机器学习(八)KNN,SVM,朴素贝叶斯,决策树与随机森林
机器学习(八)KNN,SVM,朴素贝叶斯,决策树与随机森林
参考:
https://zhuanlan.zhihu.com/p/61341071
1.KNN—K最近邻(K-Nearest Neighbor)
KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学习算法),但却是有本质区别的.
KNN的全称是K Nearest Neighbors,意思是K个最近的邻居,从这个名字我们就能看出一些KNN算法的蛛丝马迹了。K个最近邻居,毫无疑问,K的取值肯定是至关重要的。那么最近的邻居又是怎么回事呢?其实啊,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。听起来有点绕,还是看看图吧。
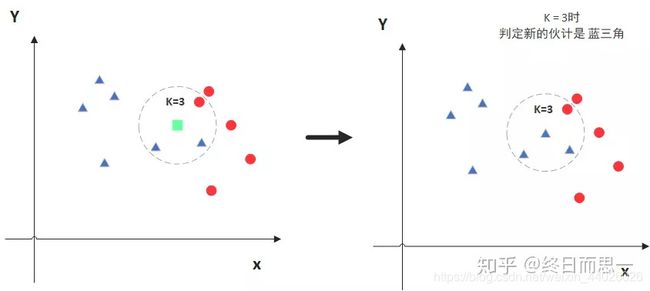
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。

但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,拿二维平面为例,,二维空间两个点的欧式距离计算公式如下:
ρ = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 \rho =\sqrt{\left( x_2-x_1 \right) ^2+\left( y_2-y_1 \right) ^2} ρ=(x2−x1)2+(y2−y1)2
其实就是计算(x1,y1)和(x2,y2)的距离。拓展到多维空间,则公式变成这样:
d ( x , y ) = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 + . . . + ( x n − y n ) 2 = ∑ i = 1 n ( x i − y i ) 2 d\left( x,y \right) =\sqrt{\left( x_1-y_1 \right) ^2+\left( x_2-y_2 \right) ^2+...+\left( x_n-y_n \right) ^2}=\sqrt{\sum_{i=1}^n{\left( x_i-y_i \right) ^2}} d(x,y)=(x1−y1)2+(x2−y2)2+...+(xn−yn)2=i=1∑n(xi−yi)2
这样我们就明白了如何计算距离,KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。
from sklearn.neighbors import KNeighborsClassifier # 导入kNN算法
k = 5 # 设定初始K值为5
kNN = KNeighborsClassifier(n_neighbors = k) # kNN模型
kNN.fit(X_train, y_train) # 拟合kNN模型
y_pred = kNN.predict(X_test) # 预测心脏病结果
from sklearn.metrics import (accuracy_score, f1_score, average_precision_score, confusion_matrix) # 导入评估标准
print("{}NN 预测准确率: {:.2f}%".format(k, kNN.score(X_test, y_test)*100))
print("{}NN 预测F1分数: {:.2f}%".format(k, f1_score(y_test, y_pred)*100))
print('kNN 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

# 寻找最佳K值
f1_score_list = []
acc_score_list = []
for i in range(1,15):
kNN = KNeighborsClassifier(n_neighbors = i) # n_neighbors means k
kNN.fit(X_train, y_train)
acc_score_list.append(kNN.score(X_test, y_test))
y_pred = kNN.predict(X_test) # 预测心脏病结果
f1_score_list.append(f1_score(y_test, y_pred))
index = np.arange(1,15,1)
plt.plot(index,acc_score_list,c='blue',linestyle='solid')
plt.plot(index,f1_score_list,c='red',linestyle='dashed')
plt.legend(["Accuracy", "F1 Score"])
plt.xlabel("K value")
plt.ylabel("Score")
plt.grid('false')
plt.show()
kNN_acc = max(f1_score_list)*100
print("Maximum kNN Score is {:.2f}%".format(kNN_acc))

2.SVM支持向量机
参考视频:https://www.bilibili.com/video/BV1hy4y1p7e1?from=search&seid=7370557417302411583
参考资料:
https://www.zhihu.com/question/21094489/answer/86273196
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”

于是大侠这样放,干的不错?

