【FaceBagNet】《FaceBagNet:Bag-of-local-features Model for Multi-modal Face Anti-spoofing》


CVPR-2019 workshop
code:https://github.com/SeuTao/CVPR19-Face-Anti-spoofing
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
-
- 4.1 The overall architecture
- 4.2 Patch-based features learning
- 4.3 Multi-stream fusion with MFE
- 5 Experiments
-
- 5.1 Datasets
- 5.2 Results
- 6 Conclusion(own)
1 Background and Motivation
face anti-spoofing(FAS) 在 face recognition systems 中很重要,传统方法(基于手动设计特征)和 CNN-based 的方法都取得了不错的效果,但是由于数据规模有限,算法的 generalization ability 略显不足!
最近 CASIA 开源了一个多模态多 subjects 的 FAS 数据集,叫 CASIA-SURF(现有规模最大),然后举办了个比赛
作者借鉴【BagNets】《Approximating cnns with bag-of-local-features models works surprisingly well on imagenet》,提出 FaceBagNet(patch-based features learning method),取得了比赛的第二名
2 Related Work
- traditional face anti-spoofing methods
- CNN-based face anti-spoofing methods
3 Advantages / Contributions
-
second place in CVPR 2019 ChaLearn Face Anti-spoofing attack detection
-
提出了 FaceBagNet(patch-based features learning method )with Modal Feature Erasing (MFE,A multi-stream fusion method ) 模块来进行 presentation attack detection——RGB / Depth / IR 三种模态同时输入
4 Method
4.1 The overall architecture

两个核心 components:
patch-based features learning
multi-stream fusion with MFE
网络的细节如 Table 1
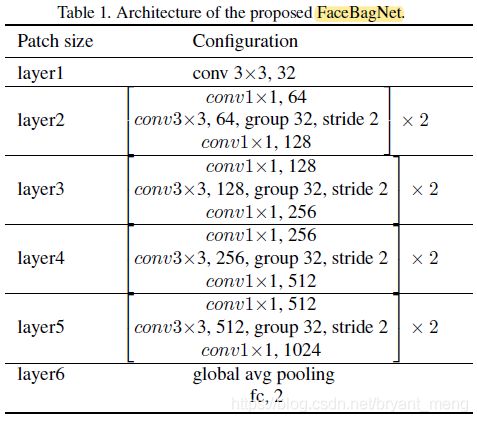
4.2 Patch-based features learning
用 patch 的理由为:
The spoof-specific discriminative information exists in the whole face area
4.3 Multi-stream fusion with MFE
在 【CASIA-SURF】《A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing》 论文中已表明,仅仅通过 concatenate 把三种模态提取出来的特征融合在一起,效果不够理想,CASIA-SURF 论文中,作者采用了 【SENet】《Squeeze-and-Excitation Networks》SE attention 模块来抑制不重要的特征

本文,作者采用类似 drop out 的方式,在训练的时候随机 erase 一种模态中的特征,如下图所示

5 Experiments
5.1 Datasets
CASIA-SURF

评价指标(具体含义可参考 【CASIA-SURF】《A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing》 )
- Attack Presentation Classification Error Rate(APCER)
- Normal Presentation Classification Error Rate(NPCER)
- Average Classification Error Rate(ACER)
- Receiver Operating Characteristic(ROC),以特定 FPR 下的 TPR 作为参考,没有计算 AUC
5.2 Results
输入大小为 112×112,patch 从 112 × 112 random extract
1)The Effect of Patch Sizes and Modality

作者的描述为 inference 36 times with 9 non-overlapping image patches and 4 flipped input
感觉跑了 36 次取平均值,9 non-overlap 感觉有点离谱,原图都 112 × 112 了,取 9 块出来还不重叠,应该把原图放大了? 或者说,non-overlap 中间插个单词进去,叫 non-完全-overlap,4 应该是上下左右都翻转
表 3 可以看出,patch size 为 32 的时候最好
2)The Effect of Modal Feature Erasing and Training strategy

w.o 是 without 的意思
CLR 表示 cyclic learning rate(余弦学习率,作用相当于在训练好的模型上再重新训练)
可以看到 CLR + MFE 的效果还是好
random erase 的效果比固定 erase 某种模态的好
3)Comparing with other teams in ChaLearn Face Antispoofing attack detection challenge

最终结果用的是 32 × 32,48 × 48,64 × 64 三种 patch 大小的 ensemble
FN 为 1,基本不会把 real 认为 fake!我们更关心的是 FP其实,这个太致命了
和第一名之间差距不大,第一名为这种方法 【FAS-FRN】《Recognizing Multi-modal Face Spoofing with Face Recognition Networks》
作者来了句,哈哈
6 Conclusion(own)
- Bag-of-local-features + multi-stream fusion with Modal Feature Erasing
- 看看 coding 中大的 patch 是怎么 non-overlap 取得