MySQL数据库四:MySQL数据库
一、主从模式
MySQL主从模式是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。
mysql主从复制用途:
- 实时灾备,用于故障切换(高可用)
- 读写分离,提供查询服务(读扩展)
- 数据备份,避免影响业务(高可用)
主从部署必要条件:
- 从库服务器能连通主库
- 主库开启binlog日志(设置log-bin参数)
- 主从server-id不同
1. 主从复制
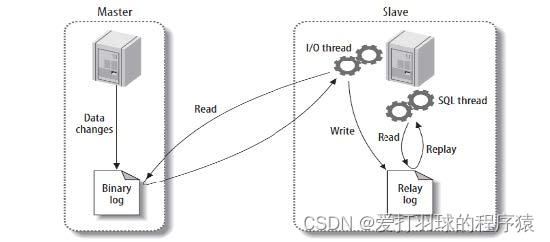
- Master服务器对数据库更改操作记录在Binlog中,BinlogDump Thread接到写入请求后,读取Binlog信息推送给Slave的I/O Thread
- Slave的I/O Thread将读取到的Binlog信息写入到本地Relay Log中
- Slave的SQL Thread检测到Relay Log的变更请求,解析relay log中内容在从库上执行
上述过程都是异步操作,俗称异步复制,存在数据延迟现象。
mysql主从复制存在的问题:
- 主库宕机后,数据可能丢失
- 从库只有一个SQL Thread,主库写压力大,复制很可能延时
解决方法:
- 半同步复制—解决数据丢失的问题
- 并行复制----解决从库复制延迟的问题
2. 半同步复制
为了提升数据安全,MySQL让Master在某一个时间点等待Slave节点的 ACK(Acknowledgecharacter)消息,接收到ACK消息后才进行事务提交,这也是半同步复制的基础。
主库等待从库写入 relay log 并返回 ACK 后才进行Engine Commit。
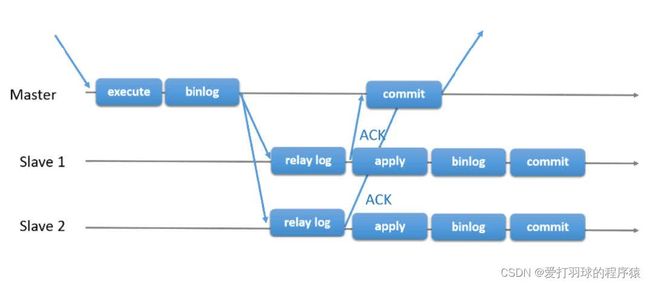
3. 并行复制
在从库中有两个线程IO Thread和SQL Thread,都是单线程模式工作。可以采用多线程机制来加强,减少从库复制延迟。(IO Thread多线程意义不大,主要指的是SQL Thread多线程)
在MySQL的5.6、5.7、8.0版本上,都是基于上述SQL Thread多线程思想,不断优化,减少复制延迟。
MySQL 5.6的并行复制
这里的并行复制是基于库的,如果用户的MySQL数据库中是多个库,对于从库复制的速度的确可以有比较大的帮助。
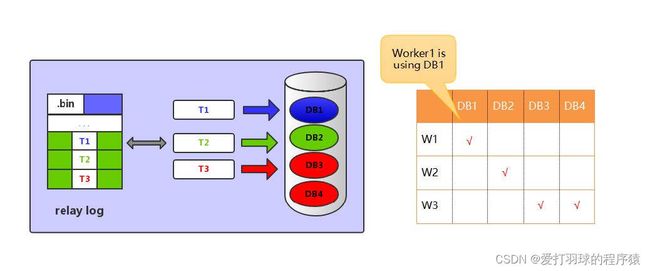
MySQL 5.7的并行复制
MySQL 5.7才可称为真正的并行复制,这其中最为主要的原因就是slave服务器的回放与master服务器是一致的,即master服务器上是怎么并行执行的slave上就怎样进行并行回放。不再有库的并行复制限制。
那么MySQL 5.7中组提交的并行复制究竟是如何实现的?
