物联网IOT时序数据库influxdb(2.x)
物联网IOT时序数据库influxdb
- 物联网IOT时序数据库influxdb(2.x)
-
- 1.简介
- 2.InfluxDB相关概念
- 3.InfluxDB安装
-
- 3.1 本地安装
- 3.2 docker容器方式
- 4.设置 InfluxDB
- 5.常用操作
物联网IOT时序数据库influxdb(2.x)
1.简介
InfluxDB是开源时序型数据库,由Go写成,不过可惜的是开源的只有单机版,InfluxDB在集群方面闭源收费了,想大规模应用请引起注意。时序数据库经常应用于机房运维监控、物联网IoT设备采集存储、互联网广告点击分析等基于时间线且多源数据连续涌入数据平台的应用场景,InfluxDB专为时序存储而生,尤其是在工业领域的智能制造。由清华大学开源的IOTDB也是一款面向物联网的时序数据库,现在是apache旗下的顶级项目,未来潜力无限。
InfluxDB在DB-Engines的时序数据库类别里排名世界第一,国内的TDengine排名第14,Apache IotDB目前排名第20。

2.InfluxDB相关概念
- Database:InfluxDB可以创建数据库,一个数据库可以包含多个user、保存策略、schemaless ,支持随时灵活创建mersurement
- Measurement:相当于表的概念;
- Tags:是一些kv的结构,标签会被用来建立索引;
- Fields:是保存真实数据的结构,也是kv结构,但是不会被用来建立索引;
- Point: 代表了一条记录,可以理解为关系型数据库中的一条记录;
- Timestamp:既然InfluxDB被称之为时序数据库,少了时间是不可能的,每条记录必须要有一个时间戳;
- Series:是由Measurement+Tags组成的
3.InfluxDB安装
3.1 本地安装
添加yum源
cat <<EOF | tee etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL \$releasever
baseurl = https://repos.influxdata.com/rhel/\$releasever/\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF
安装 Telegraf Influxdb
yum -y install telegraf influxdb
启动软件
systemctl start influxdb
systemctl start telegraf
3.2 docker容器方式
官方的安装文档:https://docs.influxdata.com/influxdb/v2.1/install/?t=Docker
创建一个新目录来存储数据,然后导航到该目录
mkdir -p /mysoft/influxdb/influxdb-docker-data-volume && cd $_
在主机文件系统上生成默认配置文件
docker run \
--rm influxdb:2.1.1 \
influxd print-config > config.yml
再重新启动InfluxDB 容器
docker run -p 8086:8086 --name influxdb2 \
-v $PWD/config.yml:/etc/influxdb2/config.yml \
-v $PWD:/var/lib/influxdb2 \
-d influxdb:2.1.1
4.设置 InfluxDB
运行成功后,在浏览器登录:http://127.0.0.1:8086/
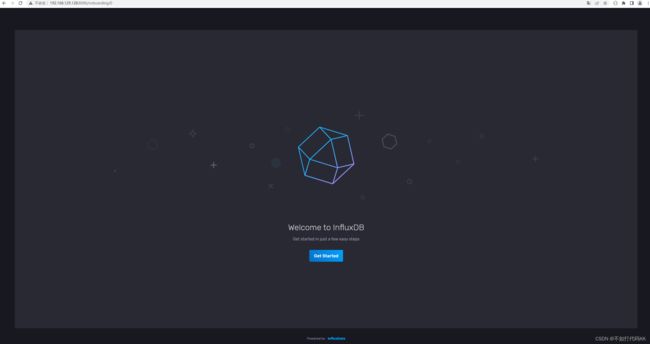
第一次登录,输入账号密码等初始化信息
-
organization(组织),简称org
organization 是一组用户的工作空间,一个组下用户可以创建多个bucket -
bucket(桶)
所有的 influxdb数据都存储在bucket中,bucket结合了数据库和保存期限(每条数据会被保留的时间)的概念,类似于RDMS的database的概念。bucket属于一个organization

当然也可以通过命令行的方式进行初始化
[influxdb]$ influx setup \> --username dbadmin \> --password mypna123 \> --host http://localhost:8086 \> --org userservice-org \> --bucket userredis-identity \> --retention 21900h \> --force

5.常用操作
查看所有用户
root@ce039e2603b8:/# influx user list
ID Name
09822514674b9000 dba
查看当前客户端配置
root@ce039e2603b8:/# influx config
Active Name URL Org
* default http://localhost:8086 brddmorg
root@ce039e2603b8:/#
查询所有的bucket
root@ce039e2603b8:/# influx bucket list -o brddmorg
ID Name Retention Shard group duration Organization ID Schema Type
efc7ed5f1b8651ae _monitoring 168h0m0s 24h0m0s ade0829bb3f73d60 implicit
9d4179049d56cb17 _tasks 72h0m0s 24h0m0s ade0829bb3f73d60 implicit
98fd2ef6dbae8047 bucketa infinite 168h0m0s ade0829bb3f73d60 implicit
新增bucket
root@ce039e2603b8:/# influx bucket create --name test
ID Name Retention Shard group duration Organization ID Schema Type
8704034ab5701f0a test infinite 168h0m0s ade0829bb3f73d60 implicit
root@ce039e2603b8:/#
数据写入
#数据内容
myMeasurement,tag1=value1,tag2=value2 fieldKey="fieldValue"
influx write \
-b test \
-o brddmorg \
-p ns \
'myMeasurement,tag1=influx-cli,tag2=influx-cli fieldKey="influx-cli"'
数据查询
InfluxDB2.x新增了语法查询数据:Flux,InfluxDB1.x只支持InfluxQL。
Flux是一种功能性数据脚本语言,旨在将查询、处理、分析和对数据的操作统一为一个语法。每个Flux查询需要以下步骤:
1、数据源;
2、时间范围;
3、数据过滤器。
root@ce039e2603b8:/# influx query
from(bucket: "test")
|> range(start: -15m)
|> yield(name: "results")
root@ce039e2603b8:/# influx query
from(bucket:"test")
|> range(start: -1d)
|> filter(fn: (r) => r.tag1== "influx-cli")
Result: _result
Table: keys: [_start, _stop, _field, _measurement, tag1, tag2]
_start:time _stop:time _field:string _measurement:string tag1:string tag2:string _time:time _value:string
------------------------------ ------------------------------ ---------------------- ---------------------- ---------------------- ---------------------- ------------------------------ ----------------------
2022-06-12T14:16:10.054365576Z 2022-06-13T14:16:10.054365576Z fieldKey myMeasurement influx-cli influx-cli 2022-06-13T13:50:59.393464863Z influx-cli
root@ce039e2603b8:/#