然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
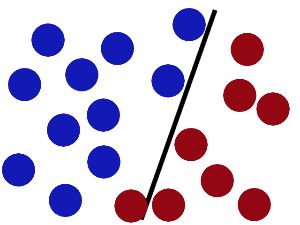
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。

现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。

然后,在SVM 工具箱中有另一个更加重要的 trick。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。

现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
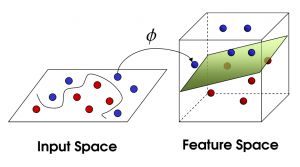
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。
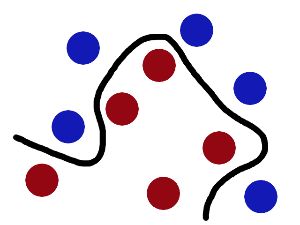
再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
SVM算法就是要在支持向量的帮助下,通过类似于梯度下降的优化方法,找到最优的分类超平面—具体目标就是令支持向量到超平面之间的垂直距离最宽,称位“最宽街道”。
这里我们引出线性可分的定义:如果一个线性函数能够将样本分开,就称这些样本是线性可分的。线性函数在一维空间里,就是一个小小的点;在二维可视化图像中,是一条直直的线;在三维空间中,是一个平平的面;在更高维的空间中,是无法直观用图形展示的超平面。
回想一下线性回归,在一元线性回归中我们要找拟合一条直线,使得样本点(x,y)都落在直线附近;在二元线性回归中,要拟合一个平面,使得样本点(x1,x2,y)都落在该平面附近;在更高维的情况下,就是拟合超平面。
那么,线性分类(此处仅指二分类)呢?当样本点为(x,y)时(注意,和回归不同,由于y是分类标签,y的数字表示是只有属性含义,是没有真正的数值意义的,因此当只有一个自变量时,不是二维问题而是一维问题),要找到一个点wx+b=0,即x=-b/w这个点,使得该点左边的是一类,右边的是另一类。
当样本点为(x1,x2, y)时,要找到一条直线 w 1 x 1 + w 2 x 2 + b = 0 w_1x_1+w_2x_2+b=0 w1x1+w2x2+b=0
,将平面划分成两块,使得 w 1 x 1 + w 2 x 2 + b > 0 w_1x_1+w_2x_2+b>0 w1x1+w2x2+b>0 的区域是y=1类的点, w 1 x 1 + w 2 x 2 + b < 0 w_1x_1+w_2x_2+b<0 w1x1+w2x2+b<0的区域是y=-1类别的点。
更高维度以此类推,由于更高维度的的超平面要写成 w 1 x 1 + w 2 x 2 + . . . + w p x p + b = 0 w_1x_1+w_2x_2+...+w_px_p+b=0 w1x1+w2x2+...+wpxp+b=0 ,会有点麻烦,一般会用矩阵表达式代替,即上面的 W T X + b = 0 W^TX+b=0 WTX+b=0。
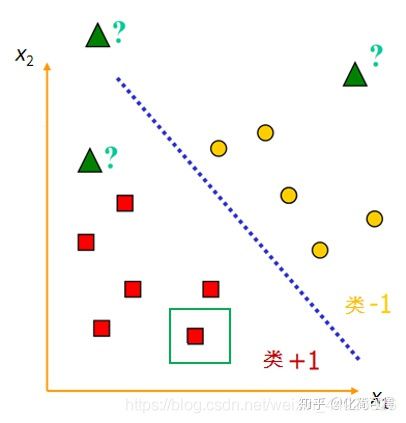
W T X + b = 0 W^TX+b=0 WTX+b=0这个式子中,X不是二维坐标系中的横轴,而是样本的向量表示。例如上面举的二维平面中的例子,假设绿色框内是的坐标是(3,1),则 X T = ( x 1 , x 2 ) = ( 3 , 1 ) X^T=\left( x_1,x_2 \right) =\left( 3,1 \right) XT=(x1,x2)=(3,1) 。一般说向量都默认是列向量,因此以行向量形式来表示时,就加上转置。因此, W T X + b = 0 W^TX+b=0 WTX+b=0 中 W T W^T WT是一组行向量,是未知参数,X是一组列向量,是已知的样本数据,可以将 w i w_i wi 理解为 x i x_i xi 的系数,行向量与列向量相乘得到一个1*1的矩阵,也就是一个实数。
我们还是先看只有两个自变量的情况下,怎么求解最佳的线性分割。