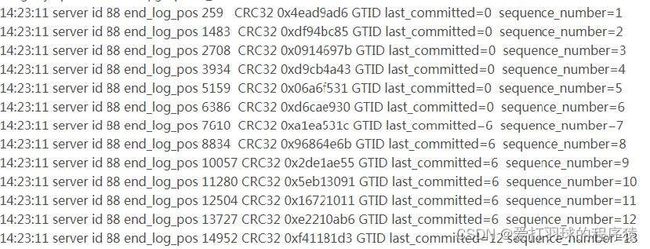
MySQL 5.7是通过对事务进行分组,当事务提交时,它们将在单个操作中写入到二进制日志中。如果多个事务能同时提交成功,那么它们意味着没有冲突,因此可以在Slave上并行执行,所以通过在主库上的二进制日志中添加组提交信息。
MySQL 5.7二进制日志较之原来的二进制日志内容多了last_committed和sequence_number,last_committed表示事务提交的时候,上次事务提交的编号,如果事务具有相同的last_committed,表示这些事务都在一组内,可以进行并行的回放。
以下是binlog中的内容:
MySQL8.0的并行复制
MySQL8.0 是基于write-set的并行复制。MySQL会有一个集合变量来存储事务修改的记录信息(主键哈希值),所有已经提交的事务所修改的主键值经过hash后都会与那个变量的集合进行对比,来判断改行是否与其冲突,并以此来确定依赖关系,没有冲突即可并行。这样的粒度,就到了 row级别了,此时并行的粒度更加精细,并行的速度会更快。
4. 读写分离
读写分离首先需要将数据库分为主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过主从复制机制进行数据的同步。

使用读写分离架构需要注意:主从同步延迟和读写分配机制问题
主从同步延迟
使用读写分离架构时,数据库主从同步具有延迟性,数据一致性会有影响,对于一些实时性要求比较高的操作,可以采用以下解决方案:
- 写后立刻读:在写入数据库后,某个时间段内读操作就去主库,之后读操作访问从库。
- 二次查询:先去从库读取数据,找不到时就去主库进行数据读取。该操作容易将读压力返还给主库,为了避免恶意攻击,建议对数据库访问API操作进行封装,有利于安全和低耦合。
- 根据业务特殊处理:实时性要求高的业务数据读写可以放在主库;对于次要的业务,实时性要求不高可以进行读写分离,查询时去从库查询。
读写分配
较为常见的实现方案分为以下两种:
- 基于编程和配置实现(应用端):程序员在代码中封装数据库的操作,代码中可以根据操作类型进行路由分配,增删改时操作主库,查询时操作从库
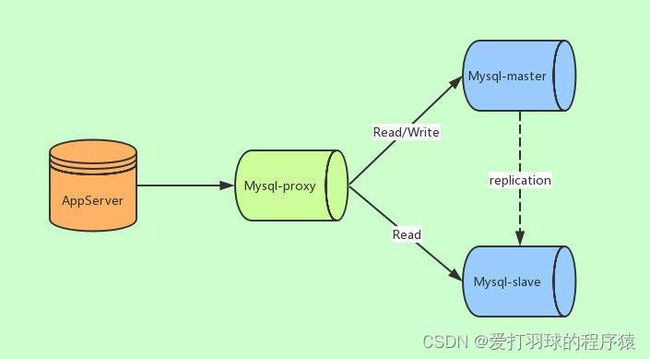
- 基于服务器端代理实现(服务器端):中间件代理一般介于应用服务器和数据库服务器之间,应用服务器并不直接进入到master数据库或者slave数据库,而是进入MySQL proxy代理服务器。代理服务器接收到应用服务器的请求后,先进行判断然后转发到后端master和slave数据库。常用的中间件代理有MySQL Proxy、MyCat以及Shardingsphere
二、双主模式
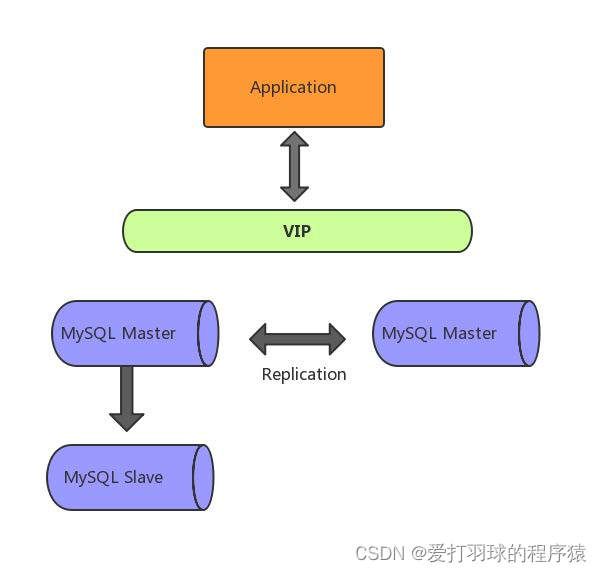
双主模式是指两台服务器互为主从,任何一台服务器数据变更,都会通过复制应用到另外一方的数据库
双主双写还是双主单写?
