上面的索引覆盖所带来的效率提升就像魔术一样,但别着急,正如我通篇强调的一样,everything has price.如果一个索引包含了太多的键的话,也会带来很多副作用。INCLUDE的作用使得非聚集索引中可以包含更多的列,但不作为“键”使用。
比如:假设我们上面的那个查询需要增加一列,则原来建立的索引无法进行覆盖,从而还需要查找基本表:
但是如果要包含SubTotal这个总金额,则索引显得太宽,因为我们的业务很少根据订单价格作为查询条件,则使用INCLUDE建立索引:
理解INCLUDE包含的列和索引建立的列可以这样理解,把上述建立的含有INCLUDE的非聚集索引想像成:
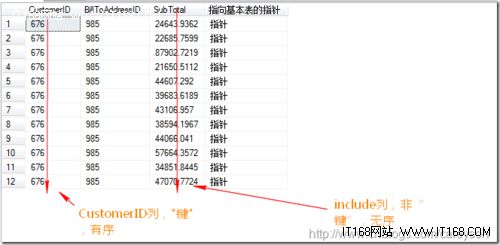
使用INCLUDE可以减少叶子“键”的大小!
非聚集索引的交叉
非聚集索引的交叉看以看作是覆盖索引的扩展!
由于很多原因,比如:
在生产环境中,我们往往不能像上面建立覆盖索引那样随意改动现有索引,这可能导致的结果是你会更频繁的被客户打电话“关照”
现有的非聚集索引已经很“宽”,你如果继续拓宽则增改查带来的性能下降的成本会高过提高查询带来的好处
这时候,你可以通过额外建立索引。正如我前面提到的,非聚集索引的本质是表,通过额外建立表使得几个非聚集索引之间进行像表一样的Join,从而使非聚集索引之间可以进行Join来在不访问基本表的情况下给查询优化器提供所需要的数据:
比如还是上面的那个例子.我们需要查取SalesOrderHeader表,通过BillToAddressID,CustomerID作为选择条件,可以通过建立两个索引进行覆盖,下面我们来看执行计划:
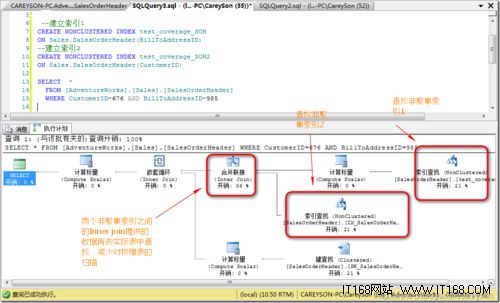
非聚集索引的连接
非聚集索引的连接实际上是非聚集索引的交叉的一种特例。使得多个非聚集索引交叉后可以覆盖所要查询的数据,从而使得从减少查询基本表变成了完全不用查询基本表:
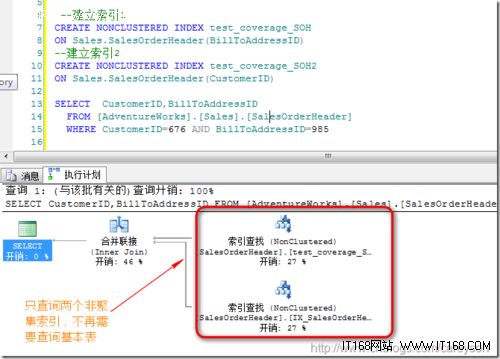
比如还是上面那两个索引,这时我只查询非聚集索引中包含的数据,则完全不再需要查询基本表:
看起来这样的查询意义不大?但当你把查询条件变为<号时呢?或者给定范围时。还是有一定实际意义的。
非聚集索引的过滤
很多时候,我们并不需要将基本表中索引列的所有数据全部索引,比如说含有NULL的值不希望被索引,或者根据具体的业务场景,有一些数据我们不想索引。这样可以:
减少索引的大小
索引减少了,从而使得对索引的查询得到了加速
小索引对于增删改的维护性能会更高
比如说,如下语句:
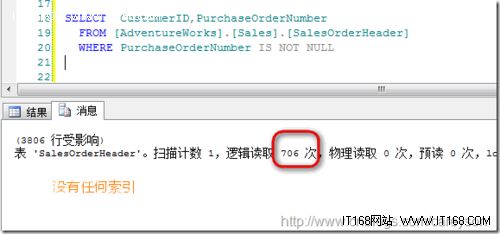
我们为其建立聚集索引后:
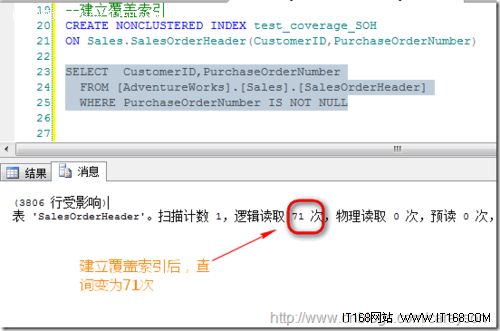
这时我们为其加上过滤条件,形成过滤索引:
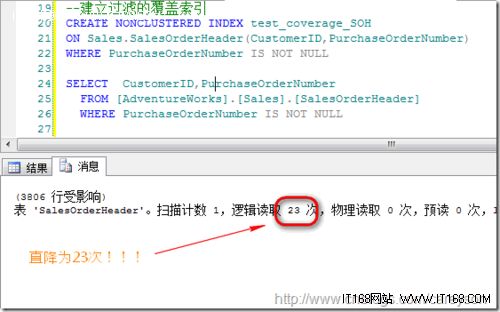
由上面我们可以看出,使用过滤索引的场景要和具体的业务场景相关,对于为大量相同的查询条件建立过滤索引使得性能进一步提升!
总结
本文从介绍了SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤。对于我们每一点从SQL SERVER榨取的性能的提升往往会伴随着另一方面的牺牲。作为数据库的开发人员或者管理人员来说,以全面的知识来做好权衡将会是非常重要.系统的学习数 据库的知识不但能大量减少逻辑读的数据,也能减少客户打电话"关照”的次数:-)