如图,理想状态下,平面中的两类点是完全线性可分的。这时问题来了,这样能把两类点分割的线有很多啊,哪条是最好的呢?
支持向量机中,对最好分类器的定义是:最大边界超平面,即距两个类别的边界观测点最远的超平面。在二维情况下,就是找最宽的马路,在三维问题中,就是找最厚的木板。

显然,上图中左边的马路比右边的宽,马路的边界由1、2、3这三个点确定,而马路中间那条虚线,就是我们要的 W T X + b = 0 W^TX+b=0 WTX+b=0。
可以看到,我们找马路时,只会考虑+1类中,离-1类近的点,还有-1类中,离+1类距离近的点,即图中的1、2、3和a、b、c这些点。其他距离对方远的样本点,我们做支持向量机这个模型时,是不考虑的。
由于最大边界超平面仅取决于两类别的边界点,这些点被称为支持向量,因此这种算法被命名为支持向量机。
from sklearn.svm import SVC # 导入SVM分类器
svm = SVC(random_state = 1)
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test) # 预测心脏病结果
svm_acc = svm.score(X_test,y_test)*100
print("SVM 预测准确率:: {:.2f}%".format(svm.score(X_test,y_test)*100))
print("SVM 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('SVM 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

3.朴素贝叶斯(Naive Bayes)
参考:
https://zhuanlan.zhihu.com/p/79779026
贝叶斯分类是一类分类算法的总称,这类算法均以“贝叶斯定理”为基础,以“特征条件独立假设”为前提。而朴素贝叶斯分类是贝叶斯分类中最常见的一种分类方法,同时它也是最经典的机器学习算法之一。在很多场景下处理问题直接又高效,因此在很多领域有着广泛的应用,如垃圾邮件过滤、文本分类与拼写纠错等,同时对于产品经理来说没,贝叶斯分类法是一个很好的研究自然语言处理问题的切入点。
朴素贝叶斯分类是一种十分简单的分类算法,说它十分简单是因为它的解决思路非常简单。即对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
举个形象的例子,若我们走在街上看到一个黑皮肤的外国友人,让你来猜这位外国友人来自哪里。十有八九你会猜是从非洲来的,因为黑皮肤人种中非洲人的占比最多,虽然黑皮肤的外国人也有可能是美洲人或者是亚洲人。但是在没有其它可用信息帮助我们判断的情况下,我们会选择可能出现的概率最高的类别,这就是朴素贝叶斯的基本思想。
from sklearn.naive_bayes import GaussianNB # 导入朴素贝叶斯模型
nb = GaussianNB()
nb.fit(X_train, y_train)
y_pred = nb.predict(X_test) # 预测心脏病结果
nb_acc = nb.score(X_test,y_test)*100
print("NB 预测准确率:: {:.2f}%".format(svm.score(X_test,y_test)*100))
print("NB 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('NB 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

4.决策树
参考:
https://zhuanlan.zhihu.com/p/347594334
以分类任务为代表的决策树模型,是一种对样本特征构建不同分支的树形结构。
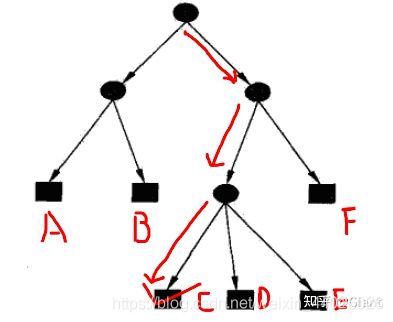
决策树由节点和有向边组成,其中节点包括内部节点(圆)和叶节点(方框)。内部节点表示一个特征或属性,叶节点表示一个具体类别。