- 建议使用双主单写
- 双主双写存在以下问题
- ID冲突:在A主库写入,当A数据未同步到B主库时,对B主库写入,如果采用自动递增容易发生ID主键的冲突。
- 更新丢失:同一条记录在两个主库中进行更新,会发生前面覆盖后面的更新丢失
高可用架构如下图所示,其中一个Master提供线上服务,另一个Master作为备胎供高可用切换,Master下游挂载Slave承担读请求。
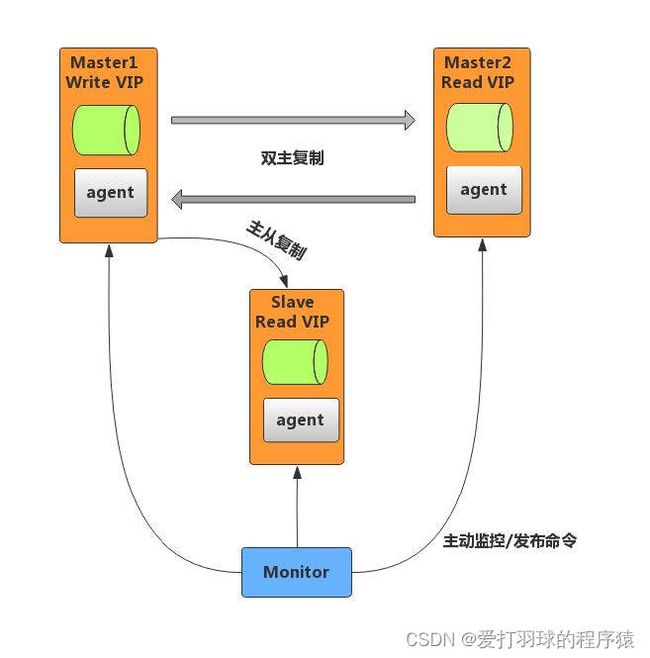
1. MMM架构
MMM(Master-Master Replication Manager for MySQL)是一套用来管理和监控双主复制,支持双主故障切换 的第三方软件。MMM 使用Perl语言开发,虽然是双主架构,但是业务上同一时间只允许一个节点进行写入操作。
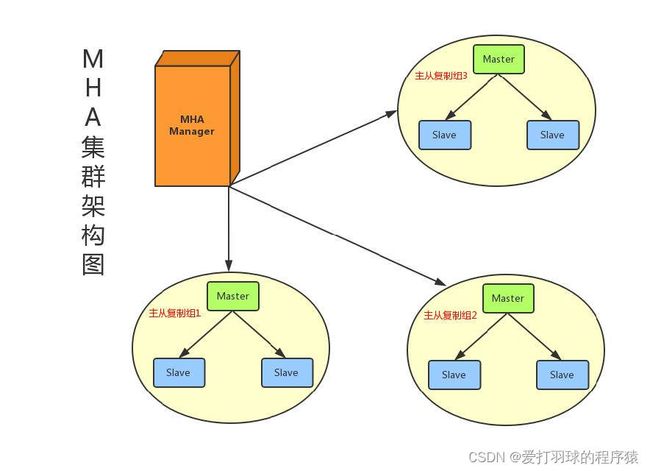
2. MHA架构
MHA(Master High Availability)是一套比较成熟的 MySQL 高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA还支持在线快速将Master切换到其他主机,通常只需0.5-2秒。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。
4. 主备切换
主备切换是指将备库变为主库,主库变为备库,有可靠性优先和可用性优先两种策略:
- 可靠性优先:主备切换过程一般由专门的HA高可用组件完成,但是切换过程中会存在短时间不可用,因为在切换过程中某一时刻主库A和从库B都处于只读状态
- 可用性优先:不等主从同步完成, 直接把业务请求切换至从库B ,并且让 从库B可读写 ,这样几乎不存在不可用时间,但可能会数据不一
三、分库分表
1. 拆分方式
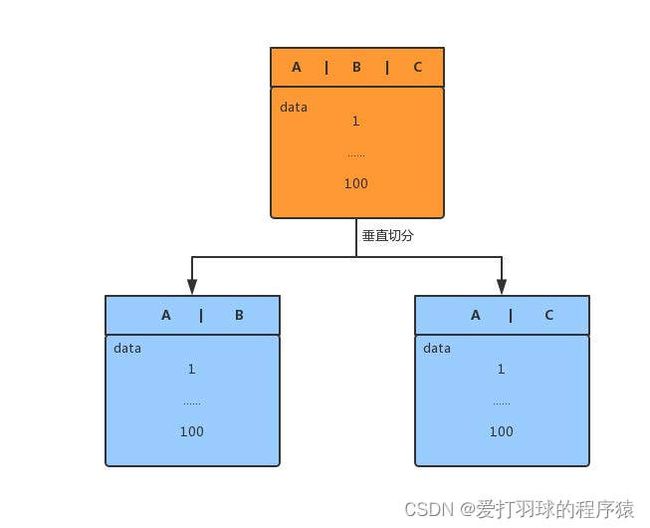
a. 垂直拆分
垂直分库:将表按库进行分离,如:将用户表和订单表拆分到不同的数据库中。
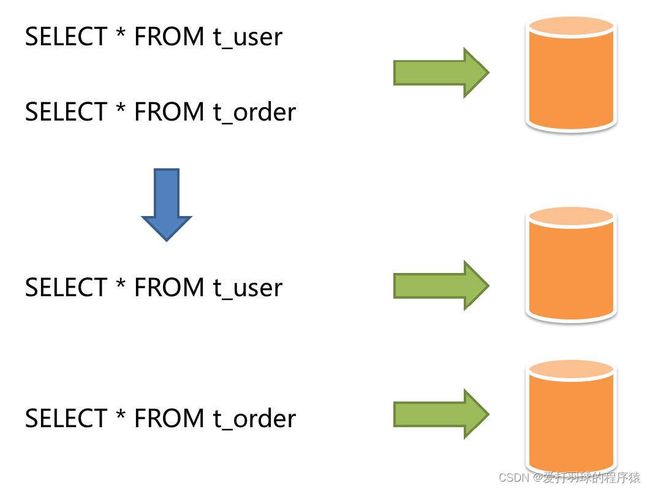
垂直分表:是将一张表中不常用的字段拆分到另一张表中,从而保证第一张表中的字段较少,避免出现数据库跨页存储的问题,从而提升查询效率
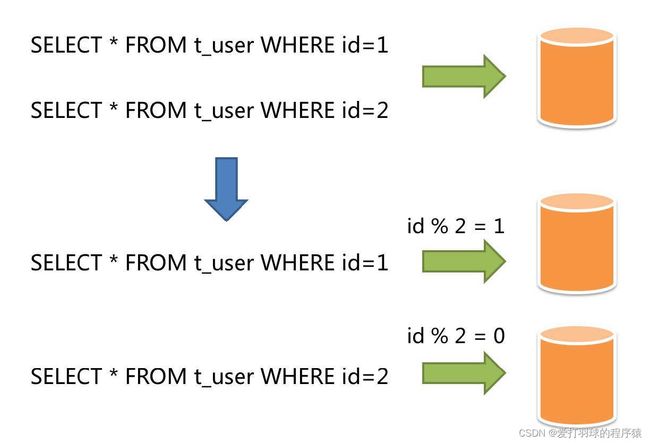
b. 水平拆分
通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个表仅包含数据的一部分。
2. 主键策略
在分库分表的环境中,数据分布在不同的数据表中,不能再借助数据库自增长特性直接生成,否则会造成不同数据表主键重复
常见的几种ID生成算法有:
- UUID
- UUID是通用唯一识别码(Universally Unique Identifier)的缩写,长度是16个字节,被表示为32个十六进制数字,以“ - ”分隔的五组来显示,格式为8-4-4-4-12,共36个字符,例如:550e8400-e29b-41d4-a716-446655440000。UUID在生成时使用到了以太网卡地址、纳秒级时间、芯片ID码和随机数等信息,目的是让分布式系统中的所有元素都能有唯一的识别信息。
- SNOWFLAKE
- SnowFlake是Twitter开源的分布式ID生成算法,结果是一个long型的ID,long型是8个字节,64-bit。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号,最后还有一个符号位,永远是0。SnowFlake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID重复,并且效率较高。
- 数据库ID表
- 单独的创建一个MySQL数据库,在这个数据库中创建一张表,这张表的ID设置为自动递增,其他地方需要全局唯一ID的时候,就先向这个这张表中模拟插入一条记录,此时ID就会自动递增
- Redis生成ID
- 这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。也可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都