预测时,从最顶端的根节点开始向下搜索,直到某一个叶子节点结束。下图的红线代表了一条搜索路线,决策树最终输出类别C。
4.1决策树的特征选择
假如有为青年张三想创业,但是摸摸口袋空空如也,只好去银行贷款。
银行会综合考量多个因素来决定是否给他放贷。例如,可以考虑的因素有性别、年龄、工作、是否有房、信用情况、婚姻状况等等。
这么多因素,哪些是重要的呢?
这就是特征选择的工作。特征选择可以判别出哪些特征最具有区分力度(例如“信用情况”),哪些特征可以忽略(例如“性别”)。特征选择是构造决策树的理论依据。
不同的特征选择,生成了不同的决策树。

假如有为青年张三想创业,但是摸摸口袋空空如也,只好去银行贷款。
银行会综合考量多个因素来决定是否给他放贷。例如,可以考虑的因素有性别、年龄、工作、是否有房、信用情况、婚姻状况等等。
这么多因素,哪些是重要的呢?
这就是特征选择的工作。特征选择可以判别出哪些特征最具有区分力度(例如“信用情况”),哪些特征可以忽略(例如“性别”)。特征选择是构造决策树的理论依据。
不同的特征选择,生成了不同的决策树。
4.1.1信息增益
在信息论中,熵表示随机变量不确定性的度量。假设随机变量X有有限个取值,取值 x i x_i xi 对应的概率为 p i p_i pi ,则X的熵定义为:
H ( X ) = − ∑ i = 1 n p i log p i H\left( X \right) =-\sum_{i=1}^n{p_i\log p_i} H(X)=−i=1∑npilogpi
如果某件事一定发生或一定不发生,则概率为1或0,对应的熵均为0。
如果某件事可能发生可能不发生(天要下雨,娘要嫁人),概率介于0到1之间,熵大于0。
由此可见,熵越大,随机性越大,结果越不确定。
我们再来看一看条件熵 H ( X ∣ Y ) H\left( X|Y \right) H(X∣Y),表示引入随机变量Y对于消除X不确定性的程度。假如X、Y相互独立,则X的条件熵和熵有相同的值;否则条件熵一定小于熵。
明确了这两个概念,理解信息增益就比较方便了。现在我们有一份数据集D(例如贷款信息登记表)和特征A(例如年龄),则A的信息增益就是D本身的熵与特征A给定条件下D的条件熵之差,即:
g ( D , A ) = H ( D ) − H ( D ∣ A ) g\left( D,A \right) =H\left( D \right) -H\left( D|A \right) g(D,A)=H(D)−H(D∣A)
数据集D的熵是一个常量。信息增益越大,表示条件熵 H ( D ∣ A ) H\left( D|A \right) H(D∣A) 越小,A消除D的不确定性的功劳越大。
所以要优先选择信息增益大的特征,它们具有更强的分类能力。由此生成决策树,称为ID3算法。
4.1.2信息增益率
当某个特征具有多种候选值时,信息增益容易偏大,造成误差。引入信息增益率可以校正这一问题。
信息增益率 g R g_R gR 为信息增益与数据集D的熵之比:
g R ( D , A ) = g ( D , A ) H ( D ) g_R\left( D,A \right) =\frac{g\left( D,A \right)}{H\left( D \right)} gR(D,A)=H(D)g(D,A)
同样,我们优先选择信息增益率最大的特征,由此生成决策树,称为C4.5算法。
4.1.3基尼指数
基尼指数是另一种衡量不确定性的指标。
假设数据集D有K个类,样本属于第K类的概率为 p k p_k pk ,则D的基尼指数定义为:
G i n i ( D ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini\left( D \right) =\sum_{k=1}^K{p_k\left( 1-p_k \right) =1-\sum_{k=1}^K{p_{k}^{2}}} Gini(D)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
其中 p k = ∣ C k ∣ ∣ D ∣ p_k=\frac{|C_k|}{|D|} pk=∣D∣∣Ck∣ , C k C_k Ck 是D中属于第k类的样本子集。
如果数据集D根据特征A是否取某一可能值a被分割成 D 1 D_1 D1和 D 2 D_2 D2 两部分,则在给定特征A的条件下,D的基尼指数为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini\left( D,A \right) =\frac{|D_1|}{|D|}Gini\left( D_1 \right) +\frac{|D_2|}{|D|}Gini\left( D_2 \right) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