3. 分片策略
分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。
分片策略是指分片的规则,常用规则有以下几种:
- 基于范围分片:根据特定字段的范围进行拆分。如:{[1 - 100] => Cluster A, [101 - 199] => Cluster B}
- 哈希取模分片:整型的Key可直接对设备数量取模,其他类型的字段可以先计算Key的哈希值,然后再对设备数量取模
- 一致性哈希分片:一致性Hash是将数据按照特征值映射到一个首尾相接的Hash环上,同时也将节点(按照IP地址或者机器名Hash)映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节
4. 扩容方案
常见的扩容方法有两种:
- 停机扩容
- 停止所有对外服务
- 新增n个数据库,然后写一个数据迁移程序,将原有x个库的数据导入到最新的y个库中。比如分片规则由%x变为%y;
- 数据迁移完成,修改数据库服务配置,原来x个库的配置升级为y个库的配置
- 重启服务,连接新库重新对外提供服务
- 万一数据迁移失败,需要将配置和数据回滚
- 平滑扩容:平滑扩容方案能够实现n库扩2n库的平滑扩容,增加数据库服务能力,降低单库一半的数据量。其核心原理是:成倍扩容,避免数据迁移。以新增两个数据库为例
- 新增2个数据库
- 配置双主进行数据同步(先测试、后上线)、
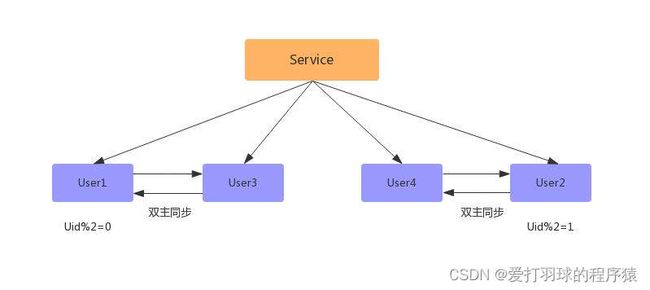
- 数据同步完成之后,配置双主双写(同步因为有延迟,如果时时刻刻都有写和更新操作,会存在不准确问题)
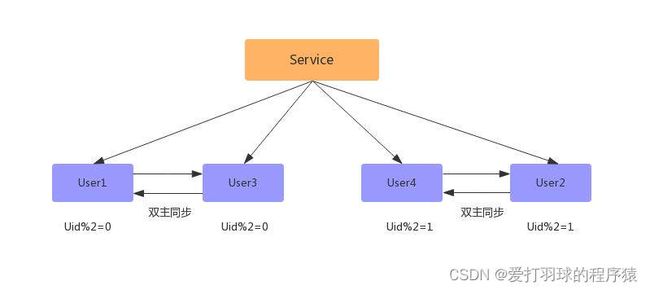
- 数据同步完成后,删除双主同步,修改数据库配置,并重启;
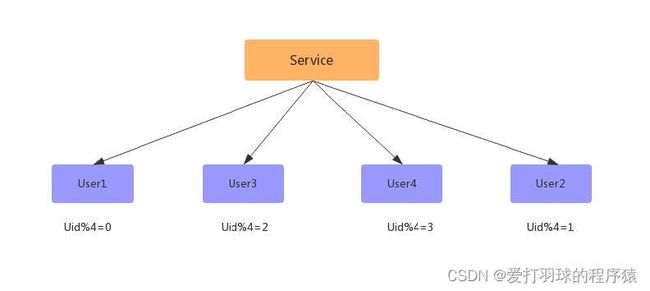
- 此时已经扩容完成,但此时的数据并没有减少,新增的数据库跟旧的数据库一样多的数据,此时还需要写一个程序,清空数据库中多余的数据