容易证明基尼指数越大,样本的不确定性也越大,特征A的区分度越差。
我们优先选择基尼指数最小的特征,由此生成决策树,称为CART算法。
4.2决策树剪枝
决策树生成算法递归产生一棵决策树,直到结束划分。什么时候结束呢?
样本属于同一种类型
没有特征可以分割
这样得到的决策树往往对训练数据分类非常精准,但是对于未知数据表现比较差。
原因在于基于训练集构造的决策树过于复杂,产生过拟合。所以需要对决策树简化,砍掉多余的分支,提高泛化能力。
决策树剪枝一般有两种方法:
预剪枝:在树的生成过程中剪枝。基于贪心策略,可能造成局部最优
后剪枝:等树全部生成后剪枝。运算量较大,但是比较精准
决策树剪枝往往通过极小化决策树整体的损失函数实现。
CART算法
CART表示分类回归决策树,同样由特征选择、树的生成及剪枝组成,可以处理分类和回归任务。
相比之下,ID3和C4.5算法只能处理分类任务。
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,依次递归地二分每个特征。
CART 对回归树采用平方误差最小化准则,对分类树用基尼指数最小化准则。
4.3 bagging集成
机器学习算法中有两类典型的集成思想:bagging和bossting。
bagging是一种在原始数据集上,通过有放回抽样分别选出k个新数据集,来训练分类器的集成算法。分类器之间没有依赖关系。
随机森林属于bagging集成算法。通过组合多个弱分类器,集思广益,使得整体模型具有较高的精确度和泛化性能。
我们将使用CART决策树作为弱学习器的bagging方法称为随机森林。
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
dtc_acc = dtc.score(X_test, y_test)*100
y_pred = dtc.predict(X_test) # 预测心脏病结果
print("Decision Tree Test Accuracy {:.2f}%".format(dtc_acc))
print("决策树 预测准确率:: {:.2f}%".format(dtc.score(X_test, y_test)*100))
print("决策树 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('决策树 混淆矩阵:\n', confusion_matrix(y_pred, y_test))
5.随机森林
参考:
https://zhuanlan.zhihu.com/p/22097796
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。随机森林可以既可以处理属性为离散值的量,比如ID3算法,也可以处理属性为连续值的量,比如C4.5算法。另外,随机森林还可以用来进行无监督学习聚类和异常点检测。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
随机森林由决策树组成,决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,比如说下面的决策树(其属性的值都是连续的实数):
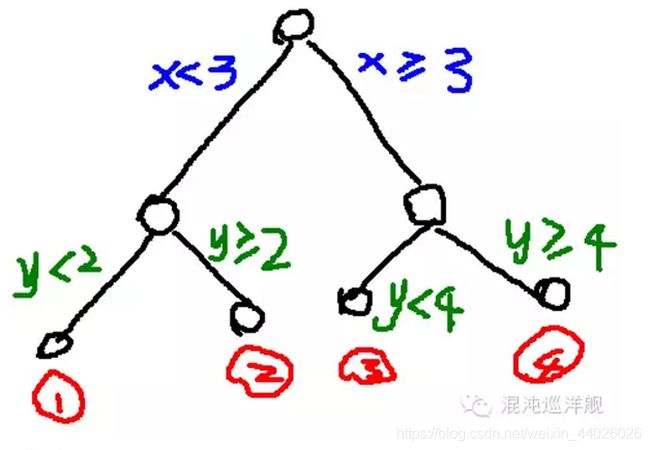
这一颗树将样本空间划分为成的样子为:

下面是随机森林的构造过程:
1. 假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
2. 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
3. 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
4. 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
rf = RandomForestClassifier(n_estimators = 1000, random_state = 1)
rf.fit(X_train, y_train)
rf_acc = rf.score(X_test,y_test)*100
y_pred = rf.predict(X_test) # 预测心脏病结果
print("随机森林 预测准确率:: {:.2f}%".format(rf.score(X_test, y_test)*100))
print("随机森林 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('随机森林 混淆矩阵:\n', confusion_matrix(y_pred, y_test))